







 本文介绍了如何使用Python开发一个基于生物测量预测锻炼卡路里的机器学习模型,涉及数据预处理、特征选择、模型训练(如随机森林回归和XGBoost)以及模型评估的过程。
本文介绍了如何使用Python开发一个基于生物测量预测锻炼卡路里的机器学习模型,涉及数据预处理、特征选择、模型训练(如随机森林回归和XGBoost)以及模型评估的过程。
在本文中,我们将学习如何使用Python开发一个机器学习模型,该模型可以根据一些生物测量来预测一个人在锻炼过程中燃烧的卡路里数量。
导入库和数据集
Python库使我们可以轻松地处理数据,并通过一行代码执行典型和复杂的任务。
- Pandas -此库有助于以2D数组格式加载数据框,并具有多个功能,可一次性执行分析任务。
- Numpy - Numpy数组非常快,可以在很短的时间内执行大型计算。
- Matplotlib/Seaborn -此库用于绘制可视化。
- Sklearn -该模块包含多个库,这些库具有预实现的功能,可以执行从数据预处理到模型开发和评估的任务。
- XGBoost -这包含eXtreme Gradient Boosting机器学习算法,这是帮助我们实现高精度预测的算法之一。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn import metrics
from sklearn.svm import SVC
from xgboost import XGBRegressor
from sklearn.linear_model import LinearRegression, Lasso, Ridge
from sklearn.ensemble import RandomForestRegressor
import warnings
warnings.filterwarnings('ignore')
现在,让我们将数据集加载到panda的数据框中,并打印它的前五行。
df = pd.read_csv('calories.csv')
df.head()
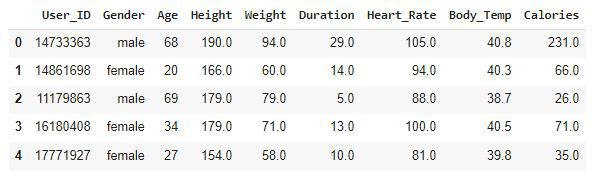
现在让我们检查数据集的大小。
df.shape
输出:
(15000, 9)
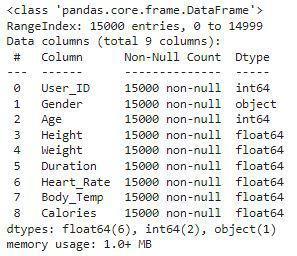
让我们看看数据集的所有数据类型。
df.info()
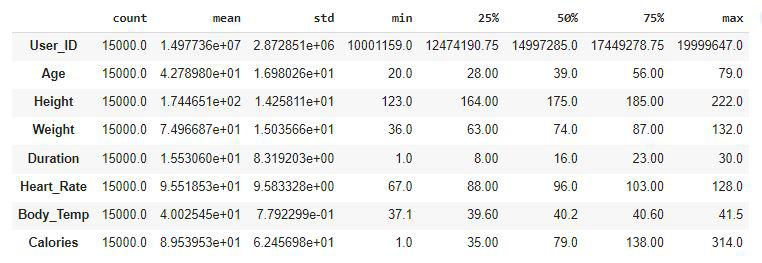
现在我们将检查数据的描述性统计测量
df.describe()
探索性数据分析
EDA是一种使用可视化技术分析数据的方法。它用于发现趋势和模式,或在统计摘要和图形表示的帮助下检查假设。
sb.scatterplot(df[ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











