










以下文章来源于微信公众号“IC解惑君”,作者木飞
原文链接:漫谈AMBA总线-AHB(5)
前言:
随着进度一点点的推进,基本上到最后一系列关于AHB时序图讲解的章节了,在写AHB其他文章的时候,也先让别的同学提前审评过,有几个审评的同学说,写的太过啰嗦和冗余。AHB文章系列之后的文章会相对精炼一点点。同时也有同学说选择的AMBA-AHB协议太简单了,但是私以为AHB作为一个相对简单又基础的协议,已经包含了高级的协议很多基础的特性了,虽然AHB不如高级的协议有高级的一些操作和考虑,但是高级协议运行的基础AHB协议也体现了,所以AHB协议依旧还是值得一提。
正文1:
AHB章节最后再复习一遍多主机的概念:
总线是被总线上所有的部件所共享的一组通路(连线),对于支持多主机的总线,如果某一个主机想要与其他的部件进行通信(获得数据),首先需要向总线内部的仲裁器发起使用总线的请求,获得内部仲裁器授予所有权。其次需要将地址、数据、命令放到总线上,其他的从机部件对总线上的数据进行侦听,检查地址数据和命令是否与自己相关,最后相关从机部件做出命令响应。
如下图所示(场景模拟):自己对应相关的信号复习一下(漫谈AMBA总线-AHB)
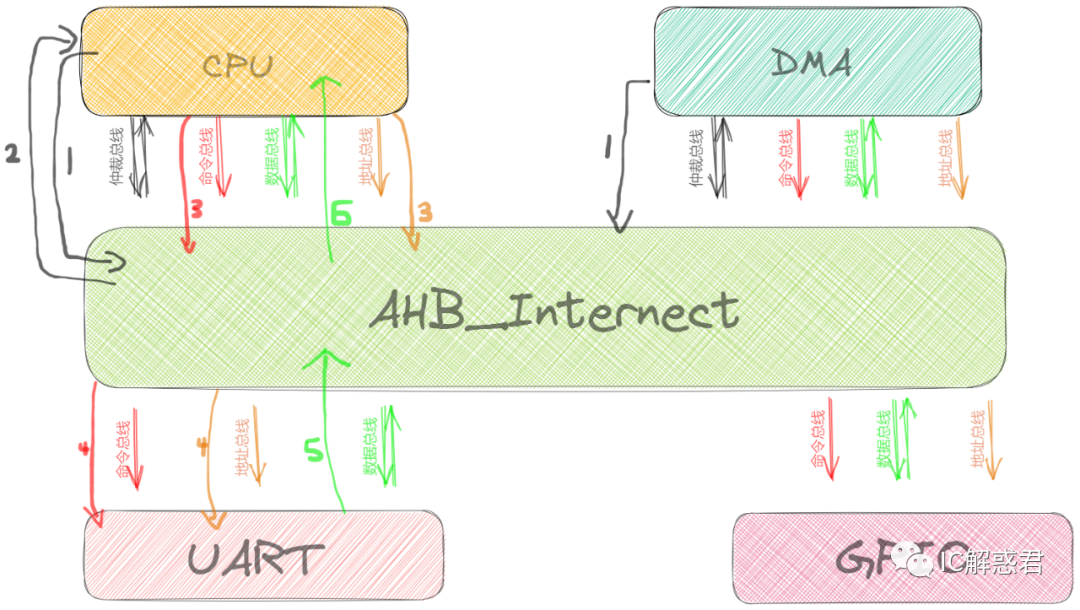
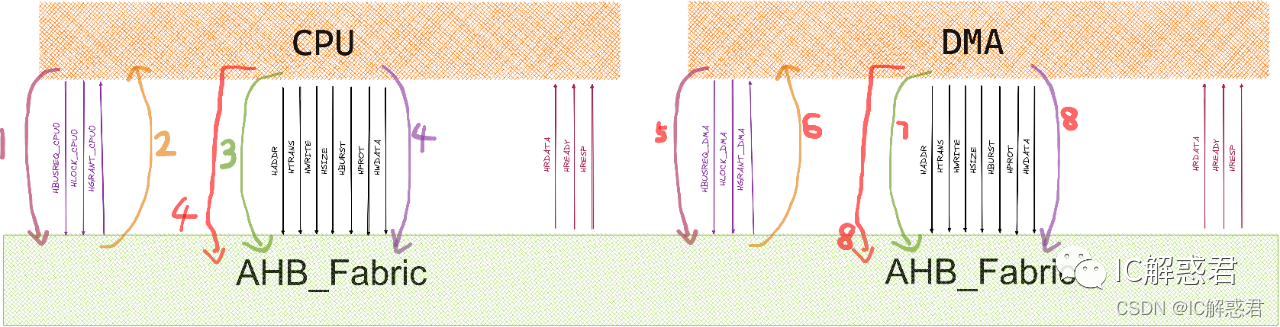
如上图所示,CPU和DMA同时向AHB_Interconnect申请获得总线所有权(1)。AHB_Interconnect(内部权衡)之后决定把总线授予给CPU,所以AHB_Interconnect应答了CPU申请总线的信号(2)。此时CPU已经知道自己获得了总线的授权,所以把自己需要访问的地址和命令放到总线上(3),通过CPU发出的地址范围,AHB_Interconnect把命令和地址路由(转发)到对应的UART从机(4),UART从机接收到主机发过来的命令,知道要进行读取自己内部寄存器的操作,所以自己把自己内部的数据放在数据总线上(5),再由AHB_Interconnect路由到对应的主机的数据总线接口,交付给主机(6)。
该模拟的操作完全把CPU的这次访问总线操作串行顺序起来,没有考虑效率。
总结上述AHB_Interconnect操作(重要):
(1)完成总线的授权与拒绝授权
(2)根据CPU发出的访问地址,把地址和命令路由(转发)到对应的从机接口(例如CPU -> UART)。
(3)主机发出的数据路由到刚才地址和命令所对应的从机接口;从机响应的数据路由到之前主机地址和命令对应的主机接口。(相当于地址和控制信息已经提前打好通路的开关,数据只要按着该通路进行流动就行)
PS:为什么所说上述的操作比较重要,因为对于AMBA AXI协议来说,其基本的路由规则也是如上图所示。也许会有同学说AXI的接口和AHB接口不一致,但是基本的思想都是一致,AXI为了更大效率的利用这个流程,设计了很多独有的提升性能的部分,此处按下不表,之后到漫谈AMBA AXI协议会详细说明。
PS:我们是否在上图模拟时发现,对于一个主机来说,操作是有先后顺序的。必须按照流程一步步走完才进行下一步,这样的话就要花费很长时间才能完成一次存取数据的操作。这样就意味着一次访问总线的Latency很长。
那么对于我们来说,想要减小这个总线的Latency:
(1)是否有一种方法是减弱其中的相关性?减少访问总线指令之间和访问总线指令内部的相关性?
(2)或者有一种方法是把这些前后顺序的操作做成流水线的形式?通过增大吞吐量的方式?
这两个问题之后在之后漫谈AXI协议里面还会重新提起。
PS:之前我们也说过,对比APB和AHB总线,AHB协议的效率更高。为什么效率更高?我们可以看到上图AHB_Interconnect在发出地址和命令时(4),主机这时候继续发出下一拍的地址和数据,这两次的地址和数据在时间上就重叠了起来,形成一种流水线机制,增大了总线的传输效率。
至少看来,AHB协议通过流水线操作增加了AHB总线的带宽(此处应该对比漫谈AMBA总线-APB)。
正文2:时序图分析:(所有时序图都来自AMBA AHB2.0手册)
1、单主机仲裁:
单主机单周期仲裁时序图:
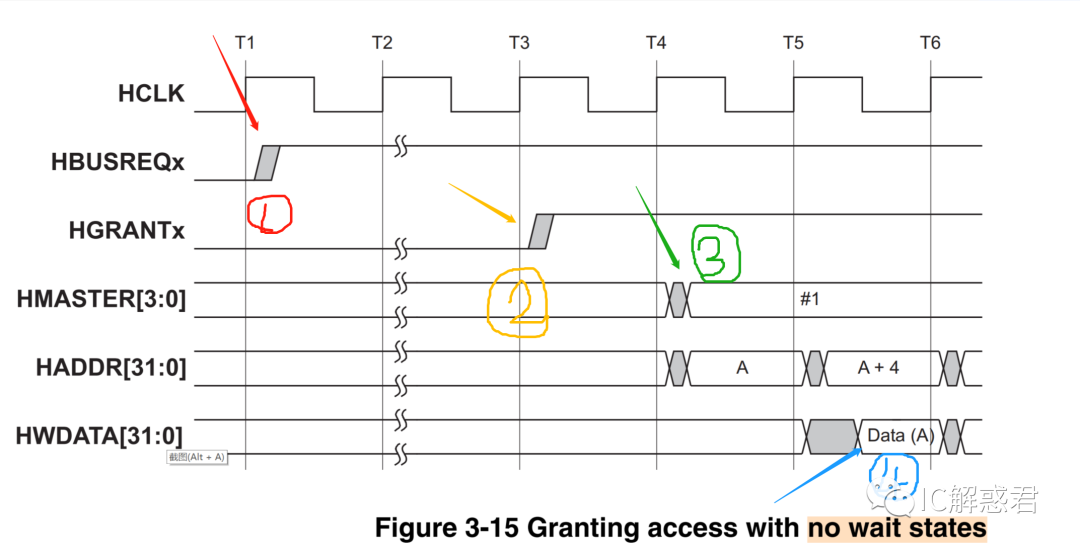
如上图所示:
(1)CPU先在(T1后)拉高HBUSREQx信号向AHB_Fabric申请使用总线(1)
(2)AHB_Fabric同意主机使用,所以在(T3后)拉高HGRANTx表示允许主机使用总线(2)。
(3)CPU收到AHB_Fabric返回的授权命令,于是就在T4周期后把自己想要控制的地址通过金属线发送到AHB_Fabric(3),在此周期内 AHB_Fabric把对应的地址和控制信号路由到Slave对应的接口上去。
(4)T5周期后,CPU既发出(A+4)的地址,又发出A地址所对应的数据[A](4)。在这个周期,也就是AHB比之APB体现性能的地方所在,分离地址和数据进行流水操作。
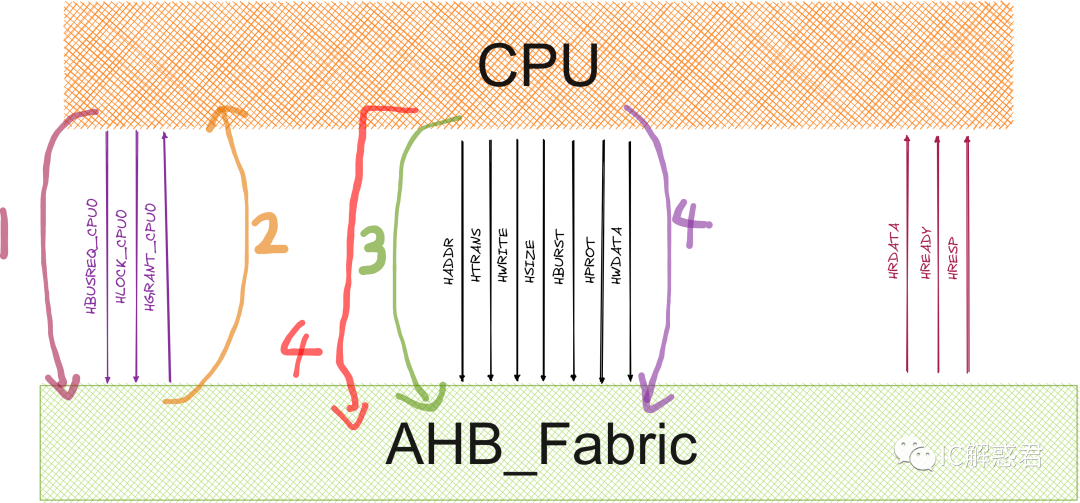
PS : HMASTER 信号: AHB_Fabric表示当前的哪个主机使用总线。
Q1: 可能有同学想问,为什么你没有画AHB_Fabric和从机的接口时序?
答:这里主要的目的就是为了表达一个观点:对于AHB_Fabric来说,它当前扮演的角色就是一个CPU的从机(因为CPU接口直接和AHB_Fabric连接),所以在传输数据的时候,CPU把数据交给AHB_Fabric之后就认为已经交付完成了(如果AHB_Fabric不返回错误或者不转发从机返回的错误)。
单主机多周期仲裁时序图:
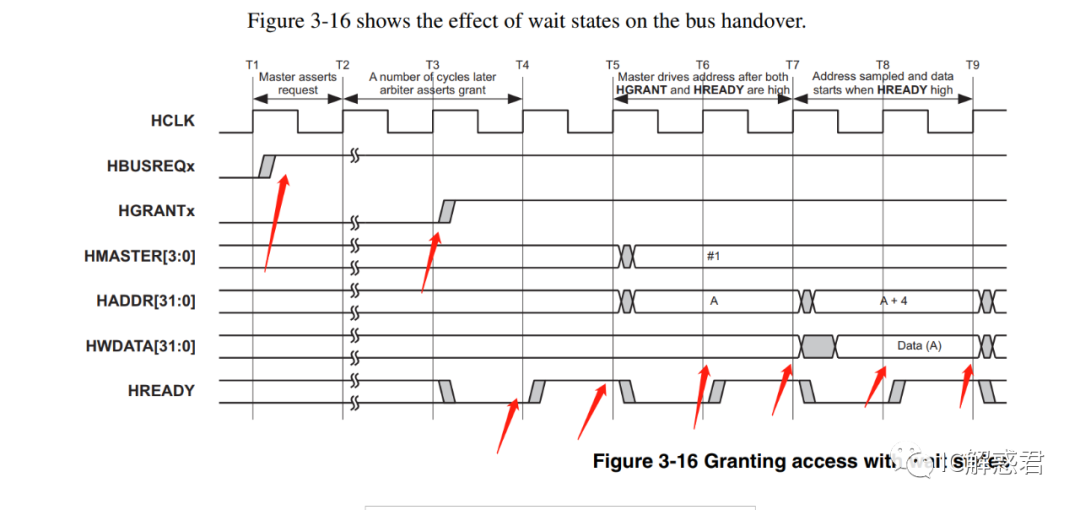
T1时刻:CPU拉高了HBUSREQx ,向AHB_Interconnect请求占有总线。
T3时刻:AHB_Internect回复CPU,授权CPU使用总线。
T4时刻:CPU收到AHB_Interconnect的授权信号(认为自己得到授权,准备占有地址和控制总线),准备发出地址和控制信号的时候,发现HREADY信号为低。参考之前文章(漫谈AMBA总线-AHB(2))的说法,HREADY信号为低,虽然CPU被授权总线了。但是,上一个主机传输卡住了(Transfer),所以当前主机只能等待上一个主机的传输完成。必须要注意:此时上一个主机还没有放弃地址和控制总线的所有权,同时此刻又把下一个地址和命令在总线上表示了(地址和数据的重叠)!(所以虽然CPU虽然得到授权信号,但是它还没有真正掌握到任何一部分总线)。
T5时刻:上一个主机的一个传输完成了,所以CPU可以发出自己的命令和地址了( CPU此时掌握地址和命令总线,但是数据总线还遗留着上一个主机在T4时刻发出的命令所对应的数据)。
T6时刻:CPU发出命令之后(地址A),发现HREADY信号为低。HREADY信号为低表示元传输没有完成(上一个主机的数据),所以此时CPU只能保持当前的状态一动不动(保持地址和控制信号)。
T7时刻:CPU收到HREADY信号为高,可以切换自己的状态(上一个主机完成了数据,释放了数据总线),发出下一个地址和控制信号(A+4)。同时发出上一次地址的数据(Data(A)),形成流水。
T8时刻:CPU发出命令之后(地址A+4),发现HREADY信号为低。HREADY信号为低表示元传输没有完成(本主机的数据),所以此时CPU只能保持当前的状态一动不动(保持地址和控制信号)。
T9时刻:CPU收到HREADY信号为高,可以切换自己的状态,发出下一个地址和控制信号(A+8)。同时发出上一次地址的数据(Data(A+4)),形成流水。
ps:我们会发现上一个主机的传输(元操作)会影响到总线切换后的主机,这个算不算AHB的一个缺点呢?
2、多主机仲裁:
多主机轮转时序图:
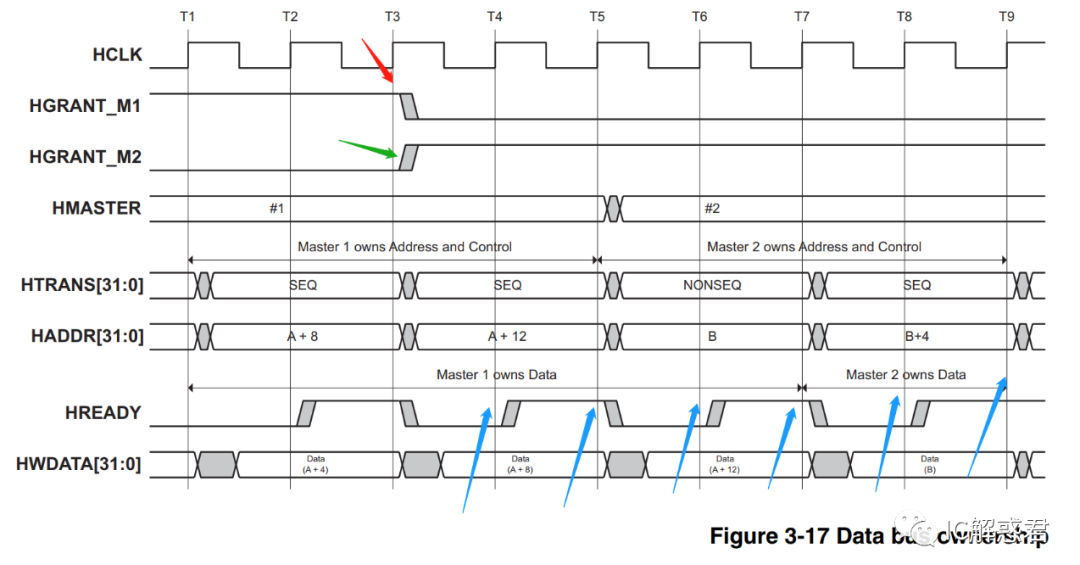
T3时刻后:因为一些原因(其他主机争权)AHB_Internect取消M1主机的授权,所以拉低了授权信号(HGRANT_M1 = 0),同时授权了M2主机使用总线,拉高了授权信号(HGRANT_M2 = 1)。
T4时刻: 主机M1已经知道自己被取消了授权,所以主机M1之后不会在T4时刻之后发起新的传输了,但是需要把当前的传输传输完毕(因为M1当前的传输命令发出的时候正好接到被取消授权,T3时刻),同时M1主机发现HREADY为低(知道自己当前的数据被卡Data(A+8)),所以保持当前地址控制状态(A+12)。
主机M2知道自己被授权了,但是发现HREADY为低,知道上一个主机的数据还在卡着,所以自己不用发出地址命令(等待主机M1释放地址和控制总线)。
T5时刻: 主机M2知道主机M1的数据已经正确接收(同时释放了地址和控制总线(B + NONSEQ),此时主机M2发出自己的命令和控制信号。
T6时刻: 主机M2已经发出自己地址和命令,此时发现发现HREADY为低,知道上一个主机的数据传输还在卡着(Data(A+12)),于是自己保持当前发出地址和命令当前的状态(B + NONSEQ)。等待上一个主机的最后一个数据交付。
T7时刻: 主机M2发现发现HREADY为高,知道上一个主机的数据已经处理完毕(释放了数据总线)。接下来可以发出主机M2的数据和主机M2的下一拍的地址和命令信息。
多主机仲裁时序图:
多主机轮转:
多主机轮转时序图:
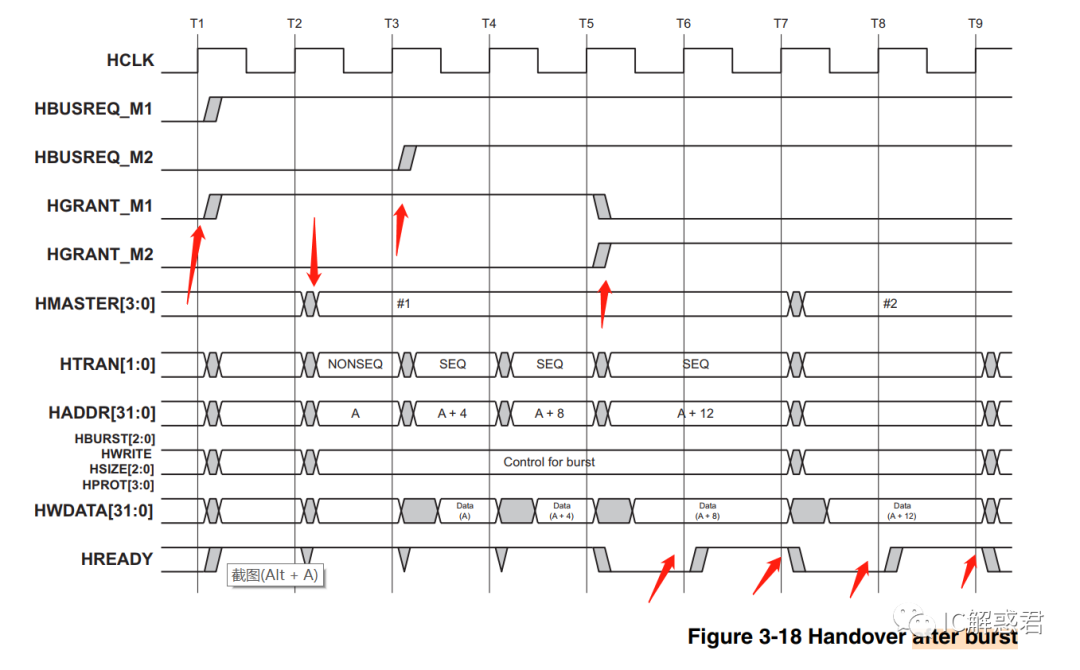
T3时刻之前:M1主机获得总线,使用总线传输数据
T3时刻:M2主机想要使用总线,所以向AHB_Interconnect发起总线的使用权请求。此时主机M1正在使用总线传输数据。
T5时刻:仲裁器觉得给M1主机使用总线的时间已经足够长,于是要取缔其使用总线的权利。同时准备授予M2主机使用总线。
T6时刻:主机M1接收到AHB_Interconnect取消其使用总线的请求,所以其T6时刻之后不会再发新命令(当然T6时刻之前已经发出命令不能取消了,因为已经被发出到总线)。主机M2已经收到AHB_Interconnect授权总线的请求了,但是当前其虽有授权,但是还是没有真正掌握总线。(上一个主机的数据传输阻塞数据总线 HREADY = =0)
T7时刻:上一个主机的数据成功传输(Data(A+8))释放了主机M1占有的地址和控制总线,所以此时主机M2就开始占有地址和控制总线了。所以主机M2把其想操作的地址和命令发送到地址和控制总线上。
T8时刻:上一个主机的遗留数据传输卡着总线 (HREADY = =0),此时主机M2还不能进一步掌握数据总线。所以只能保持当前的状态等待上一个主机接收数据释放数据总线。
T9时刻:上一个主机数据传输完成,释放了数据总线(Data(A+12)),进而主机M2进一步掌握了数据总线,把自己需要的数据放到数据总线上来进行一次完整的传输。
PS:从上面,我们可以明显看出,总线的移交是两个阶段完成的:
首先第一步移交地址和控制总线,
其次第二步移交数据总线。
总线移交的每一步都需要考虑到上一个主机的感受(即数据的传输!)。
下文:
总线移交后的基本传输
总线移交后突发传输等















 5635
5635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









