







前言
有时候我们需要将 xmind 编写的测试用例,导入禅道,便于管理,本文着重介绍导入的详细步骤,以及常见问题的处理。
1、工具准备
1.1、安装 python
python的安装就不多介绍了,python官方下载地址
1.2、安装 xmind2testcase
运行 cmd 打开命令提示符窗口,输入下面的安装命令:
1.安装命令:pip3 install xmind2testcase
2.升级版本:pip3 install -U xmind2testcase
2、适配禅道模板代码优化
在 python 安装路径下的 \Lib\site-packages\xmind2testcase文件夹下找到parser.py和 zentao.py文件,替换成以下文件,或根据下面步骤编辑两个文件(原来的文件转换出的csv文件,与前禅道模板有些不一致,需要修改)。
替换的文件下载,密码:csdn
2.1、parser.py 文件修改或替换
python安装路径的**\Lib\site-packages\xmind2testcase文件夹下找到parser.py**文件并打开,修改以下方法,去除用例标题中的空格:
def gen_testcase_title(topics):
"""Link all topic's title as testcase title"""
titles = [topic['title'] for topic in topics]
titles = filter_empty_or_ignore_element(titles)
# when separator is not blank, will add space around separator, e.g. '/' will be changed to ' / '
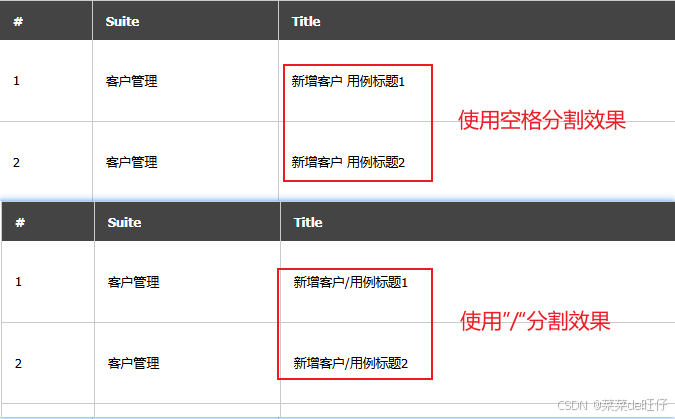
#下面模块和功能是用"空格"分割,如用"/"分隔,则替换为:separator = '/'
#separator = '/'
separator = config['sep']
if separator != ' ':
# 修改前
#separator = ' {} '.format(separator)
# 修改后
separator = f'{separator}'
return separator.join(titles)
2.1.1、效果图
2.2、zentao.py 文件修改或替换
python安装路径的**\Lib\site-packages\xmind2testcase文件夹下找到zentao.py**文件并打开
2.2.1、修改优先级部分
def gen_case_priority(priority):
# 修改前
# mapping = {1: '高', 2: '中', 3: '低'}
# 修改后,修改用例等级
mapping = {1: '1', 2: '2', 3: '3', 4: '4'}
if priority in mapping.keys():
return mapping[priority]
else:
# 修改前
#return '中'
#修改后
return '2'
2.2.2、修改用例类型
def gen_case_type(case_type):
# 修改前
# mapping = {1: '手动', 2: '自动'}
# 修改后
mapping = {1: '功能测试', 2: '性能测试',3:'配置相关',4:'安装部署',5:'安全相关',6:'接口测试',7:'其他'}
if case_type in mapping.keys():
return mapping[case_type]
else:
# 修改后
return '功能测试'
2.2.3、修改适用阶段
def gen_a_testcase_row(testcase_dict):
case_module = gen_case_module(testcase_dict['suite'])
case_title = testcase_dict['name']
case_precontion = testcase_dict['preconditions']
case_step, case_expected_result = gen_case_step_and_expected_result(testcase_dict['steps'])
# 此处可填写默认关键词
case_keyword = ''
case_priority = gen_case_priority(testcase_dict['importance'])
case_type = gen_case_type(testcase_dict['execution_type'])
# 修改前
# case_apply_phase = '迭代测试'
# 修改后
case_apply_phase = '功能测试阶段'
row = [case_module, case_title, case_precontion, case_step, case_expected_result, case_keyword, case_priority, case_type, case_apply_phase]
return row
2.2.4、处理导出文件有空行问题
# 修改前
# with open(zentao_file, 'w', encoding='gbk') as f:
# 修改后
with open(zentao_file, 'w', encoding='utf8', newline='') as f:
2.2.5、处理用例步骤、预期结果序号后多一个空格问题
def gen_case_step_and_expected_result(steps):
case_step = ''
case_expected_result = ''
# 修改后,把+ '. ' + 后的空格去掉 + '.' +
for step_dict in steps:
case_step += str(step_dict['step_number']) + '.' + step_dict['actions'].replace('\n', '').strip() + '\n'
case_expected_result += str(step_dict['step_number']) + '.' + \
step_dict['expectedresults'].replace('\n', '').strip() + '\n' \
2.2.6、处理每导出一条用例步骤和预期结果会多一个换行符问题
def gen_case_step_and_expected_result(steps):
case_step = ''
case_expected_result = ''
# 修改后,把+ '. ' + 后的空格去掉 + '.' +
for step_dict in steps:
case_step += str(step_dict['step_number']) + '.' + step_dict['actions'].replace('\n', '').strip() + '\n'
case_expected_result += str(step_dict['step_number']) + '.' + \
step_dict['expectedresults'].replace('\n', '').strip() + '\n' \
if step_dict.get('expectedresults', '') else ''
# 添加,去除每个单元格里最后一个换行符
case_step = case_step.rstrip('\n')
case_expected_result = case_expected_result.rstrip('\n')
return case_step, case_expected_result
2.2.7、填写默认关键词
def gen_a_testcase_row(testcase_dict):
case_module = gen_case_module(testcase_dict['suite'])
case_title = testcase_dict['name']
case_precontion = testcase_dict['preconditions']
case_step, case_expected_result = gen_case_step_and_expected_result(testcase_dict['steps'])
# 此处可填写默认关键词
case_keyword = ''
2.2.8、导出的文件字段修改
这里需根据实际禅道导出的CSV文件修改,可能版本不一样,存在一定差异。
def xmind_to_zentao_csv_file(xmind_file):
"""Convert XMind file to a zentao csv file"""
xmind_file = get_absolute_path(xmind_file)
logging.info('Start converting XMind file(%s) to zentao file...', xmind_file)
testcases = get_xmind_testcase_list(xmind_file)
#修改前
#fileheader = ["所属模块", "用例标题", "前置条件", "步骤", "预期", "关键词", "优先级", "用例类型", "适用阶段"]
#修改后
fileheader = ["所属模块", "用例名称", "前置条件", "步骤", "预期", "关键词", "优先级", "用例类型", "适用阶段"]
注意:这里代码的缩进是用的“空格”,不要使用“Tab”。
3、xmind编写格式规范
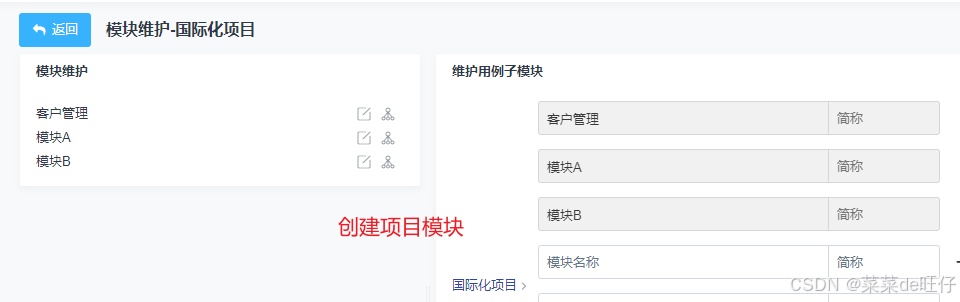
3.1、禅道创建项目
由于禅道在导入测试用例文件时,不会自动生成模块名,需要创建项目时,把模块名创建好,导入用例时,需要填写对应的模块名和ID。
如果导入禅道时,模块名没有创建好,那默认所有导入的测试用例,归为根模块“/”所有,这样是不能导入的。
建议先创建好模块名,方便用例管理,实例如下:
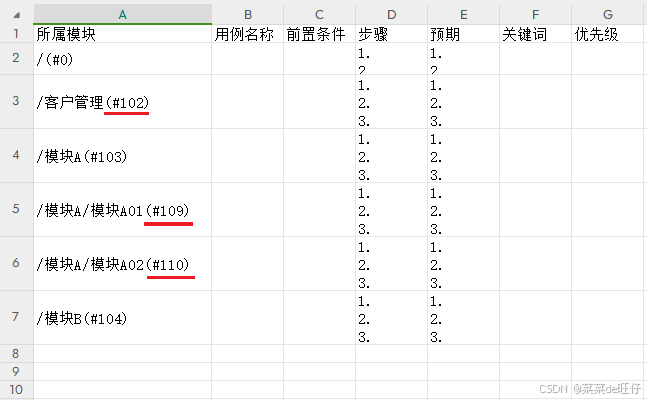
3.2、禅道导出CSV用例模版
因为上传用例,禅道是根据模块编号,识别对应的模块,所以创建项目模块后,首先要导出用例模版,获取各模块的编号,获得的模块编号如下图:
3.3、XMind用例编写规范
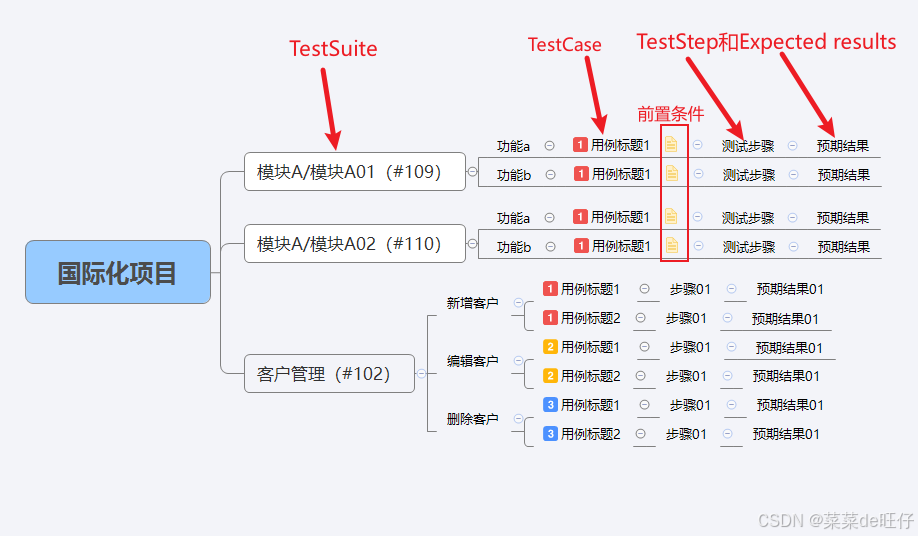
1、中心主题默认为项目名称,暂不会转换。
2、中心主题下的第一层子主题会自动识别为 TestSuite,可以理解为模块。
3、TestSuite(模块)下的子主题,添加优先级后,会自动识别为TestCase,即用例名(用例等级在 哪里加,那里就是用例名)。
4、TestCase(用例)下的子主题依次为TestStep和Expected results,即为测试步骤和期望结果;TestStep和ExpectedResult默认为空,一个TestStep对应一个ExpectedResult。
5、TestCase(用例)可以添加备注来说明前置条件。
6、TestCase的优先级Priority通过优先级图标定义:1、2、3->高、中、低,默认为中。
7、TestCase的执行类型Executiontype通过标签Label定义:功能测试、性能测试、配置相关、安装部署、安全相关、接口测试、其他,默认为功能测试。
8、TestCase的摘要Summary通过评论Comment定义,默认为“用例标题内容"。
9、在任何元素前加# 或!可忽略解析。
10、自由主题不会被解析进去。
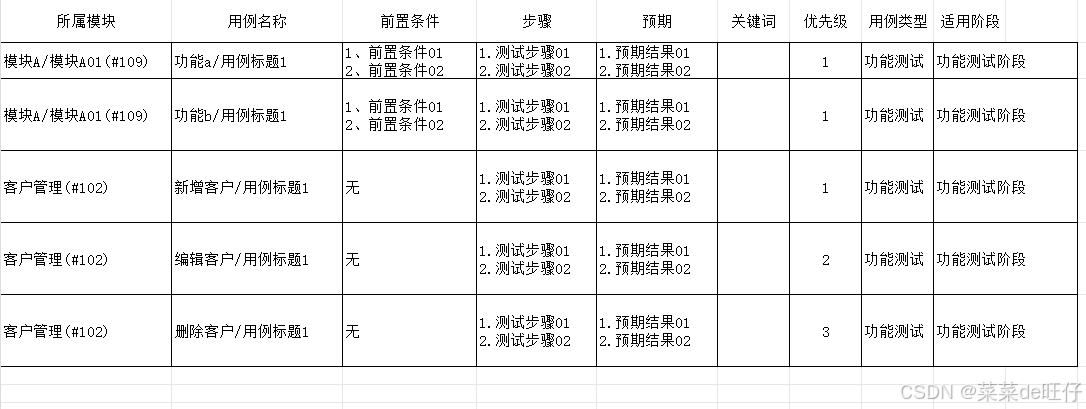
3.3.1、转换成CSV文件效果预览
下图便是转换后的CSV文件效果,这里方便大家提前了解编写规范,具体转换步骤在下面:
4、xmind转换成CSV
使用 1 步骤安装好的 xmind2testcase工具,将xmind用例转换成CSV文件:
第 1 步
** cmd 命令提示符窗口,输入启动命令:xmind2testcase webtool(默认的端口是5001)或 xmind2testcase webtool 8888 (自定义端口)启动,并获得访问地址,如下图:
xmind2testcase webtool

第 2 步
根据给出访问地址,浏览器访问 :http://127.0.0.1:5001
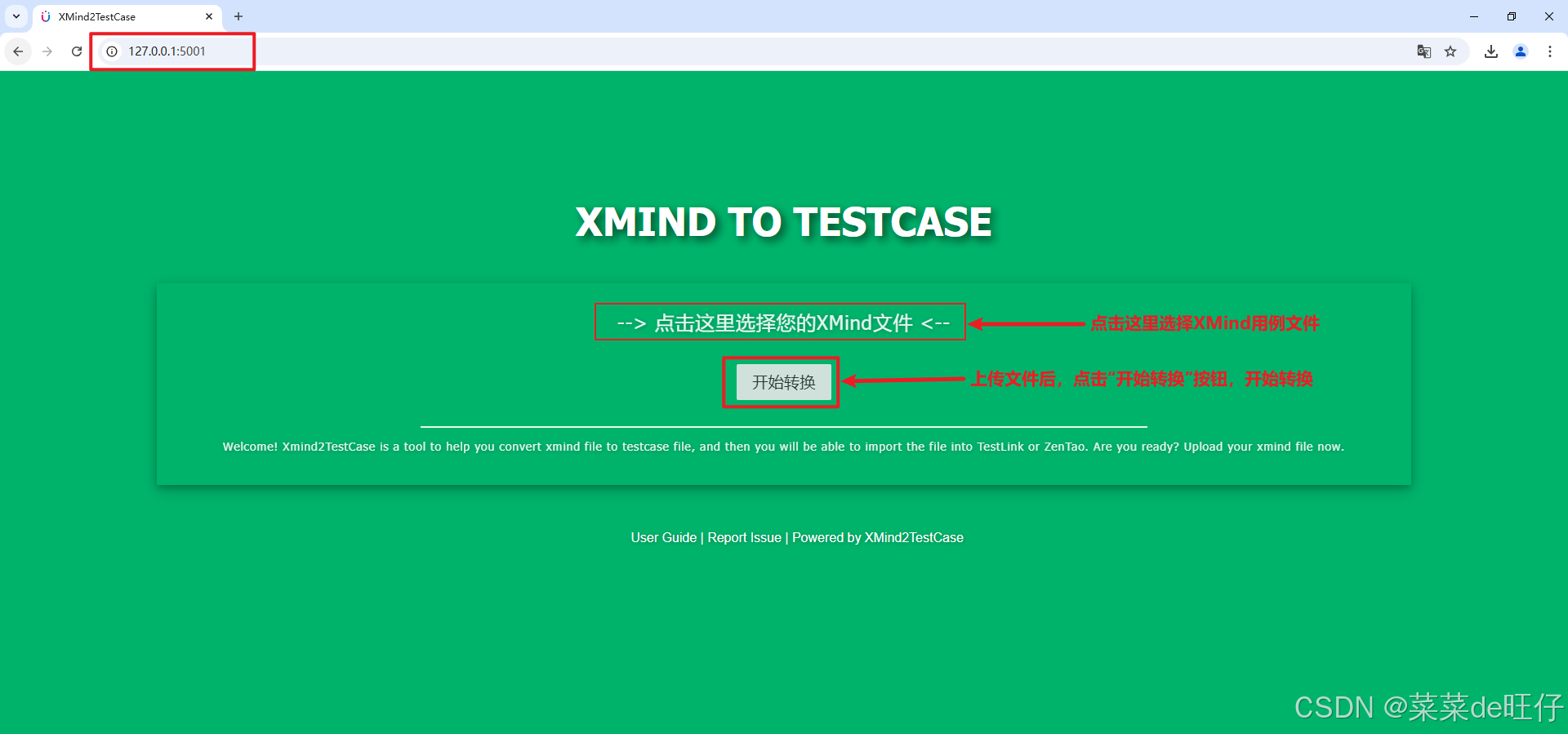
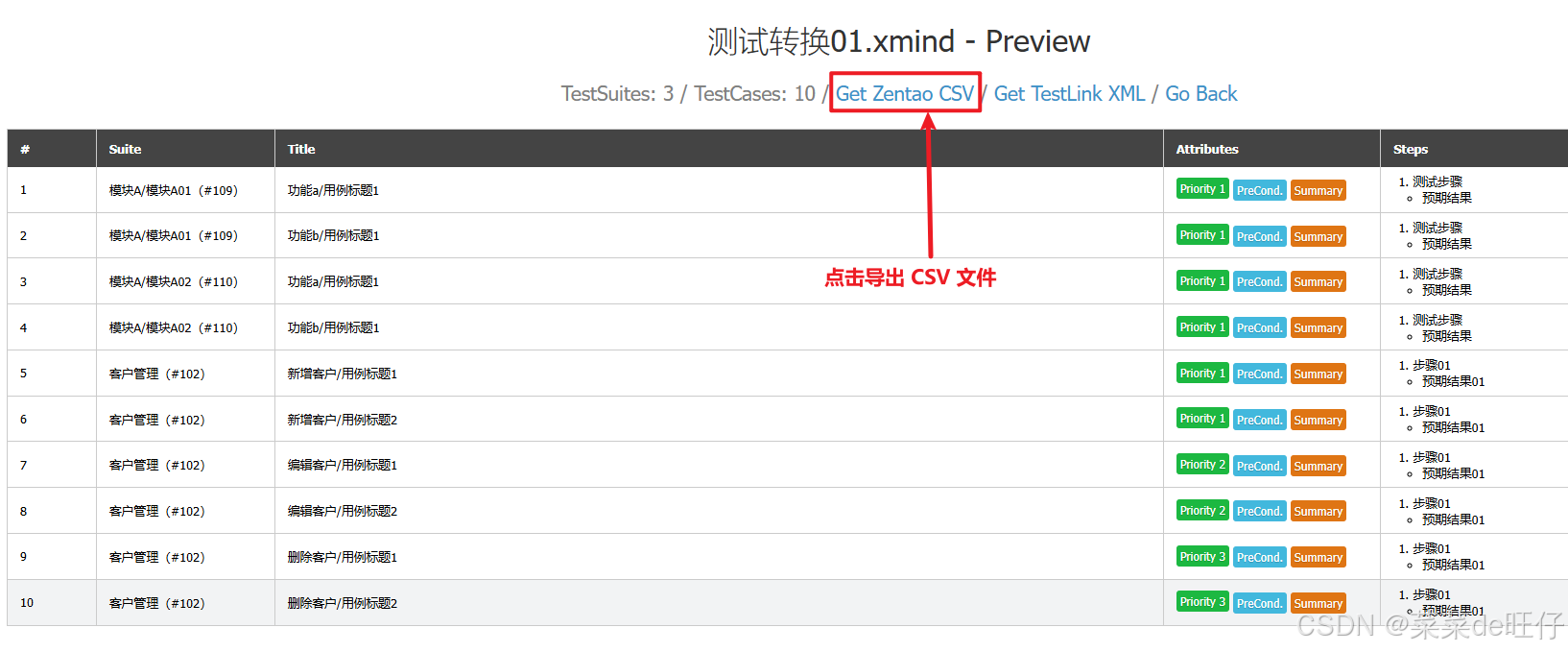
第 3 步
导出转换后的 CSV 文件,如下图,导出后的效果看 3.3.1 步骤,这里就不重发了:
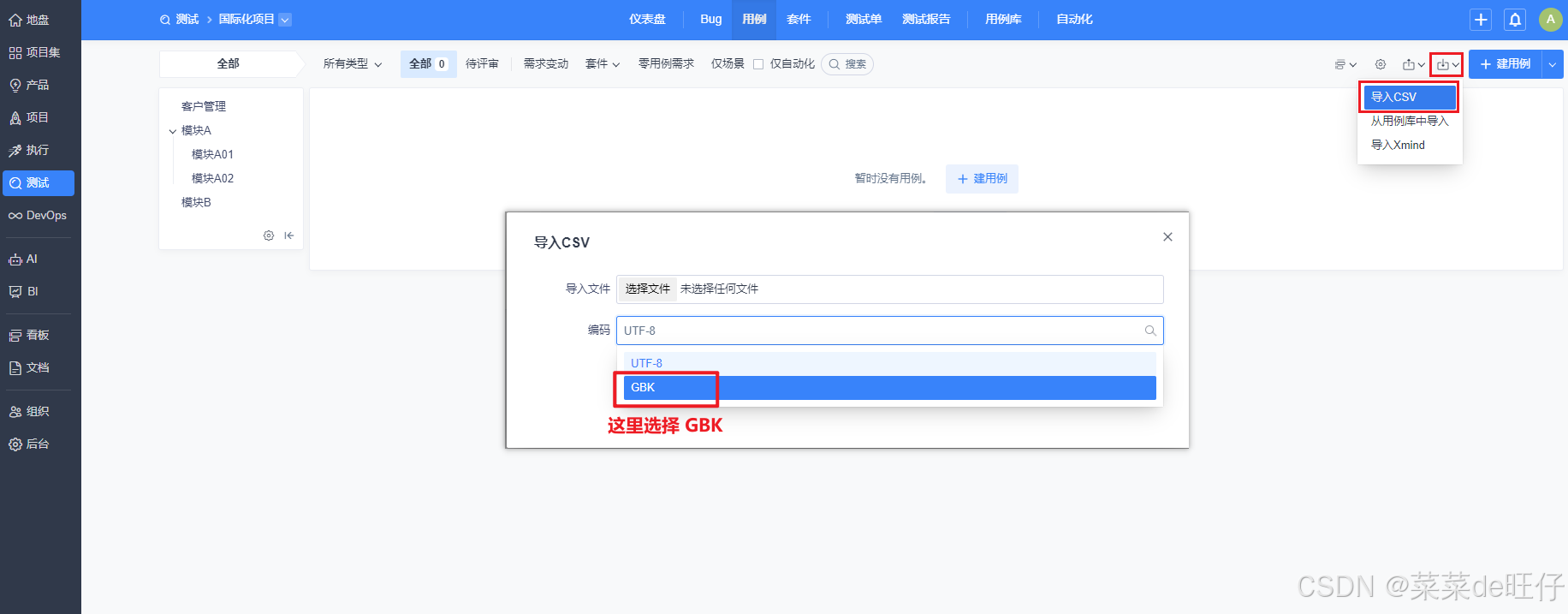
5、CSV 文件用例导入禅道
首先检查导出后的文件格式是否正确,特别是模块编号,如果与禅道导出的格式不一致,可以手动编辑CSV文件后,再导入禅道,如下图:
导入后效果预览,如发现模块信息不对,需返回前面步骤去做调整:
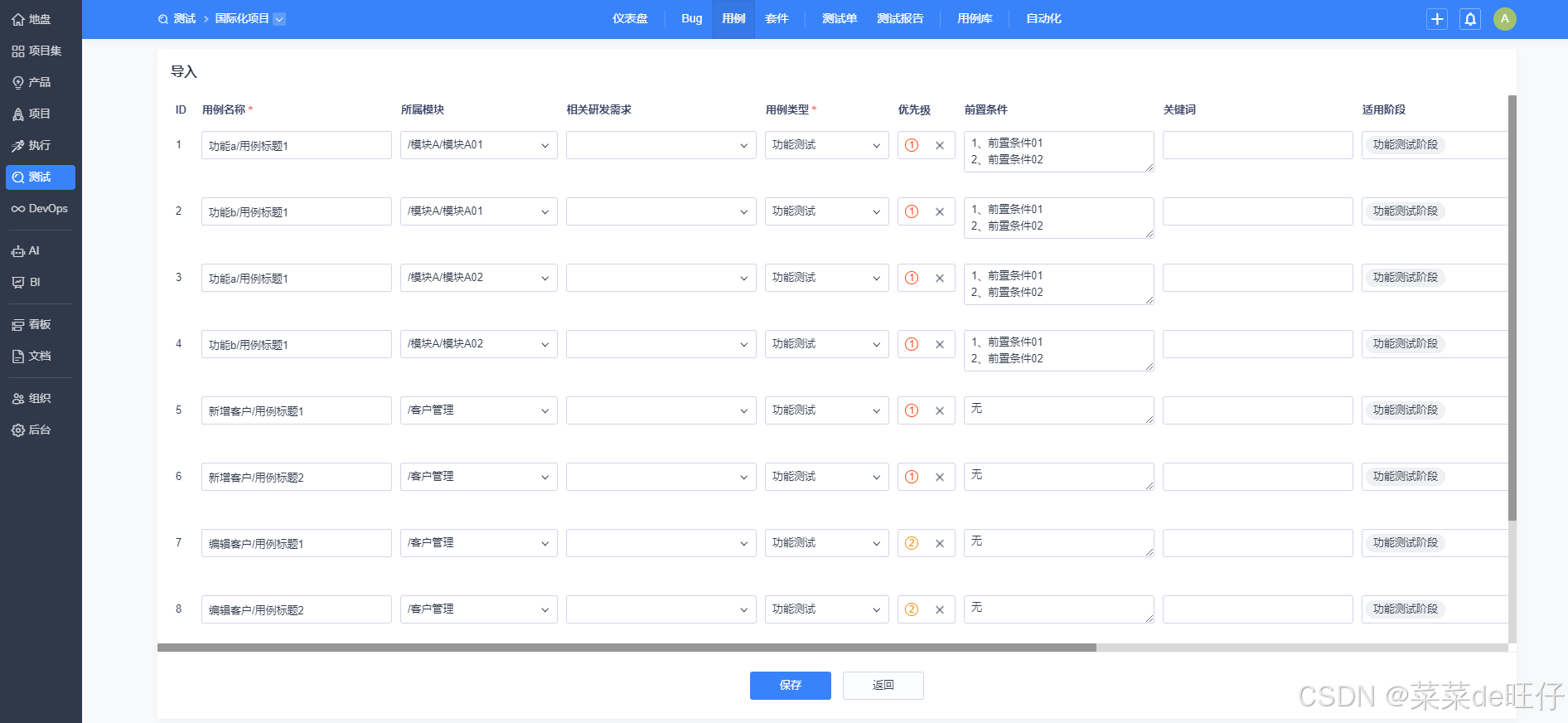
注意:如导入后发现步骤、预期结果未拆分成单独步骤,则检查 2.2.6 步骤处的代码(# 添加,去除每个单元格里最后一个换行)
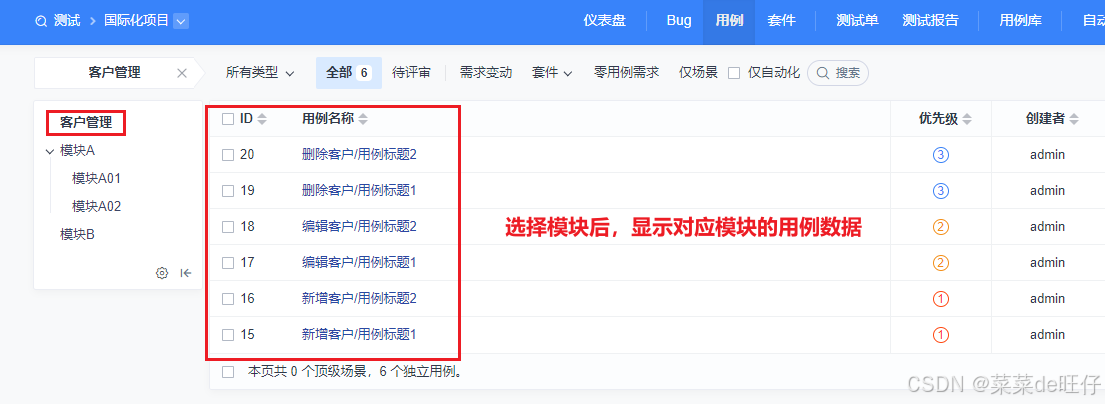
那么到这里,转换和导入禅道就已经完成。
6、常见问题处理
6.1、转换用例失败
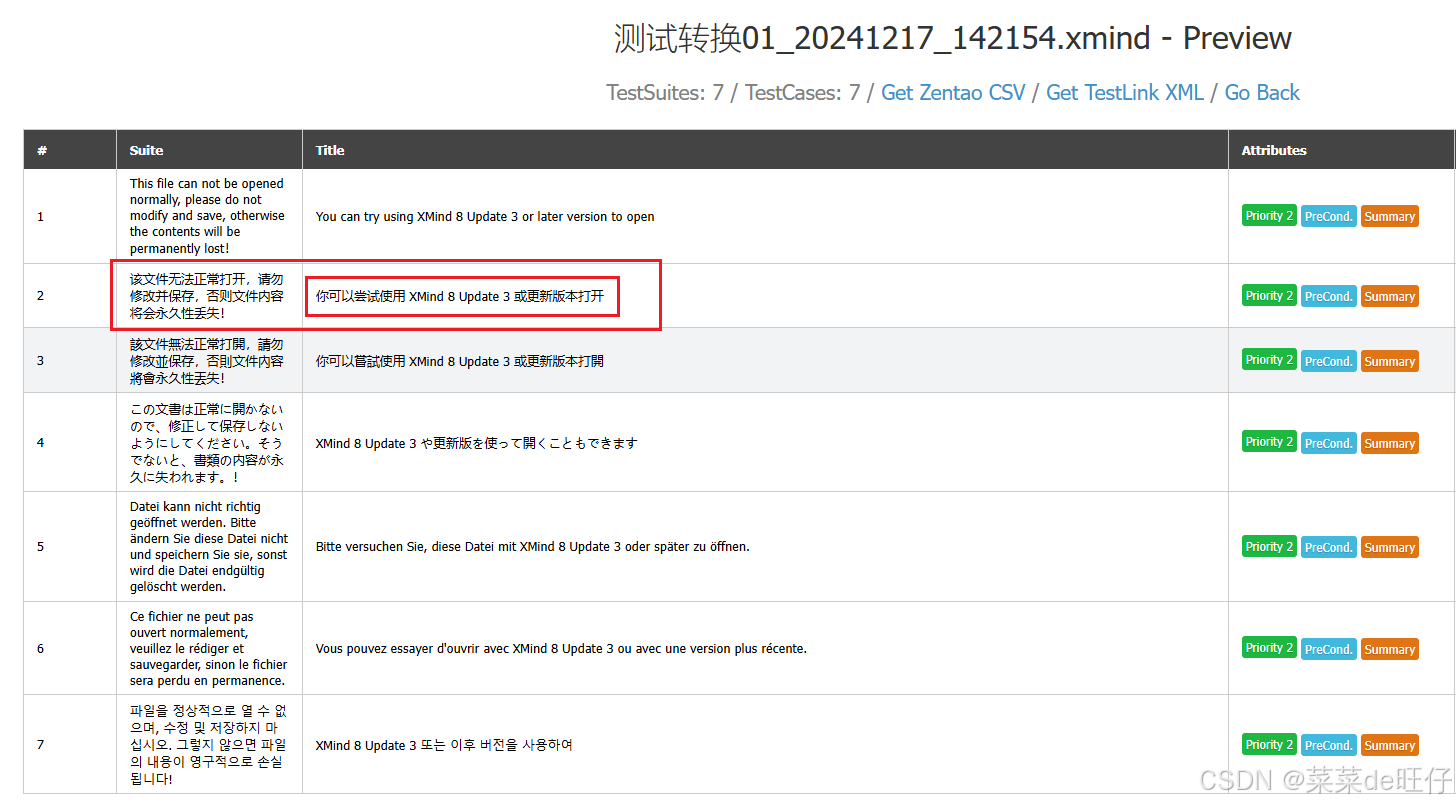
在第 3 步时,出现如下图情况(提示:该文件无法正常打开,请勿修改并保存,否则文件内容将会永久性丢失!),原因是使用的 XMind 版本不匹配,需使用 XMind8 打开用例文件后保存,再转换即可。
XMind8下载,提取码:YESA
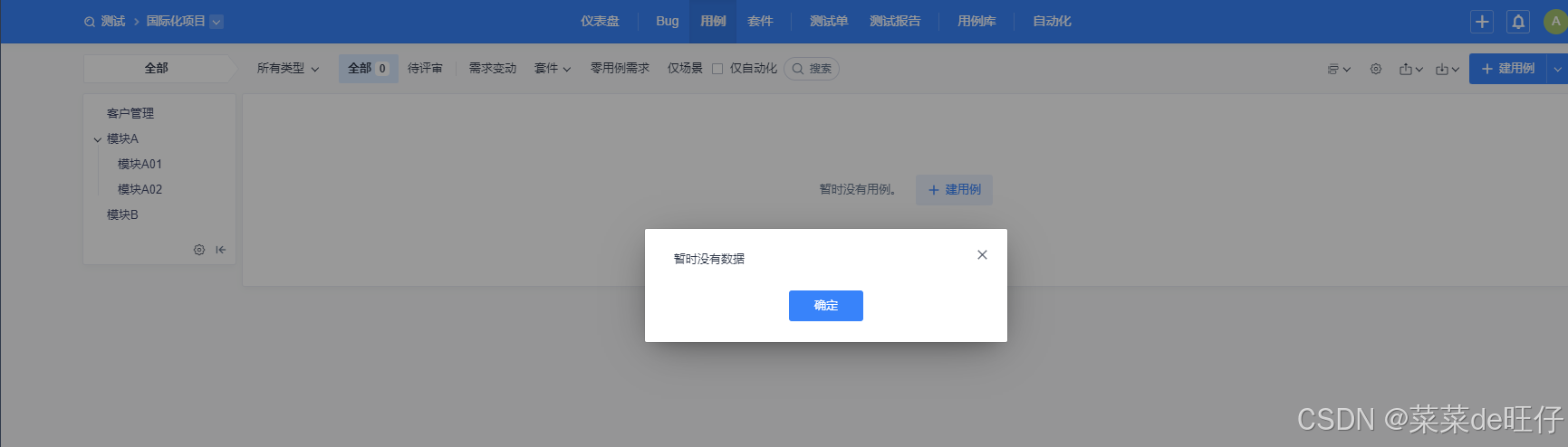
6.2、导入禅道提示暂时没有数据
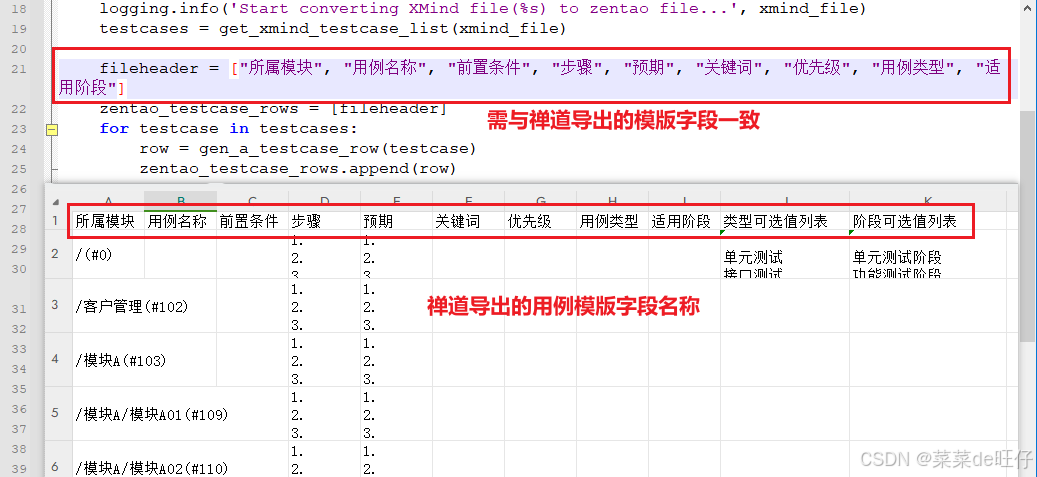
这可能是CSV文件的格式与禅道需要的格式不一致,最常见的就是字段名称不一致,可对比禅道下载的模版,查看差异
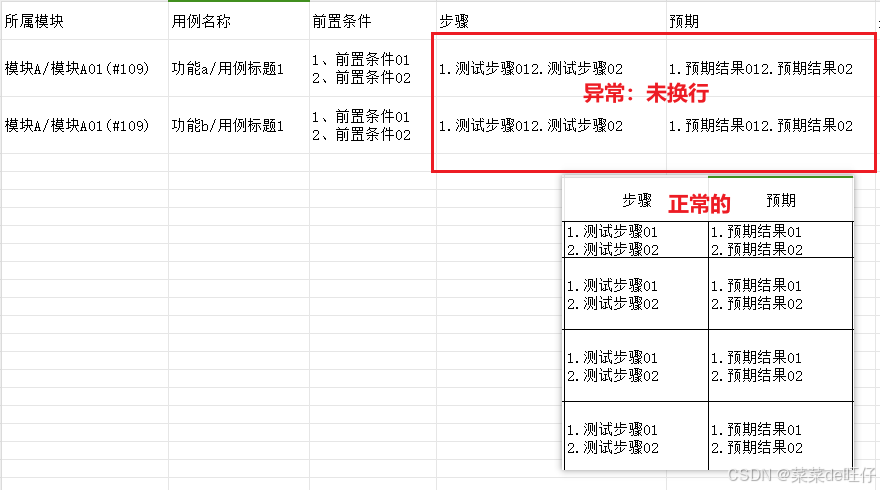
6.3、导出的CSV文件测试步骤未换行
检查 2.2.6 步骤处的代码(# 添加,去除每个单元格里最后一个换行),一般可能是代码缩进导致代码未生效。

















 3456
3456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









