









梯度下降是一个迭代优化过程,搜索目标函数的最优值(最小值/最大值)。它是改变模型参数以降低机器学习项目中的成本函数的最常用方法之一。
梯度下降的主要目标是识别在训练和测试数据集上提供最大准确度的模型参数。在梯度下降中,梯度是指向函数在特定点处最陡上升的一般方向的向量。该算法可以通过在梯度的相反方向上移动而朝向函数的较低值逐渐下降,直到达到函数的最小值。
梯度下降的类型
通常,有三种类型的梯度下降:
- 批量梯度下降(Batch Gradient Descent)
- 随机梯度下降(Stochastic Gradient Descent)
- 小批量梯度下降(Mini-batch Gradient Descent)
在本文中,我们将讨论随机梯度下降(SGD)。
随机梯度下降(SGD)
随机梯度下降(SGD)是梯度下降算法的一种变体,用于优化机器学习模型。它解决了传统梯度下降方法在处理机器学习项目中的大型数据集时的计算效率低下问题。
在SGD中,每次迭代都不使用整个数据集,而是只选择单个随机训练样本(或小批量)来计算梯度并更新模型参数。这种随机选择将随机性引入到优化过程中,因此在随机梯度下降中使用术语“随机”。
使用SGD的优点是其计算效率,特别是在处理大型数据集时。通过使用单个示例或小批量,与需要处理整个数据集的传统梯度下降方法相比,每次迭代的计算成本显著降低。
随机梯度下降算法
- 初始化:随机初始化模型的参数。
- 设置参数:确定用于更新参数的迭代次数和学习率(alpha)。
- 随机梯度下降循环:
重复以下步骤,直到模型收敛或达到最大迭代次数:
a.打乱训练数据集以引入随机性。
b.以打乱的顺序迭代每个训练示例(或小批量)。
c.使用当前训练(样本)计算成本函数相对于模型参数的梯度。
d.通过在负梯度方向上来更新模型参数,该负梯度由学习率决定。
e.评估收敛标准,例如迭代之间的成本函数的差异。 - 返回优化参数:一旦满足收敛条件或达到最大迭代次数,返回优化的模型参数。
在SGD中,由于每次迭代仅随机选择数据集中的一个样本,因此算法达到最小值的路径通常比典型的梯度下降算法更具噪声。但这并不重要,因为算法所采取的路径并不重要,只要我们达到最小值并且训练时间明显更短。
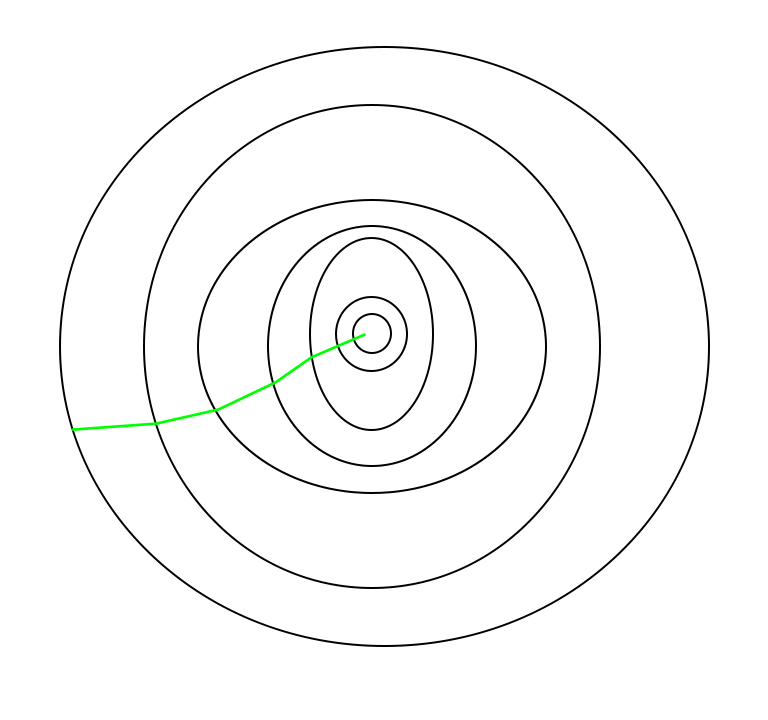
批量梯度下降采用的路径如下所示:
随机梯度下降所采取的路径看起来如下
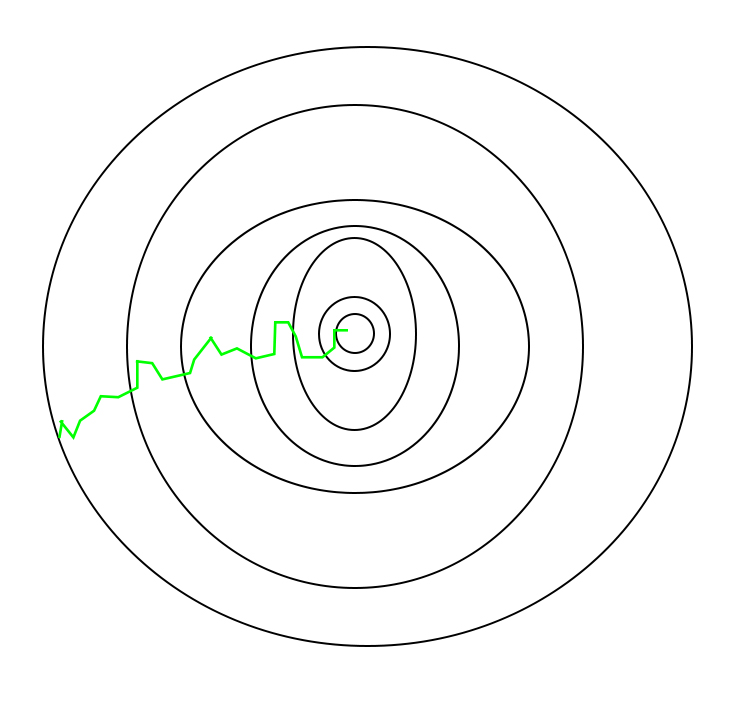
需要注意的一点是,由于SGD通常比典型的梯度下降噪声更大,因此由于其下降的随机性,通常需要更高次数的迭代才能达到最小值。即使它需要比典型的梯度下降更高的迭代次数来达到最小值,它仍然比典型的梯度下降在计算上划算得多。因此,在大多数情况下,SGD优于批量梯度下降来优化学习算法。
随机梯度下降的Python代码实现
我们将创建一个SGD类,其中包含我们将在更新参数、拟合训练数据集和预测新测试数据时使用的方法。我们将使用的方法如下:
- 梯度-此方法将用于更新模型的参数。对于每次迭代,它将计算预测数据点和实际数据点之间的误差。
- 拟合-此方法将用于将训练数据集拟合到机器学习模型中。它将打乱数据索引,并将计算每个数据点的梯度,并更新参数θ。
- 预测-此方法将用于预测新数据点。
import numpy as np
class SGD:
def __init__(self, lr=0.01, max_iter=1000, batch_size=32, tol=1e-3):
# learning rate of the SGD Optimizer
self.learning_rate = lr
# maximum number of iterations for SGD Optimizer
self.max_iteration = max_iter
# mini-batch size of the data
self.batch_size = batch_size
# tolerance for convergence for the theta
self.tolerence_convergence = tol
# Initialize model parameters to None
self.theta = None
def fit(self, X, y):
# store dimension of input vector
n, d = X.shape
# Intialize random Theta for every feature
self.theta = np.random.randn(d)
for i in range(self.max_iteration):
# Shuffle the data
indices = np.random.permutation(n)
X = X[indices]
y = y[indices]
# Iterate over mini-batches
for i in range(0, n, self.batch_size):
X_batch = X[i:i+self.batch_size]
y_batch = y[i:i+self.batch_size]
grad = self.gradient(X_batch, y_batch)
self.theta -= self.learning_rate * grad
# Check for convergence
if np.linalg.norm(grad) < self.tolerence_convergence:
break
# define a gradient functon for calculating gradient
# of the data
def gradient(self, X, y):
n = len(y)
# predict target value by taking taking
# taking dot product of dependent and theta value
y_pred = np.dot(X, self.theta)
# calculate error between predict and actual value
error = y_pred - y
grad = np.dot(X.T, error) / n
return grad
def predict(self, X):
# prdict y value using calculated theta value
y_pred = np.dot(X, self.theta)
return y_pred
SGD实现
我们将创建一个具有100行和5列的随机数据集,并在此数据上拟合我们的随机梯度下降类。 同时,我们将采用SGD的预测方法。
# Create random dataset with 100 rows and 5 columns
X = np.random.randn(100, 5)
# create corresponding target value by adding random
# noise in the dataset
y = np.dot(X, np.array([1, 2, 3, 4, 5]))\
+ np.random.randn(100) * 0.1
# Create an instance of the SGD class
model = SGD(lr=0.01, max_iter=1000,
batch_size=32, tol=1e-3)
model.fit(X, y)
# Predict using predict method from model
y_pred = model.predict(X)
为了减少损失函数,基于不同的参数来获取值并调整它们的这个循环被称为反向传播。
随机梯度下降的优点
- 速度:SGD比梯度下降的其他变体(例如批量梯度下降和小批量梯度下降)更快,因为它仅使用一个示例来更新参数。
- 内存效率:由于SGD一次更新一个训练示例的参数,因此它具有内存效率,可以处理无法放入内存的大型数据集。
- 避免局部最小值:由于SGD中的噪声更新,它具有从局部极小值逃逸并收敛到全局极小值的能力。
随机梯度下降的缺点
- 噪声更新:SGD中的更新是有噪声的并且具有高方差,这可能使得优化过程不太稳定并且导致围绕最小值的振荡。
- 缓慢收敛:SGD可能需要更多迭代来收敛到最小值,因为它一次更新每个训练示例的参数。
- 学习率敏感:学习率的选择在SGD中可能是关键的,因为使用高学习率会导致算法超过最小值,而低学习率会导致算法缓慢收敛。
- 不太准确:由于噪声更新,SGD可能不会收敛到精确的全局最小值并且可能导致次优解。这可以通过使用诸如学习率调整和基于动量的更新等技术来缓解。














 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









