






工具:xmind2testcase
该工具基于 Python 实现,通过制定测试用例通用模板, 然后使用 XMind 这款广为流传且开源的思维导图工具进行用例设计。
项目地址:GitHub - zhuifengshen/xmind2testcase: XMind2TestCase基于python实现,提供了一个高效测试用例设计的解决方案!
有俩种使用方法,一种是使用pip install xmind2testcase 下载包,适用于不需要对源码做更改的情况。注意:使用此方法需要保证版本为Xmind8,否则会出现无法解析的情况。
第二种使用方法,就是将项目克隆到本地,对源码进行部分更改,来适配高版本Xmind。我的版本是最新的xmind2024,下面则是基于此来进行配置。
一、直接把项目git clone下来
1、先fork到自己的仓库
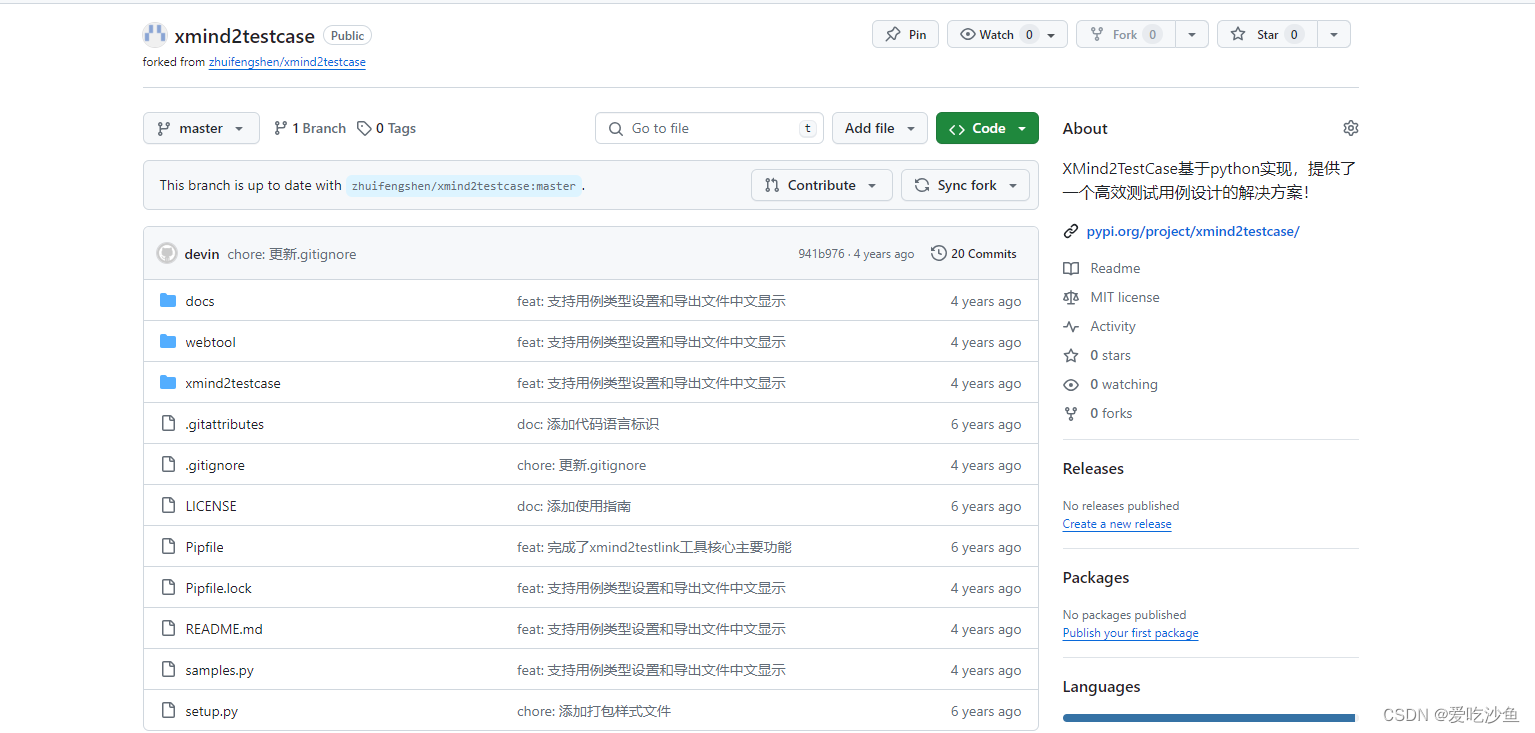
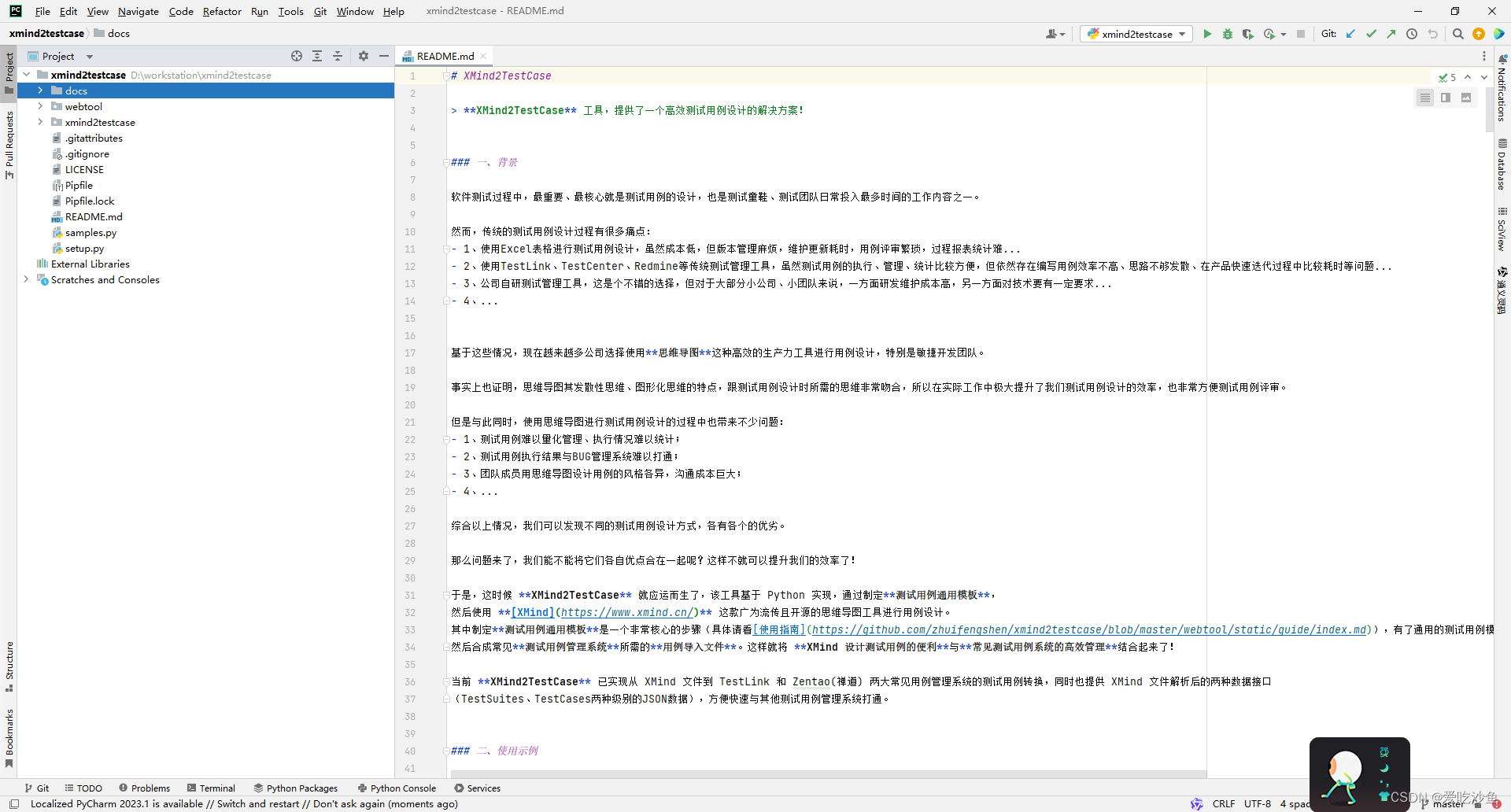
2、拉取代码到本地
3、对文件结构进行调整
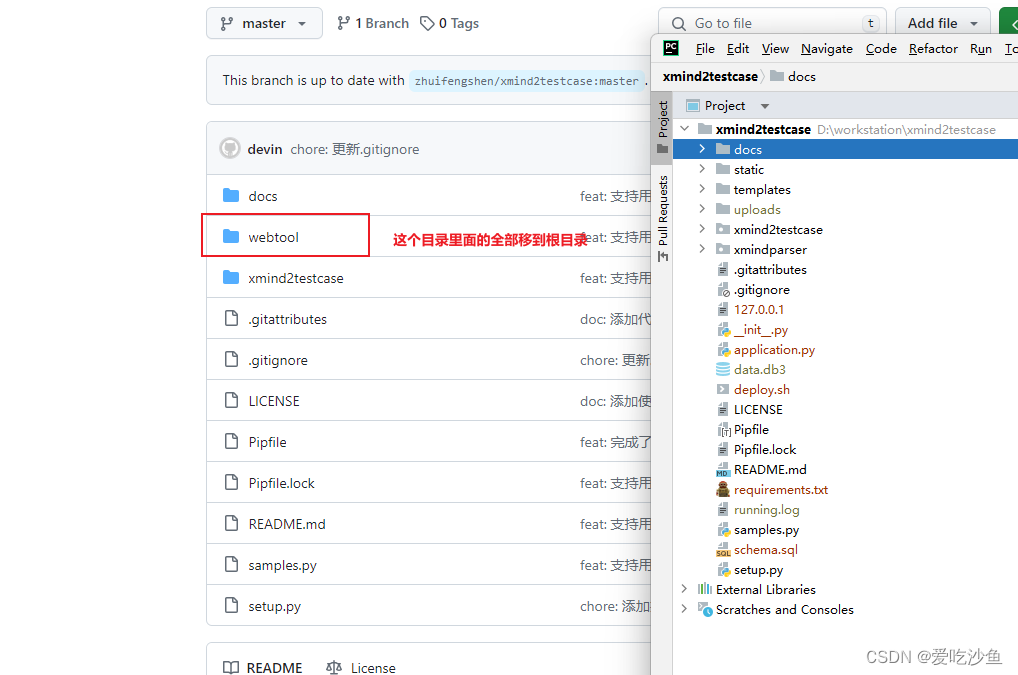
修改目录后就不要使用命令行模式。
调整完后,项目启动命令为:python application.py
4、修改xmind2testcase下的utils.py文件,把这个方法改成如下:
def get_xmind_testsuites(xmind_file):
"""Load the XMind file and parse to `xmind2testcase.metadata.TestSuite` list"""
xmind_file = get_absolute_path(xmind_file)
'''
适配xmind高版本
'''
if is_xmind_zen(xmind_file):
xmind_content_dict = xmind_to_dict(xmind_file)
else:
workbook = xmind.load(xmind_file)
xmind_content_dict = workbook.getData()
logging.debug("loading XMind file(%s) dict data: %s", xmind_file, xmind_content_dict)
if xmind_content_dict:
testsuites = xmind_to_testsuites(xmind_content_dict)
return testsuites
else:
logging.error('Invalid XMind file(%s): it is empty!', xmind_file)
return []
5、下载xmindparser包,并将该目录(位于\Lib\site-packages\xmindparser)复制到项目根目录下
pip install xmindparser 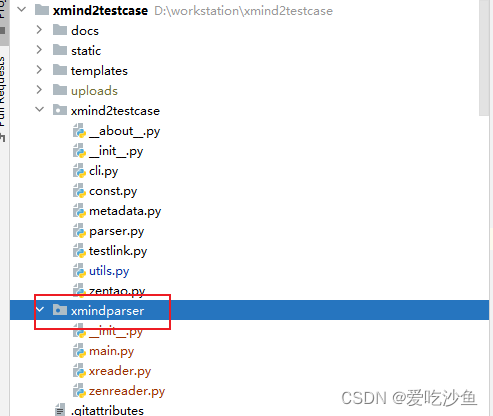
修改其中zenreader.py文件,直接使用下面代码全部覆盖
import json
from zipfile import ZipFile
from . import config, cache
content_json = "content.json"
def open_xmind(file_path):
"""open xmind as zip file and cache the content."""
cache.clear()
with ZipFile(file_path) as xmind:
for f in xmind.namelist():
for key in [content_json]:
if f == key:
cache[key] = xmind.open(f).read().decode('utf-8')
def get_sheets():
"""get all sheet as generator and yield."""
for sheet in json.loads(cache[content_json]):
yield sheet
def sheet_to_dict(sheet):
"""convert a sheet to dict type."""
topic = sheet['rootTopic']
result = {'title': sheet['title'], 'topic': node_to_dict(topic), 'structure': get_sheet_structure(sheet)}
if config['showTopicId']:
result['id'] = sheet['id']
if config['hideEmptyValue']:
result = {k: v for k, v in result.items() if v}
return result
def get_sheet_structure(sheet):
root_topic = sheet['rootTopic']
return root_topic.get('structureClass', None)
def node_to_dict(node):
"""parse Element to dict data type."""
child = children_topics_of(node)
d = {
'id': '',
'title': node.get('title', ''),
'note': note_of(node),
'markers': maker_of(node),
'label': labels_of(node),
'link': link_of(node),
'image': image_of(node),
'comment': None
# 'callout': callout_of(node)
}
if d['link']:
if d['link'].startswith('xmind'):
d['link'] = '[To another xmind topic!]'
if d['link'].startswith('xap:attachments'):
del d['link']
d['title'] = '[Attachment]{0}'.format(d['title'])
if child:
d['topics'] = []
for c in child:
d['topics'].append(node_to_dict(c))
if config['showTopicId']:
d['id'] = node['id']
# if config['hideEmptyValue']:
# d = {k: v for k, v in d.items() if v or k == 'title'}
return d
def children_topics_of(topic_node):
children = topic_node.get('children', None)
if children:
return children.get('attached', None)
def link_of(node):
return node.get('href', None)
def image_of(node):
return node.get('image', None)
def labels_of(node):
return node.get('labels', None)
def note_of(node):
note_node = node.get('notes', None)
if note_node:
note = note_node.get('plain', None)
if note:
return note.get('content', '').strip()
def maker_of(topic_node):
makers = []
maker_node = topic_node.get('markers', None)
if maker_node is not None:
for maker in maker_node:
makers.append(maker.get('markerId', None))
return makers
def callout_of(topic_node):
callout = topic_node.get('children', None)
if callout:
callout = callout.get('callout', None)
if callout:
return [x['title'] for x in callout]
6、启动

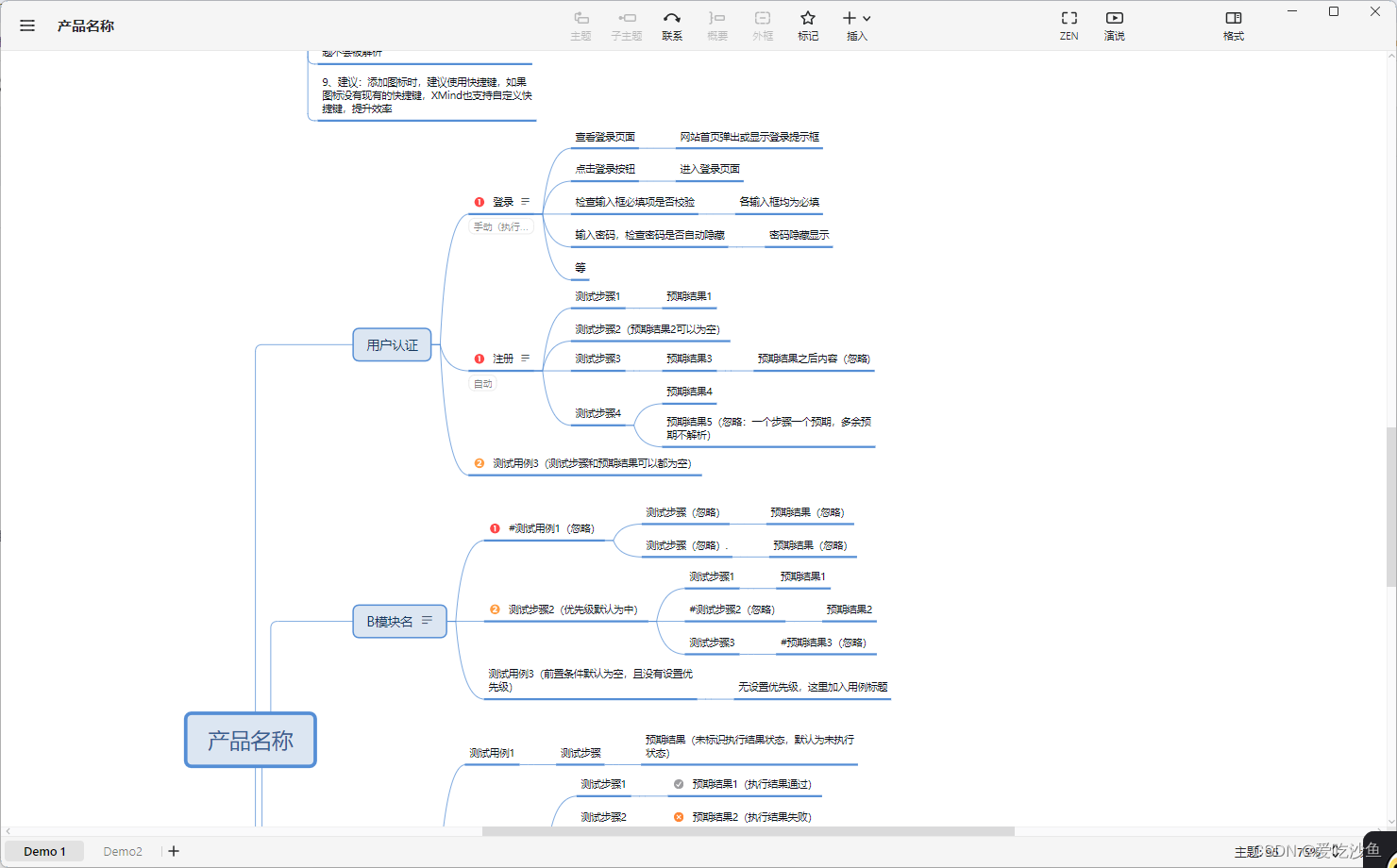
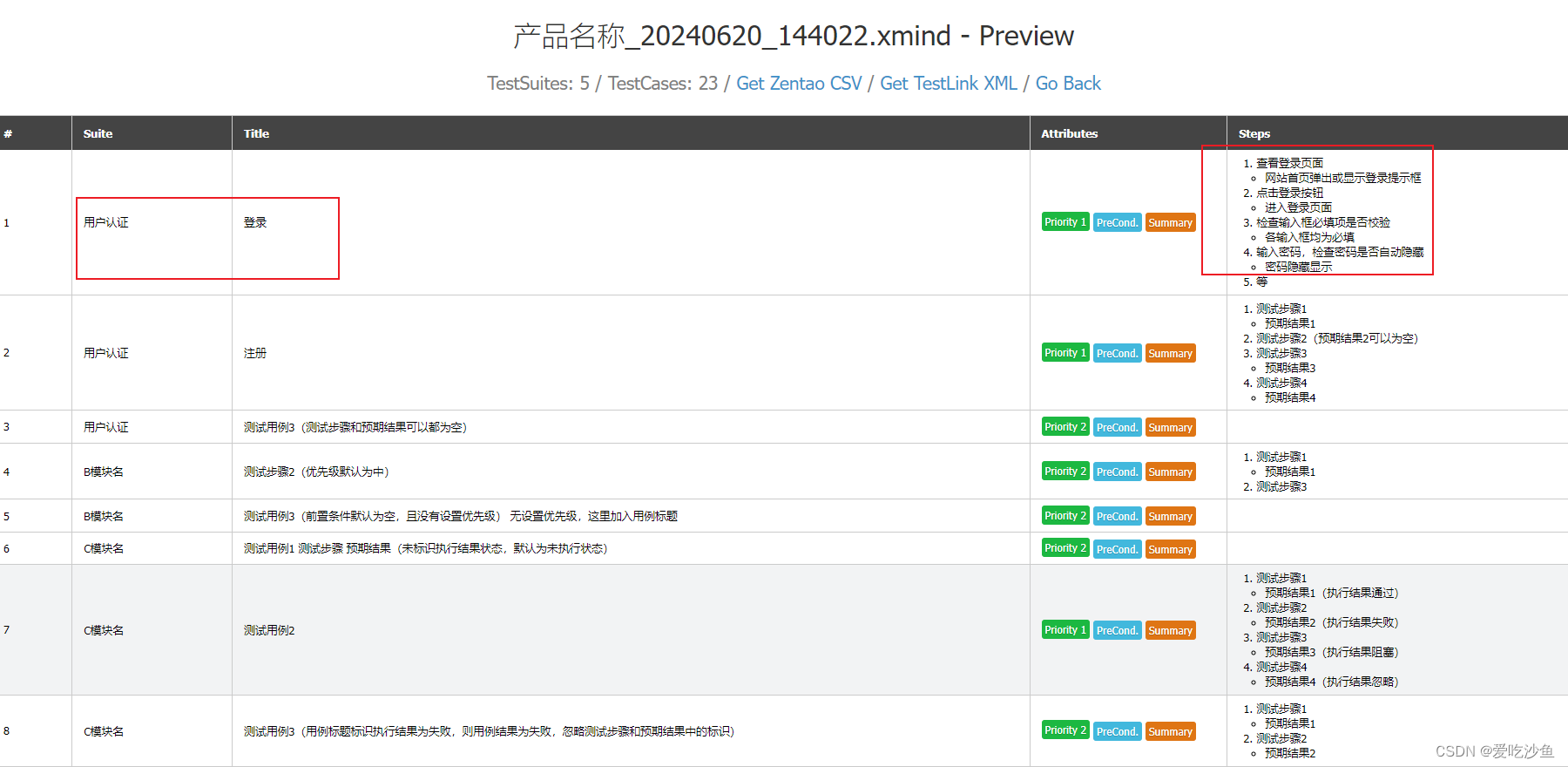
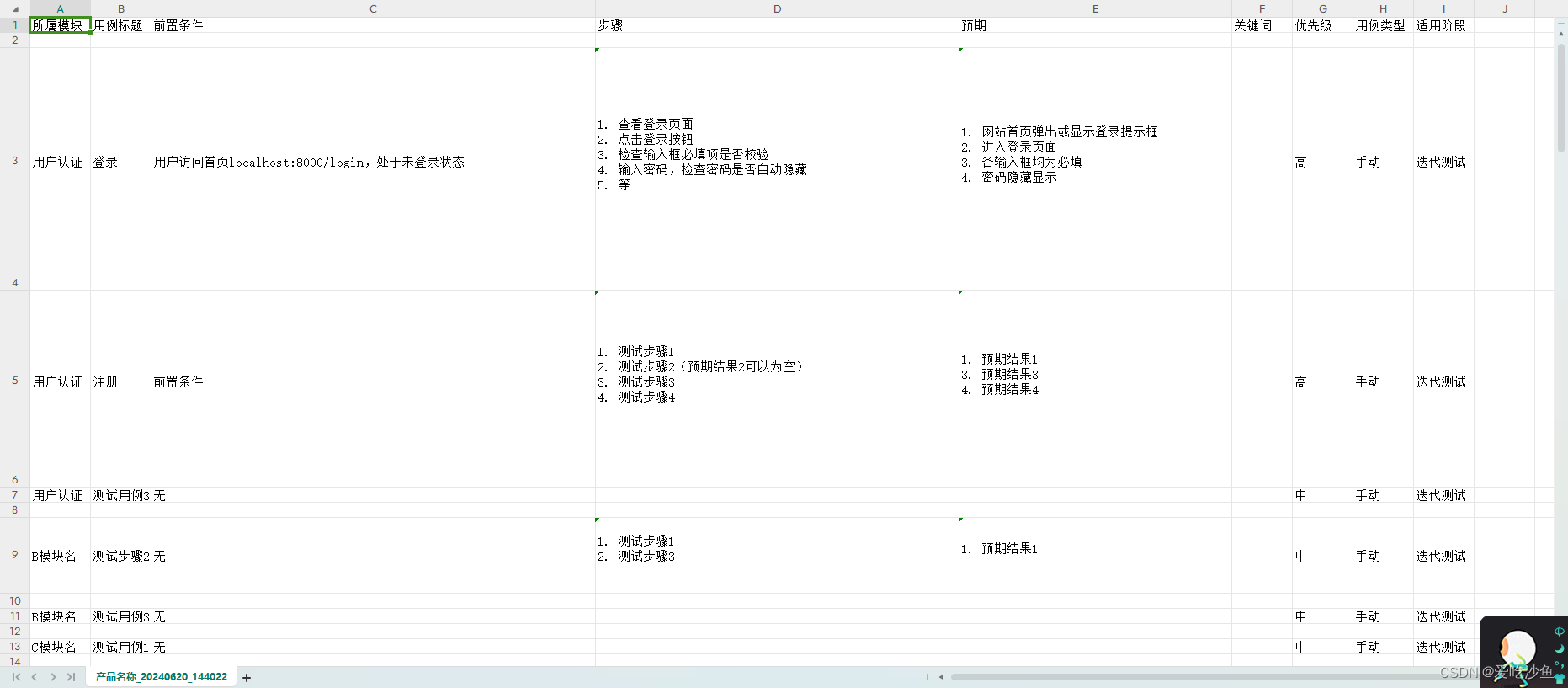
参考博客
一些感想:
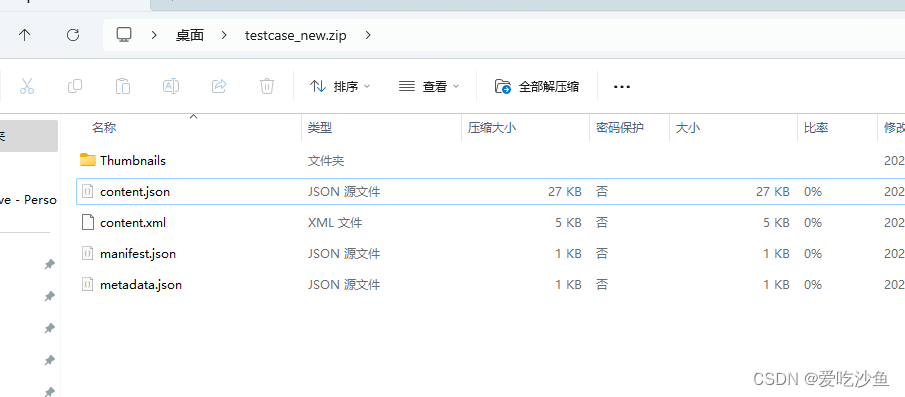
.xmind文件实际上就是一个压缩包。xmindparser大致呢就是获取到其中的content.json文件用来解析。在学习过程中,把.xmind文件后缀改为zip可以发现其中包含content.json文件。其内容就是我的思维导图的内容。


















 2107
2107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









