








spark+kafka实时数据分析
一、项目内容
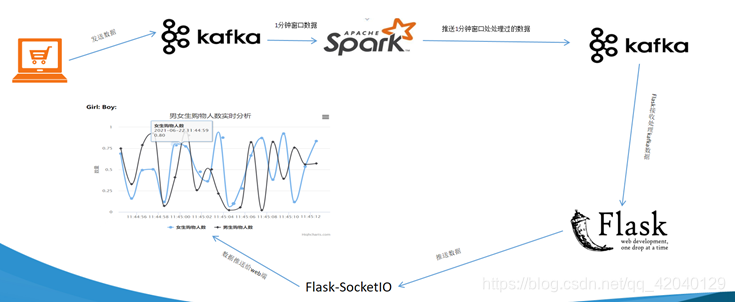
1. 项目流图
环境要求
centos 7以上
Spark: 2.1.0
Scala: 2.11.8
kafka: 0.8.2.2
Python: 3.x(3.0以上版本)
Flask: 0.12.1
Flask-SocketIO: 2.8.6
kafka-python: 1.3.3
2. 数据处理和python操作kafka
本项目采用的数据集压缩包为data_format.zip点击这里下载data_format.zip
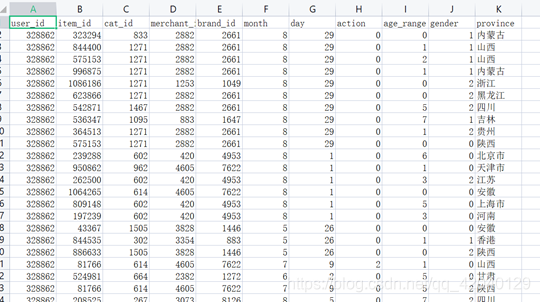
链接: data_format.zip.数据集,该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv. 在这个案例中只是用user_log.csv这个文件,下面列出文件user_log.csv的数据格式定义:
用户行为日志user_log.csv,日志中的字段定义如下:
user_id | 买家id
item_id | 商品id
cat_id | 商品类别id
merchant_id | 卖家id
brand_id | 品牌id
month | 交易时间:月
day | 交易事件:日
action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
gender | 性别:0表示女性,1表示男性,2和NULL表示未知
province| 收获地址省份
数据具体格式如下:
这个项目实时统计每秒中男女生购物人数,因此针对每条购物日志,我们只需要获取gender即可,然后发送给Kafka,接下来Spark Streaming再接收gender进行处理。
3. 数据处理展示结果
(1)数据读取并放入kafka

(2) 数据处理结果
二、项目环境搭建
1. 安装Java环境
1.1 官网下载java安装包,解压缩到对应目录
下载上传对应文件到服务器opt目录下面,然后进行解压
tar -zxvf jdk-8u77-linux-x64.tar.gz -C /usr/hadoop
1.2. 配置java环境变量
vi /etc/profile
文件底部添加该配置文件JAVA_HOME配置的路径和自己java安装位置一致
export JAVA_HOME=/usr/hadoop/jdk1.8.0_77
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:$JAVA_HOME/bin:$PATH
保存退出
让配置文件生效
source /etc/profile
1.3 查看java环境是否安装成功
java –version

2. 安装hadoop
2.1. 配置hosts文件
将各服务器的ip和名称配置到/etc/hosts文件中
此步骤目的是让服务器之间可以通过服务器名称来访问。使用ifconfig命令可以查看本机ip,使用hostname命令可以查看本服务器名称。使用vi命令编辑/etc/hosts文件,将三台服务器的ip和名称写入文件,然后输入Ecs键,输入 :wq (冒号加wq)保存退出。注意:三台服务器上均需要配置!
修改主机名称
hostnamectl set-hostname master
参考配置(服务器名称和ip请根据实际情况配置):
master 表示名字节点的 hostname 10.67.15.126 是其IP地址
10.67.15.126 master
10.67.15.121 slave1
10.67.15.122 slave2
2.2. 下载hadoop
百度下载并上传到服务器opt目录下面
然后解压到目录/usr/hadoop下
(解压缩后文件夹为hadoop-2.7.7)
tar -zxvf 解压文件名 -C /usr/hadoop
2.3. 配置环境文件
在hadoop-2.7.7目录下创建四个目录:tmp、hdfs、hdfs/data、hdfs/name配置hadoop集群是需要在每一台服务器上都配置,这里我们只在主服务器上完成配置,配置完成之后我们将配置好的hadoop复制到其他服务器即可。步骤3 配置hadoop 中的所有步骤均在主服务器上操作。可以使用mkdir命令来创建目录。后面我们配置hadoop的时候会用到这些目录,三个目录的作用如下:
tmp目录用来存储hadoop的临时文件,
hdfs/data目录用来存储hdfs的文件块
hdfs/name目录用来存储元数据信息
2.3.1. 配置core-site.xml文件
进入hadoop-2.7.7目录下的etc/hadoop目录下,修改core-site.xml文件,在配置中增加如下配置项:
fs.defaultFS :远程访问hdfs系统文件的方式,一般使用hdfs://<namenode服务器名>:9000
hadoop.tmp.dir:hadoop临时目录,使用我们之前创建的tmp目录,格式file:<tmp路径>
io.file.buffer.size: 流文件的缓冲区,单位为字节。这里配置:131072 表示128KB
参考配置如下:master为NameNode服务器名称(请根据现场实际情况配置)。
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
2.3.2. 配置hdfs-site.xml文件
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改hdfs-site.xml文件,该文件主要是hdfs系统的相关配置,在配置中增加如下配置项:
dfs.namenode.name.dir :使用之前我们创建的hdfs/name目录
dfs.datanode.data.dir:使用之前我们创建的hdfs/data目录
dfs.replication: 文件保存的副本数
dfs.namenode.secondary.http-address:http访问hdfs系统的地址(一般使用服务器名称)和端口
dfs.webhdfs.enabled:是否开启web访问hdfs系统。设置为true可以让外部系统使用http协议访问hdfs系统。
参考配置如下:master为NameNode服务器名称(请根据现场实际情况配置)。
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.7/hdfs/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop/hadoop-2.7.7/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
2.3.3. 配置mapred-site.xml文件
mappred.xml文件中主要配置mapreduce相关的配置。
进入hadoop-2.7.3目录下的etc/hadoop目录下,将文件mapred-site.xml.template使用mv命令重命名为mapred-site.xml,并修改该文件增加如下配置项:
mapreduce.framework.name :运行mapreduce使用的框架,2.0以上的都是用的yarn
mapreduce.jobhistory.address:历史服务器的地址
mapreduce.jobhistory.webapp.address: 历史服务器的web访问地址
参考配置如下:master为NameNode服务器名称(请根据现场实际情况配置)。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
2.3.4. 配置yarn-site.xml文件
yarn-site.xml文件中主要配置yarn框架相关的配置。
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改yarn-site.xml文件,增加如下配置项:
yarn.nodemanager.aux-services:NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序
yarn.nodemanager.auxservices.mapreduce.shuffle.class:mapreduce执行shuffle使用的class
yarn.resourcemanager.address:resourceManager的地址,客户端通过该地址向RM提交应用程序,杀死应用程序等
yarn.resourcemanager.scheduler.address:ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源
yarn.resourcemanager.resource-tracker.address: ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等
yarn.resourcemanager.admin.address:ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令。
yarn.resourcemanager.webapp.address:ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看yarn框架中运行的任务状态
yarn.nodemanager.resource.memory-mb:NodeManager运行所需要的内存,单位MB。
参考配置如下:master为NameNode服务器名称(请根据现场实际情况配置)。
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
2.3.5. 修改slaves,增加从服务器
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改slaves文件,将其中的localhost去掉,并所有的从服务器名称添加进去,每台服务器名称占一行。
参考配置如下(服务器名称请根据自己实际情况配置):
slave1
slave2
2.3.6. 配置hadoop-env.sh、yarn-env.sh的JAVA_HOME
进入hadoop-2.7.3目录下的etc/hadoop目录下,修改hadoop-env.sh、yarn-env.sh 两个文件,增加JAVA_HOME的环境变量配置。查看jdk目录可使用命令echo $JAVA_HOME。
在hadoop-env.sh、yarn-env.sh两个文件中分别增加如下一段代码(jdk目录请根据自己实际情况设置):
export JAVA_HOME=/usr/hadoop/jdk1.8.0_77/
2.4. 配置主服务器免登录访问从服务器
为每个节点分别产生公、私密钥配置以下操作我们选取namenode服务器master作为示例,成功之后,也在另外两台服务器上执行相同的操作!!!
开始之前我们可以先测试下,用ssh命令登录本机或者其他服务器,无论是本机还是其他主机,都是需要输入密码的。
使用ssh-keygen命令可以为本服务器生成公钥(id_dsa.pub)和私钥(Id_dsa),要求输入passphrased的时候直接敲回车。
参考命令:
ssh-keygen -t dsa -f ~/.ssh/id_dsa
再使用cp命令,将公钥文件复制成authorized_keys文件。
参考命令:
cp ~/.ssh/id_dsa.pub ~/.ssh/authorized_keys
此时,在本服务器上生成公钥和私钥的步骤基本完成,使用 ssh 命令登录本机不会再要求输入密码(如果是第一次登录会要求确认是否继续连接)
成功之后,也在另外两台服务器上执行相同的操作!!!
2.5. 让主结点能通过SSH免密码登录两个子结点
将主服务器的公钥文件内容添加到从服务器的authorized_keys文件里,就可以实现主服务器免密码登录从服务器了。以下操作均在主服务器上执行。
使用scp命令,将主服务器的公钥文件id_dsa.pub复制到从服务器上,并命令为master.pub(此文件名可以自己随意起)。
参考命令如下(root为登录从服务器的用户名,slave1为从服务器的名称,请根据自己实际情况修改):
scp ~/.ssh/id_dsa.pub 10.67.15.121:~/.ssh/master.pub
scp ~/.ssh/id_dsa.pub 10.67.15.122:~/.ssh/master.pub
输入此命令后,会要求输入slave1服务器的root账号密码,输入密码即可。
再将上一步生成的master.pub文件内容追加到slave1的authorized_keys文件中,可以登录到slave1上去操作,也可以在master上使用ssh命令远程操作。这里我们使用ssh命令,在master上远程操作,参考命令如下(root为登录从服务器的用户名,slave1为从服务器的名称,master.pub为我们上一步生成的文件,请根据自己实际情况修改):
ssh root@slave1 "cat ~/.ssh/master.pub>>~/.ssh/authorized_keys"
ssh root@slave2 "cat ~/.ssh/master.pub>>~/.ssh/authorized_keys"
输入此命令后,会要求输入slave1服务器的root账号密码,输入密码即可。
如果不出问题,此时master服务就可以通过SSH免密码访问slave1了。
按照上面的方法,让master可以ssh免密码访问另外一台从服务器!!!!
2.6. 将Hadoop复制到各从服务器
通过以上步骤我们基本已经配置好了hadoop的集群配置,现在我们需要将我们配置好的文件复制到其他的服务器上。将文件copy到从服务器上的方法有很多,建议使用scp命令。
参考:在主服务器上执行以下两条命令(其中root为登录从服务器的用户名,slave1,slave2为从服务器的名称,请根据自己实际情况修改):
scp -r /usr/hadoop/hadoop-2.7.7/ 10.67.15.121:/usr/hadoop/
scp -r /usr/hadoop/hadoop-2.7.7/ 10.67.15.122:/usr/hadoop/
2.7. 格式化namenode
在主服务器上,进入hadoop-2.7.3目录下,格式化namenode。
参考命令:
cd /usr/local/zhitu/hadoop-2.7.3
bin/hdfs namenode -format
2.8. 启动Hadoop
在主服务器上,进入hadoop-2.7.3目录下,启动Hadoop集群。
参考命令:
sbin/./start-all.sh
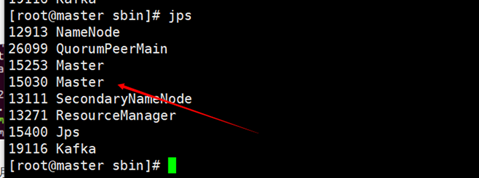
2.9. 使用jps命令查看服务
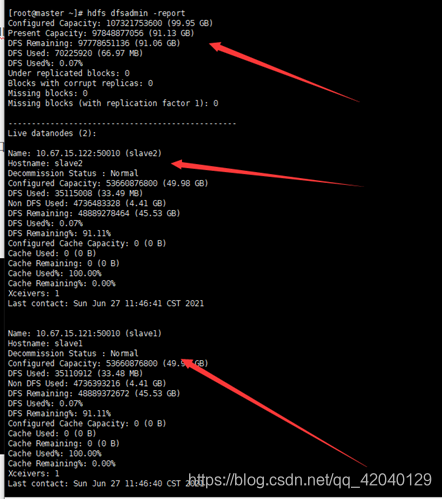
jps命令为jdk提供的查看java进程的命令,hadoop服务如果启动成功了,可以在主服务器上查看到NameNode ,SecondaryNameNode,ResourceManager 三个服务,从服务器上看到到NodeManager, DataNode 两个服务。
参考命令:
jps
查看datanode的端口
hdfs dfsadmin –report
3. 安装spark
3.1. 下载spark的地址
http://spark.apache.org/downloads.html
3.2. 下载好的压缩包放到虚拟机opt目录下
3.3. 解压
tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz -C /usr/hadoop
3.4. 更改名字
mv spark-2.3.1-bin-hadoop2.7.tgz spark

3.5. 目录切换到 /opt/spark/conf 文件夹下边
Spark的配置文件都在这个文件夹里边 在修改配置文件之前,查看文件夹权限
3.6. 修改文件夹权限
chmod -R 7777 ./spark
之后开始修改配置文件 ,进入到conf 文件夹输入
cp spark-env.sh.template spark-env.sh
复制 spark-env.sh.template 文件夹并改名为 spark-env.sh
编辑spark-env.sh 文件 添加以下内容:
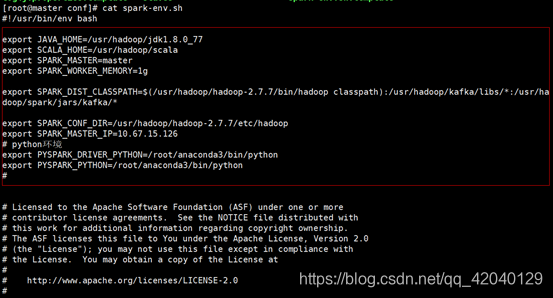
配置完成后 进入sbin目录并查看
3.7. 启动spark
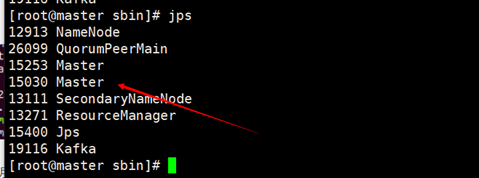
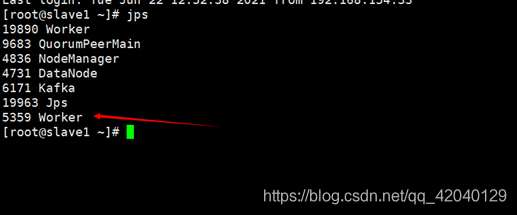
输入./start-all.sh启动spark进程
之后输入jps 查看进程
Master和worker是spark的进程 剩下的几个是hadoop的进程
所有只要有Master和Worker这两个进程 就说明Spark已经被启动了
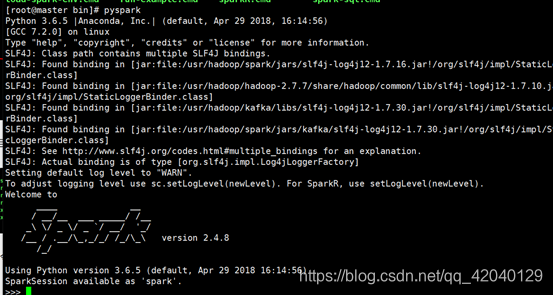
之后进入spark的bin目录查看

之后输入 ./pyspark 命令 出现此画面说明正常启动
5. 安装kafka
5.1. 下载kafka
https://kafka.apache.org/downloads
bash下载
wget https://downloads.apache.org/kafka/2.7.0/kafka_2.12-2.7.0.tgz
5.2. 解压
解压到指定文件夹
[root@master opt]# tar -zxvf kafka_2.12-2.7.0.tgz -C /usr/hadoop/
5.3. 修改文件权限
首先修改文件名字
cd /usr/Hadoop/
mv kafka_2.12-2.7.0 kafka
chmod -R 777 ./kafka
5.4. 启动kafka
– 启动Zookeeper
cd /usr/Hadoop/kafka
./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties
– 启动kafka
./bin/kafka-server-start.sh -daemon ./config/server.properties
– 停止kafka
./bin/kafka-server-stop.sh ./config/server.properties
5.5. 测试kafka
创建并查看topic
./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
./bin/kafka-topics.sh --list --zookeeper localhost:2181 test
5.6. 发送消息
./bin/kafka-console-producer.sh --broker-list 10.67.15.126:9092 --topic test

5.7. 接收消息
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning test

6. 安装python
6.1. 下载
去清华镜像站下载,上传到云端服务器上
清华镜像站:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
下载的版本见下,下载64位的Linux版本
6.2. 通过wget下载
wget https://repo.anaconda.com/archive/Anaconda3-5.2.0-Linux-x86_64.sh
6.3. 安装
进入自己的安装目录(上面已经提及),开始安装
cd /usr/local/Anaconda
bash Anaconda3-5.2.0-Linux-x86_64.sh
在安装的时候会碰到一路让你Enter和输入yes的过程
一路Enter和yes就完事了,碰到问你装不装Microsoft的VS code时直接No,就结束了全部的安装
中间安装的时候要注意anaconda3的安装路径,我的默认安装到了/root/anaconda3里面去了,
6.4. 环境配置
这时候你进入到安装目录下,键入conda -V没有任何反应
cd /root/anaconda3
conda -V

6.5. 利用vim将其打开进行编辑~
vim /etc/profice
6.6. 在其最后一行加入 export PATH=$PATH:【你的安装目录】
注意:刚刚提及要注意安装目录(这里要用到),我的为/root/anaconda3/bin

然后source /etc/profile
ok~到这里全部结束
6.7. 检验安装结果
输入:
conda -V
pip list
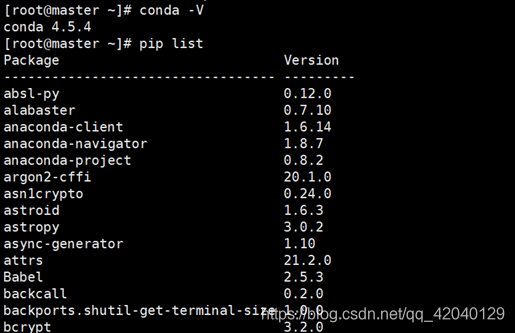
7. pycharm环境配置
7.1. 下载pycharm
下载地址
https://www.jetbrains.com/pycharm/
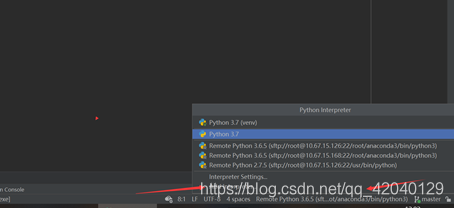
7.2. 安装并配置服务器远程环境实现同步操作
① 安装以后进入pycharm点击添加环境
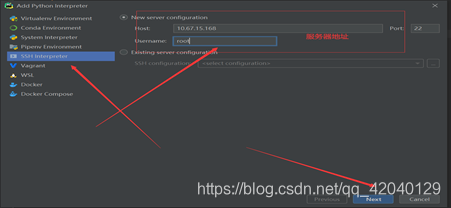
② 配置远程SSH环境
③ 配置服务器目录
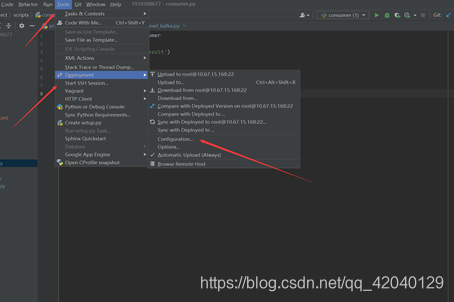
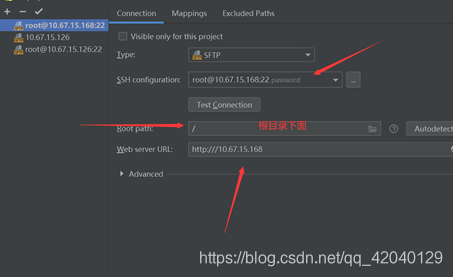
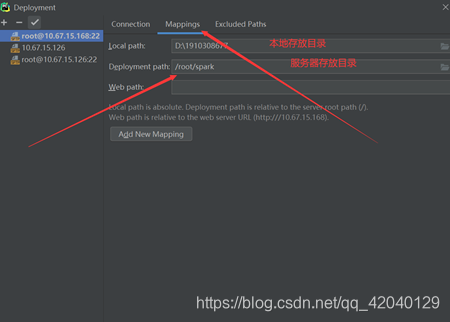
这样就就能配置成功了,我们可以实时同步代码了
8. Spark+kafka实时处理数据
详细分析下步骤:
1. 应用程序将购物日志发送给Kafka,topic为”sex”,因为这里只是统计购物男女生人数,所以只需要发送购物日志中性别属性即可。这里采用模拟的方式发送购物日志,即读取购物日志数据,每间隔相同的时间发送给Kafka。
2. 接着利用Spark Streaming从Kafka主题”sex”读取并处理消息。这里按滑动窗口的大小按顺序读取数据,例如可以按每5秒作为窗口大小读取一次数据,然后再处理数据。
3. Spark将处理后的数据发送给Kafka,topic为”result”。
4. 然后利用Flask搭建一个web应用程序,接收Kafka主题为”result”的消息。
5. 利用Flask-SocketIO将数据实时推送给客户端。
6. 客户端浏览器利用js框架socketio实时接收数据,然后利用js可视化库hightlights.js库动态展示。
(1) 首先利用python读取user_log.csv文件的gender值并传送到kafka,topic为”sex”中,代码如下:
import csv
import time
from kafka import KafkaProducer
# 实例化一个KafkaProducer示例,用于向Kafka投递消息
producer = KafkaProducer(bootstrap_servers='10.67.15.168:9092')
# 打开数据文件
csvfile = open("/root/spark/hadoop/data/user_log.csv","r", encoding='UTF-8')
# 生成一个可用于读取csv文件的reader
reader = csv.reader(csvfile)
for line in reader:
gender = line[9] # 性别在每行日志代码的第9个元素
if gender == 'gender':
continue # 去除第一行表头
time.sleep(0.1) # 每隔0.1秒发送一行数据
# 发送数据,topic为'sex'
# print(type(line))
print(line[9].encode('utf8'))
# 发送数据,topic为'sex'
producer.send('sex', line[9].encode('utf8'))
(2) 创建一个消费者来消费生产者“Sex”生成的数据
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
# print(type(msg))
print((msg.value).decode('utf8'))
(3) Spark Streaming实时处理数据
本项目在于实时统计每秒中男女生购物人数,而Spark Streaming接收的数据为1,1,0,2…,其中0代表女性,1代表男性,所以对于2或者null值,则不考虑。其实通过分析,可以发现这个就是典型的wordcount问题,而且是基于Spark流计算。女生的数量,即为0的个数,男生的数量,即为1的个数。
因此利用Spark Streaming接口reduceByKeyAndWindow,设置窗口大小为1,滑动步长为1,这样统计出的0和1的个数即为每秒男生女生的人数。
Spark准备工作
Kafka和Flume等高级输入源,需要依赖独立的库(jar文件)。按照我们前面安装好的Spark版本,这些jar包都不在里面,为了证明这一点,我们现在可以测试一下。请打开一个新的终端,然后启动spark-shell:
spark-shell
scala> import org.apache.spark.streaming.kafka010._
<console>:25: error: object kafka is not a member of package org.apache.spark.streaming import org.apache.spark.streaming.kafka010._ ^
你可以看到,马上会报错,因为找不到相关的jar包。然后我们退出spark-shell。
根据Spark官网的说明,对于Spark2.3.0版本,如果要使用Kafka,则需要下载spark-streaming-kafka-0-10_2.11相关jar包。现在请在Linux系统中,打开一个火狐浏览器,请点击这里访问Spark官网,里面有提供spark-streaming-kafka-0-10_2.11-2.3.0.jar文件的下载,其中,2.11表示scala的版本,2.3.0表示Spark版本号。下载后的文件会被默认保存在当前Linux登录用户的下载目录下,本教程统一使用hadoop用户名登录Linux系统,所以,我们就把这个文件复制到Spark目录的jars目录下。请新打开一个终端,输入下面命令:
mkdir /usr/hadoop/spark//jars/kafka
cp ./spark-streaming-kafka-0-10_2.11-2.3.0.jar /usr/hadoop/spark/jars/kafka
下面还要继续把Kafka安装目录的libs目录下的所有jar文件复制到“/usr/local/spark/jars/kafka”目录下,请在终端中执行下面命令:
cd /usr/hadoop/kafka/libs
ls
cp ./* /usr/hadoop/spark/jars/kafka
建立Spark项目
首先在/root/spark/hadoop/新建项目主目录kafka,然后在kafka目录下新建scala文件存放目录以及scala工程文件
mkdir -p /root/spark/hadoop/kafkatest/src/main/scala
接着在src/main/scala文件下创建两个文件,一个是用于设置日志,一个是项目工程主文件,设置日志文件为StreamingExamples.scala
因为我们配置了远程环境,所以我们直接在pycharm上面创建相应的文件直接上传服务器就可以了
日志处理
package org.apache.spark.examples.streaming
import org.apache.spark.internal.Logging
import org.apache.log4j.{Level, Logger}
/** Utility functions for Spark Streaming examples. */
object StreamingExamples extends Logging {
/** Set reasonable logging levels for streaming if the user has not configured log4j. */
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
// We first log something to initialize Spark's default logging, then we override the
// logging level.
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}
KafkaTest.scala
package org.apache.spark.examples.streaming
import java.util.HashMap
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.common.serialization.StringDeserializer
import org.json4s._
import org.json4s.jackson.Serialization
import org.json4s.jackson.Serialization.write
import org.apache.spark.SparkConf
import org.apache.spark.streaming._
import org.apache.spark.streaming.Interval
import org.apache.spark.streaming.kafka010._
object KafkaWordCount {
implicit val formats = DefaultFormats//数据格式化时需要
def main(args: Array[String]): Unit={
// 格式化日志
if (args.length < 3) {
System.err.println("Usage: KafkaWordCount <brokers> <groupId> <topics>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val Array(brokers, groupId, topics) = args
val sparkConf = new SparkConf().setAppName("KafkaWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
// 设置chackpoint
ssc.checkpoint("checkpoint")
// 创建消费者,从kafka获取数据供spark streaming做实时处理
// 新版本的kafka的参数设置
val topicsSet = topics.split(",").toSet
val kafkaParams = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
ConsumerConfig.GROUP_ID_CONFIG -> groupId,
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer])
// 创建数据源
val messages = KafkaUtils.createDirectStream[String, String](
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
// Get the lines, split them into words, count the words and print
val lines = messages.map(_.value)
val words = lines.flatMap(_.split(" "))//将输入的每行用空格分割成一个个word
// 对每一秒的输入数据进行reduce,然后将reduce后的数据发送给Kafka
// val wordCounts = words.map(x => (x, 1L)).reduceByKeyAndWindow(_+_,_-_, Seconds(1), Seconds(1), 1).print
// 对数据进行窗口截取做实时流分析
val wordCounts = words.map(x => (x, 1L))
.reduceByKeyAndWindow(_+_,_-_, Seconds(1), Seconds(1), 1).foreachRDD(rdd => {
if(rdd.count !=0 ){
val props = new HashMap[String, Object]()
// 提供brokers地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "10.67.15.168:9092")
// 指定key value中的value可序列化方式,因为网络传输
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
// 指定key value中的key可序列化方式,因为网络传输
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer")
// 实例化一个Kafka生产者
val producer = new KafkaProducer[String, String](props)
// rdd.colect即将rdd中数据转化为数组,然后write函数将rdd内容转化为json格式
val str = write(rdd.collect)
// 另一种将rdd转化成json的方法
// val json=rdd.collect().toList.map{case (word, count) =>(word, count)}
// val str=compact(render(json))
// println(rdd.collect.getClass().getName()) //Lscala.Tuple2;
// println(str)
// 封装成Kafka消息,topic为"result"
val message = new ProducerRecord[String, String]("result", null, str)
// 给Kafka发送消息
producer.send(message)
}
})
ssc.start()
ssc.awaitTermination()
}
}
上面代码注释已经也很清楚了,下面在简要说明下:
- 首先按每秒的频率读取Kafka消息;
- 然后对每秒的数据执行wordcount算法,统计出0的个数,1的个数,2的个数;
- 最后将上述结果封装成json发送给Kafka。
运行项目
编写好程序之后,下面介绍下如何打包运行程序。在/root/hadoop/kafkatest目录下新建文件simple.sbt,输入如下内容:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.8"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.3.0"
libraryDependencies += "org.apache.spark" % "spark-streaming_2.11" % "2.3.0"
libraryDependencies += "org.apache.spark" % "spark-streaming-kafka-0-10_2.11" % "2.3.0"
libraryDependencies += "org.json4s" %% "json4s-jackson" % "3.2.11"
然后,即可编译打包程序,输入如下命令
[root@master kafkatest]# /usr/hadoop/sbt/bin/sbt package

打包成功之后,接下来编写运行脚本,在/root/spark/hadoop/kafkatest目录下新建startup.sh文件,输入如下内容:
/usr/hadoop/spark/bin/spark-submit --driver-class-path /usr/hadoop/spark/jars/*:/usr/hadoop/spark/jars/kafka/* --class "org.apache.spark.examples.streaming.KafkaWordCount" /root/spark/hadoop/kafkatest/target/scala-2.11/simple-project_2.11-1.0.jar 10.67.15.168:9092 1 sex
其中最后四个为输入参数,含义如下
-
10.67.15.168:9092为brokerer地址
-
1 为consumer group标签
-
sex为消费者接收的topic
最后在/root/spark/hadoop/kafkatest目录下,运行如下命令即可执行刚编写好的Spark Streaming程序

[root@master kafkatest]# sh startup.sh
程序运行成功之后,下面通过之前的KafkaProducer和KafkaConsumer来检测程序。
测试程序
下面开启之前编写的KafkaProducer投递消息,然后将KafkaConsumer中接收的topic改为result,验证是否能接收topic为result的消息,更改之后的KafkaConsumer为
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
print((msg.value).decode('utf8'))
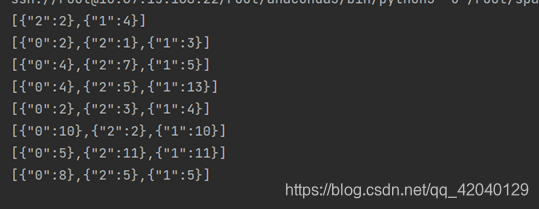
在同时开启Spark Streaming项目,KafkaProducer以及KafkaConsumer之后,可以在KafkaConsumer运行窗口,出现以下类似数据:
[{"0":4},{"2":4},{"1":6}]
[{"0":9},{"2":6},{"1":5}]
[{"0":10},{"2":5},{"1":3}]
[{"0":5},{"2":6},{"1":9}]
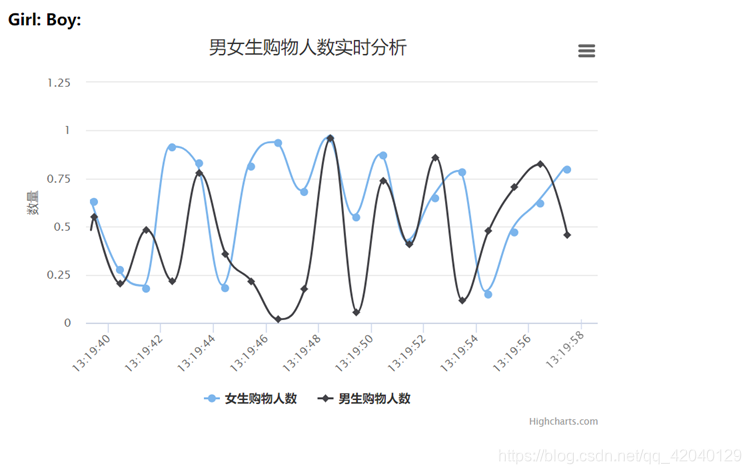
数据可视化
接下来做的事是,利用Flask-SocketIO实时推送数据,socket.io.js实时获取数据,highlights.js展示数据。
Flask-SocketIO实时推送数据
代码如下:index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>DashBoard</title>
<script src="static/js/socket.io.js"></script>
<script src="static/js/jquery-3.1.1.min.js"></script>
<script src="static/js/highcharts.js"></script>
<script src="static/js/exporting.js"></script>
<script type="text/javascript" charset="utf-8">
var socket = io.connect('http://' + document.domain + ':' + location.port);
socket.on('connect', function() {
socket.emit('test_connect', {data: 'I\'m connected!'});
});
socket.on('test_message',function(message){
console.log(message);
var obj = eval(message);
var result = obj["data"].split(",");
$('#girl').html(result[0]);
$('#boy').html(result[1]);
});
socket.on('connected',function(){
console.log('connected');
});
socket.on('disconnect', function () {
console.log('disconnect');
});
</script>
</head>
<body>
<div>
<b>Girl: </b><b id="girl"></b>
<b>Boy: </b><b id="boy"></b>
</div>
<div id="container" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
$(document).ready(function () {
Highcharts.setOptions({
global: {
useUTC: false
}
});
Highcharts.chart('container', {
chart: {
type: 'spline',
animation: Highcharts.svg, // don't animate in old IE
marginRight: 10,
events: {
load: function () {
// set up the updating of the chart each second
var series1 = this.series[0];
var series2 = this.series[1];
setInterval(function () {
var x = (new Date()).getTime(), // current time
count1 = $('#girl').text();
y = parseInt(count1);
series1.addPoint([x, y], true, true);
count2 = $('#boy').text();
z = parseInt(count2);
series2.addPoint([x, z], true, true);
}, 1000);
}
}
},
title: {
text: '男女生购物人数实时分析'
},
xAxis: {
type: 'datetime',
tickPixelInterval: 50
},
yAxis: {
title: {
text: '数量'
},
plotLines: [{
value: 0,
width: 1,
color: '#808080'
}]
},
tooltip: {
formatter: function () {
return '<b>' + this.series.name + '</b><br/>' +
Highcharts.dateFormat('%Y-%m-%d %H:%M:%S', this.x) + '<br/>' +
Highcharts.numberFormat(this.y, 2);
}
},
legend: {
enabled: true
},
exporting: {
enabled: true
},
series: [{
name: '女生购物人数',
data: (function () {
// generate an array of random data
var data = [],
time = (new Date()).getTime(),
i;
for (i = -19; i <= 0; i += 1) {
data.push({
x: time + i * 1000,
y: Math.random()
});
}
return data;
}())
},
{
name: '男生购物人数',
data: (function () {
// generate an array of random data
var data = [],
time = (new Date()).getTime(),
i;
for (i = -19; i <= 0; i += 1) {
data.push({
x: time + i * 1000,
y: Math.random()
});
}
return data;
}())
}]
});
});
</script>
</body>
</html>
App.py
import json
from flask import Flask, render_template
from flask_socketio import SocketIO
from kafka import KafkaConsumer
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
thread = None
# 实例化一个consumer,接收topic为result的消息
consumer = KafkaConsumer('result', bootstrap_servers='10.67.15.168:9092')
# 一个后台线程,持续接收Kafka消息,并发送给客户端浏览器
def background_thread():
girl = 0
boy = 0
for msg in consumer:
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
for data in data_list:
print(data)
if '0' in data.keys():
girl = data['0']
elif '1' in data.keys():
boy = data['1']
else:
continue
result = str(girl) + ',' + str(boy)
print(result)
socketio.emit('test_message', {'data': result})
# 客户端发送connect事件时的处理函数
@socketio.on('test_connect')
def connect(message):
print(message)
global thread
if thread is None:
# 单独开启一个线程给客户端发送数据
thread = socketio.start_background_task(target=background_thread)
socketio.emit('connected', {'data': 'Connected'})
# 通过访问http://127.0.0.1:5000/访问index.html
@app.route("/")
def handle_mes():
return render_template("index.html")
# main函数
if __name__ == '__main__':
# background_thread()
socketio.run(app, debug=True,host='0.0.0.0',port=5000)
实验结果:
代码顺序:
① Pycharm执行producer.py
② 服务器端执行sh startup.sh
③ pycharm执行consumer.py
④ Pycharm执行app.py
项目总结:
- Hadoop安装一定不要忘记要设置/etc/hosts文件,不然从节点起不来,设置hosts文件以后用hostnamectl set-hostname 设置主机名字,这样免密操作才能做成功!!!
- 安装spark的时候一定要注意与hadoop版本的兼容,我的spark-shell用自带的scala,pyspark配置了python环境,按照自己的需要搭建环境。python的版本和spark版本也要对应,spark2.1不支持python3.6。安装对应版本即可
- kafka构建集群模式的时候broker.id一定不要重复,重复kafka启动不了,安装kafka需要先启动zookeeper,如果以前安装过zookeeper,需要改zookeeper.properties文件,添加如下配置,当然如果觉得集群麻烦那就建立一个单机的也是可以用kafka的
- 安装conda环境其实是为了使用pycharm连接到远程的环境这样可以让我们更好的书写代码,就可以不用将代码或者数据上传到在服务器,在本地和服务器实现实时同步,或者安装jupyter通过web形势写python代码,也做上传文件代码,但需要配置文件路径。两个的原理都是一样的,都是使用服务器的python环境
- sbt是一款Spark用来对scala编写程序进行打包的工具,Spark 中没有自带 sbt,需要下载安装,安装完成后需要赋予sbt文件夹权限,最后在程序根目录下执行sbt package,第一次打包需要一些时间,多等等
- maven为了和sbt打包编译的内容进行区分,这里再为Maven创建一个代码目录“/sparkapp2”,并在“/kafkatest2/src/main/scala”下建立一个名为 SimpleApp.scala的Scala代码文件,放入和前面一样的代码在“~/kafkatest2”目录中新建文件pom.xml,这样添加相关依赖就可将程序打包成jar包


















 1848
1848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











