







1.要求与环境
1.1 数据分析要求
- 数据的加载与集成
- 平均分较高的电影
- 不同性别对电影平均评分
- 不同性别争议最大电影
- 评分次数最多热门的电影
- 不同年龄段争议最大的电影
1.2 操作环境
- python 3+
- Jupyter notebook
- Window 系统
1.3 数据来源
资料下载:https://pan.baidu.com/s/1lLxy4A3vXPHHDGBuLVQUug
提取码:rduk
2.数据加载与集成
2.1 相关包
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
2.2 导入数据
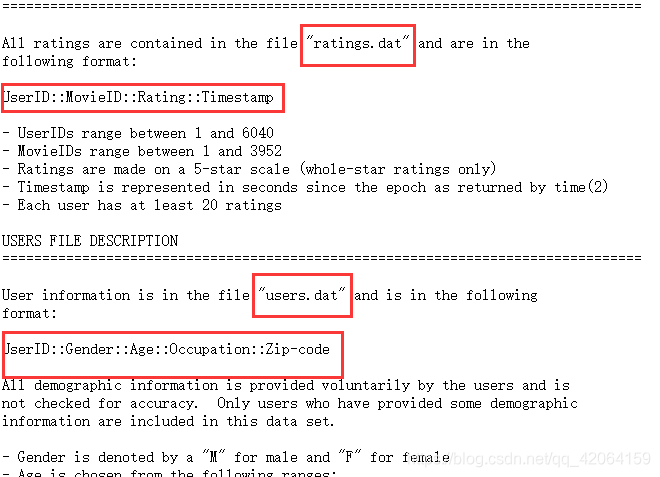
- 打开下载的压缩包,解压出来,会看到有四个文件,其中三个.dat 数据,一个是数据的说明文档(README),我们可以直接把它们分别拖进浏览器打开查看,如我打开README文件,查看其他三个文件的表头。
- 在里面我们可以看到三个文件的信息,字段的分隔符是“::”
2.2.1 读取用户数据
# UserID::Gender::Age::Occupation::Zip-code
userlabels = ['UserID', 'Gender', 'Age', 'Occupation', 'Zip-code']
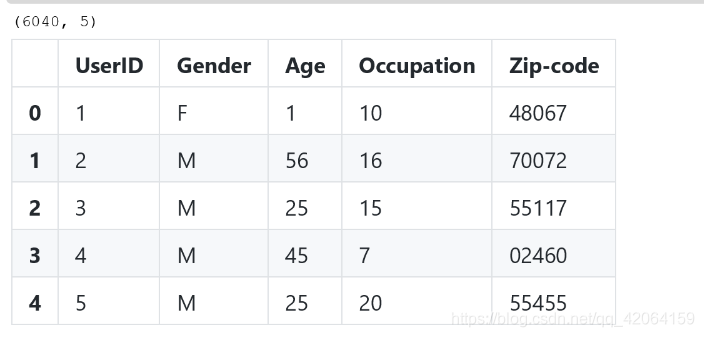
users = pd.read_csv('F:/study/数据分析/users.dat', sep='::', header=None, names=userlabels, engine='python')
users.shape
users.head()
查看前五行数据
2.2.2 读取电影数据
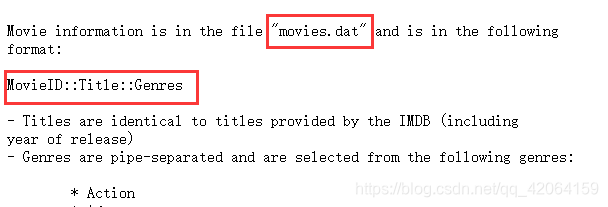
# MovieID::Title::Genres
movlabels = ['MovieID', 'Title', 'Genres']
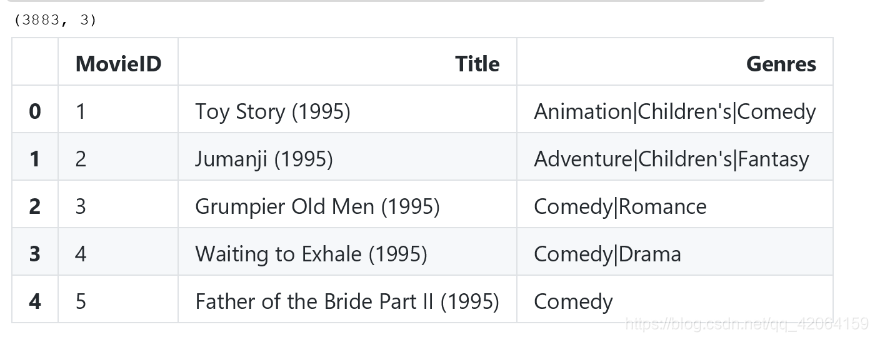
movies = pd.read_csv('F:/study/数据分析/movies.dat', sep="::", header=None, names=movlabels, engine='python')
print(movies.shape)
movies.head()
查看前五行数据
2.2.3 读取评分数据
# 读取评分
# UserID::MovieID::Rating::Timestamp
labels = ['UserID', 'MovieID', 'Rating', 'Timestamp']
ratings = pd.read_csv('F:/study/数据分析/ratings.dat', sep="::", header=None, names=labels, engine='python')
print(ratings.shape)
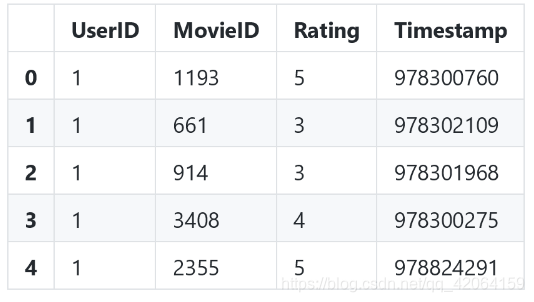
ratings.head()
查看前五行
2.3 数据集成
- 数据分布于三个表,可以将数据合并到一个表;数据合并专业词汇,数据集成。
- 先合成有共同列MovieID的两个数据,movies和ratings。
# 数据集成
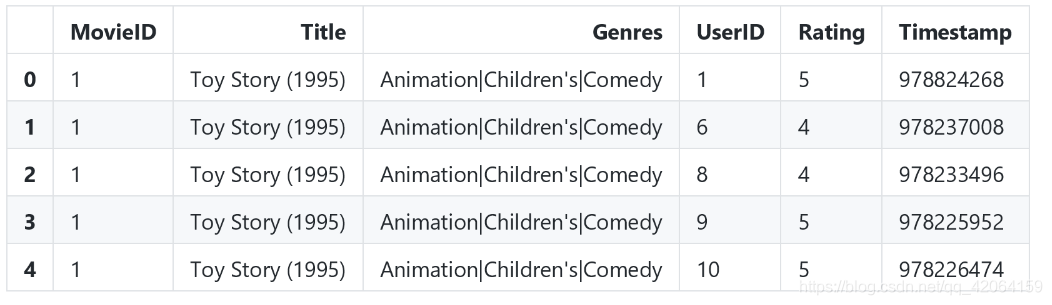
df = pd.merge(left=movies, right=ratings)
df.head()
查看movies和ratings集成后的前五列
在集成df和users
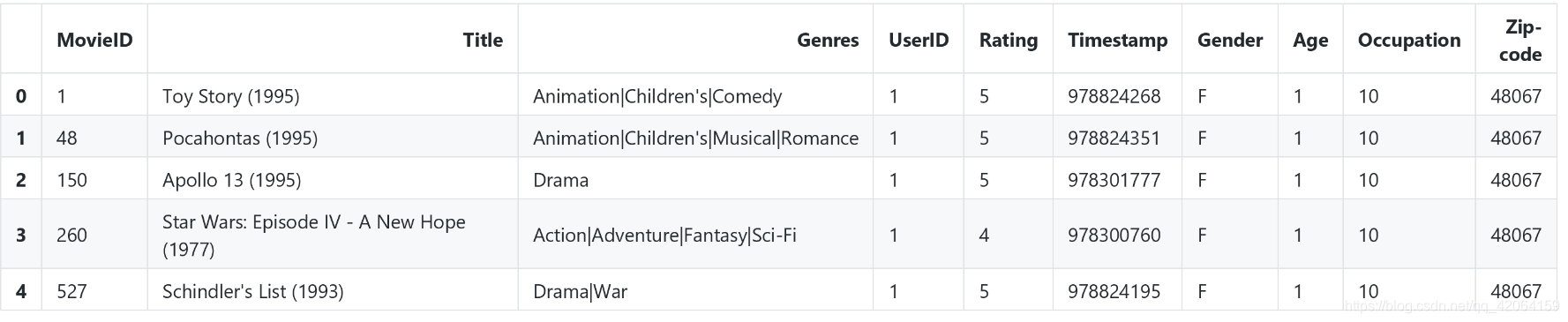
movie_data = pd.merge(df, users)
movie_data.head()
查看集成后前五行数据
去重
- 查看去重前数据形状
movie_data.shape
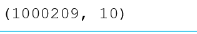
- 去重
# 去重
movie = movie_data['Title'].unique()
print(movie.size)
去重后大小

3.平均分较高的电影
- 调用透视表
# 调用透视表
movie_rat_mean = pd.pivot_table(movie_data, values=['Rating'], index=['Title'], aggfunc='mean')
movie_rat_mean.shape

- 查看前五条数据
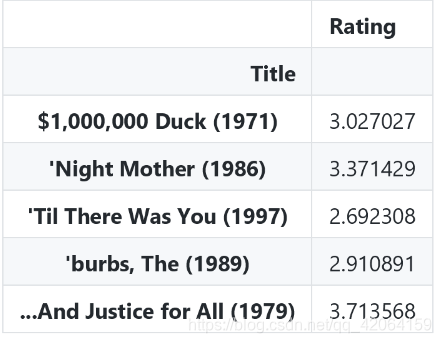
movie_rat_mean.head()
- 排序
# 排序
movie_rat_mean.sort_values(by='Rating', ascending=False, inplace=True)
- 查看前十条数据
# 查看前10
movie_rat_mean[: 10]
# movie_rat_mean.head(10)

- 查看后十条数据
# 查看后10
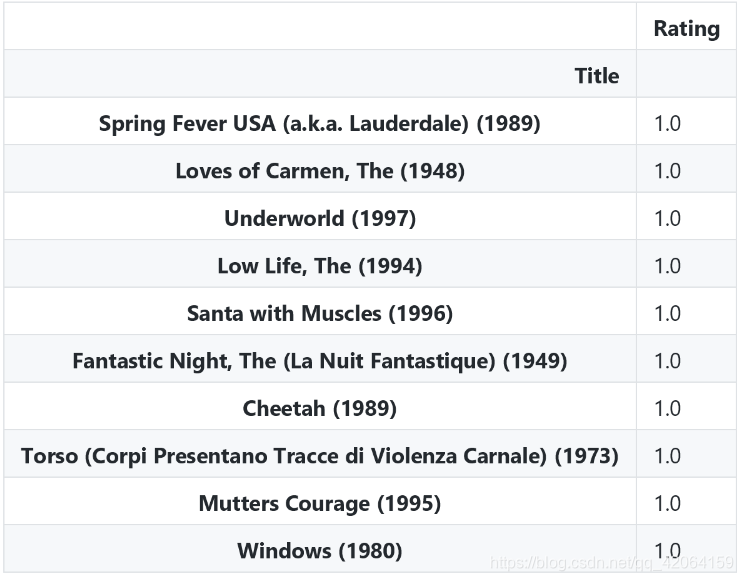
movie_rat_mean.tail(10)
# movie_rat_mean[: 10]
4.不同性别对电影平均评分
- 方法一
# 方法一
movie_sex_rating_mean = pd.pivot_table(movie_data, values=['Rating'], index=['Title', 'Gender'], aggfunc='mean')
movie_sex_rating_mean.shape
查看数据
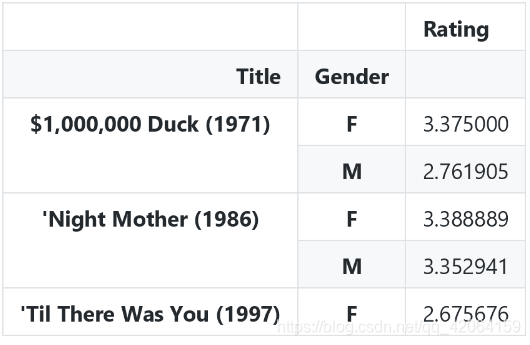
movie_sex_rating_mean.head()
- 方法二
movie_gender_rating_mean = pd.pivot_table(movie_data, values='Rating', index=['Title'], columns=['Gender'], aggfunc='mean')
movie_gender_rating_mean.shape
查看数据
5.不同性别争议最大电影
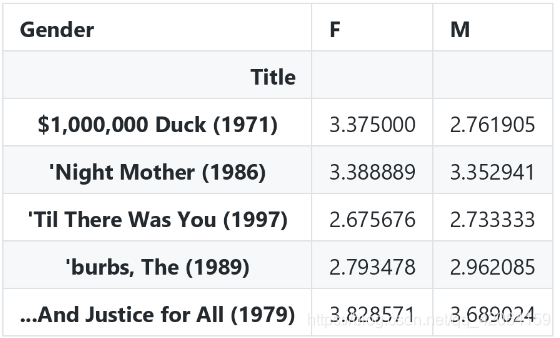
- 原理: 用女性的评分减去男性的评分得出它们评分得差距
- 评分差距
# 评分差距
movie_gender_rating_mean['diff'] = movie_gender_rating_mean['F'] - movie_gender_rating_mean['M']
movie_gender_rating_mean.head()
查看前五条数据
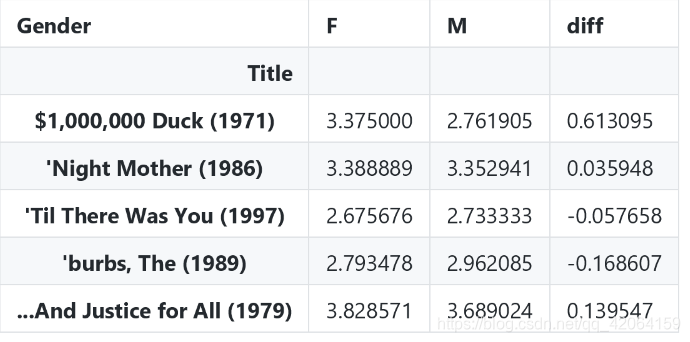
- 排序
# 排序
movie_gender_rating_mean.sort_values(by='diff', ascending=False, inplace=True)
- 女性用户和男性用户差异最大,前面为正,女性用户最喜欢的前10个
查看前十条数据
movie_gender_rating_mean[: 10]
- 女性用户和男性用户差异最大,后面为负,男性用户最喜欢的前10个,也就是倒数10个
查看后十条数据
movie_gender_rating_mean[-10: ]
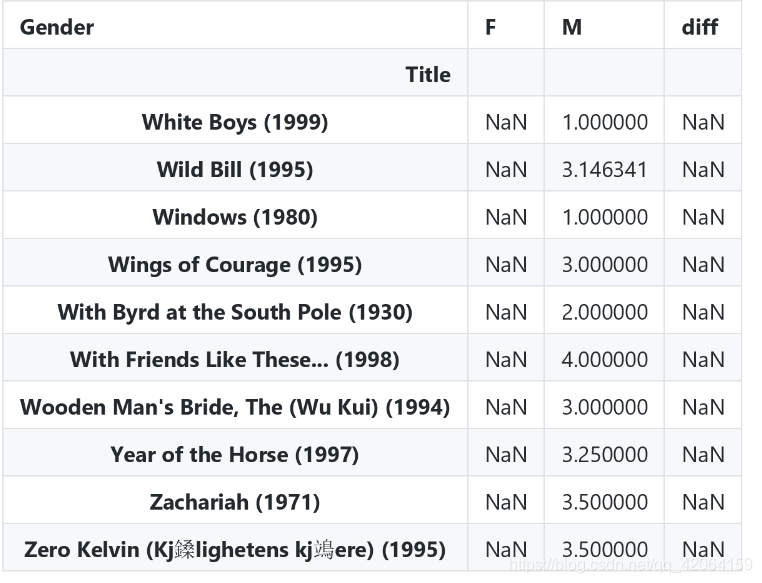
出现空值的原因: 由于有写电影女性不观看和不评论,所以出现空值,需要去掉空值再查看数据。
movie_gender_rating_mean.dropna()[-10: ]
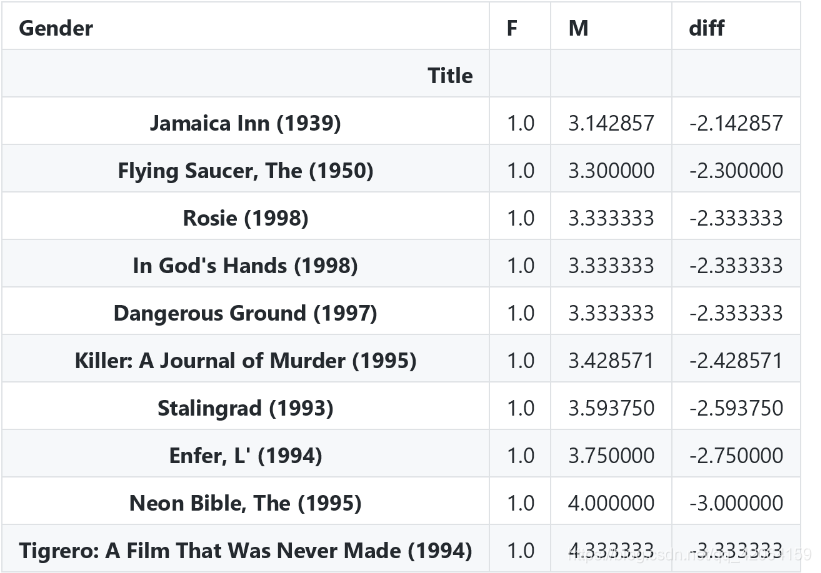
- 男女数据联集
f = movie_gender_rating_mean['F']
m = movie_gender_rating_mean['M']
diff = pd.concat([f, m])
- 分析结果
# 数据可视化
diff.plot(kind='barh')
6.评分次数最多热门的电影
6.1 分组运算
# 统计电影名出现的次数
rating_count = movie_data.groupby(['Title']).size()
rating_count

6.2 排序
rating_count.sort_values(ascending=False)

7.不同年龄段争议最大的电影
7.1 查看用户的年龄分布情况
- 直方图
movie_data['Age'].plot(kind='hist', bins=20)
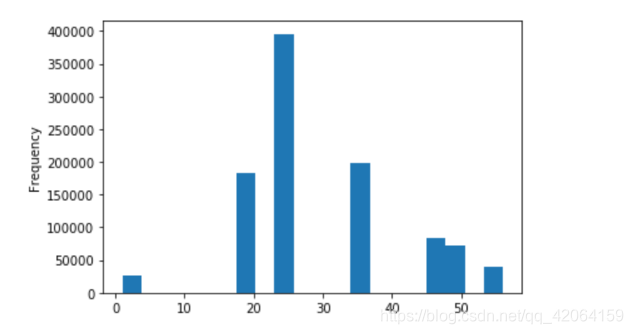
- 求最大值
movie_data.Age.max()
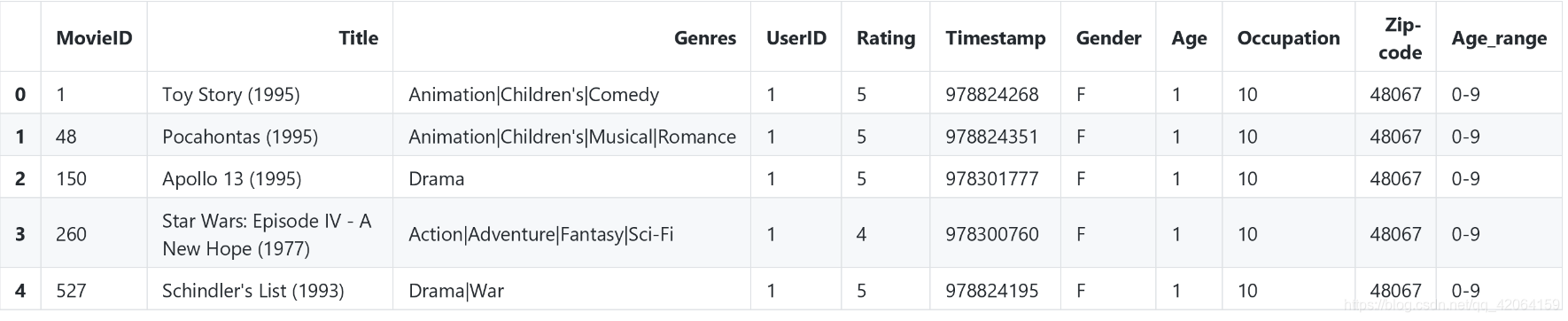
7.2 用pandas.cut()函数将用户年龄分组
labels = ['0-9', '10-19', '20-29', '30-39', '40-49', '50-59']
movie_data['Age_range'] = pd.cut(movie_data['Age'], bins=range(0, 61, 10), labels=labels)
movie_data.head()
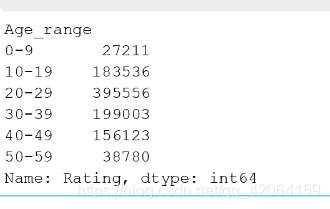
7.3 每个年龄段用户评分人数和打分偏好
7.3.1 年龄范围评分的平均分
# 年龄范围评分的平均分
movie_data.groupby('Age_range')['Rating'].mean()

7.3.2 年龄范围评分的人数
# 年龄范围评分的人数
movie_data.groupby('Age_range')['Rating'].size()
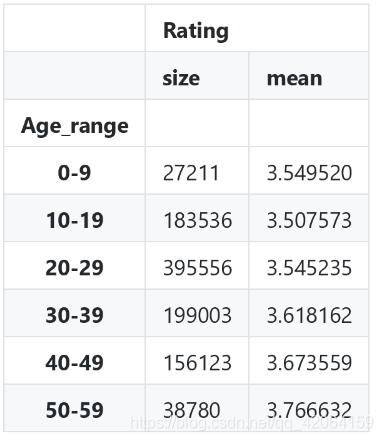
7.3.3 同时求每个年龄段评分人数及平均分
# 同时求每个年龄段评分人数及平均分
movie_data.groupby('Age_range').agg({'Rating': [np.size, np.mean]})
8.优化数据
问题: 为什么后很多平均分高的电影,我们没有看过,甚至没有听到过呢?这并不符合常理,因为好的电影总会口口相传的,说明其中有些数据是有问题的
movie_rat_mean[: 10]
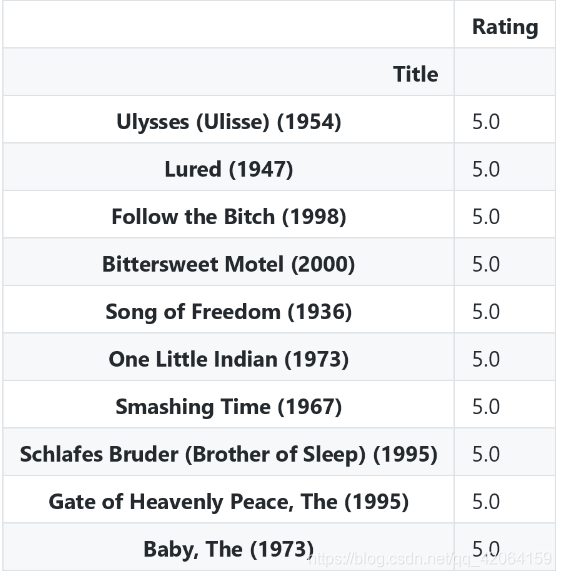
这是为什么? 因为评分次数相差悬殊,看的人少,少数人评分反而很高
解决方案:
- 加入评分次数限制来分析不同性别对电影的平均评分
- 加入评分次数限制来分析平均分高的电影
8.1 加入评分次数限制来分析不同性别对电影的平均评分
8.1.1 建立索引
#以Title进行分组,统计次数大小,排序,数据反转,前50列,索引
top_movie_title = movie_data.groupby('Title').size().sort_values()[::-1][:50].index
top_movie_title.size
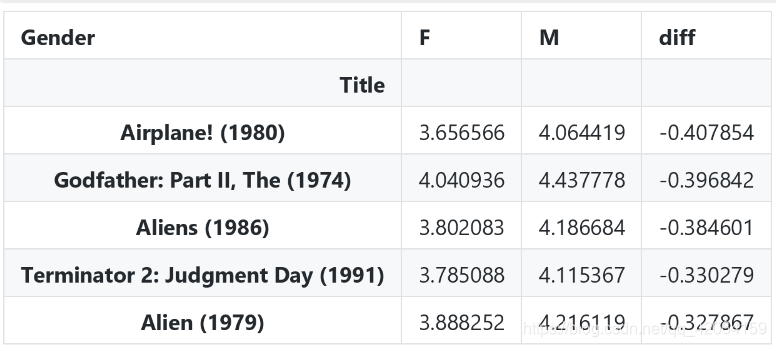
8.1.2 找出上面的数据
flag = movie_gender_rating_mean.index.isin(top_movie_title)
df1 = movie_gender_rating_mean[flag].sort_values(by='diff')
df1.head()
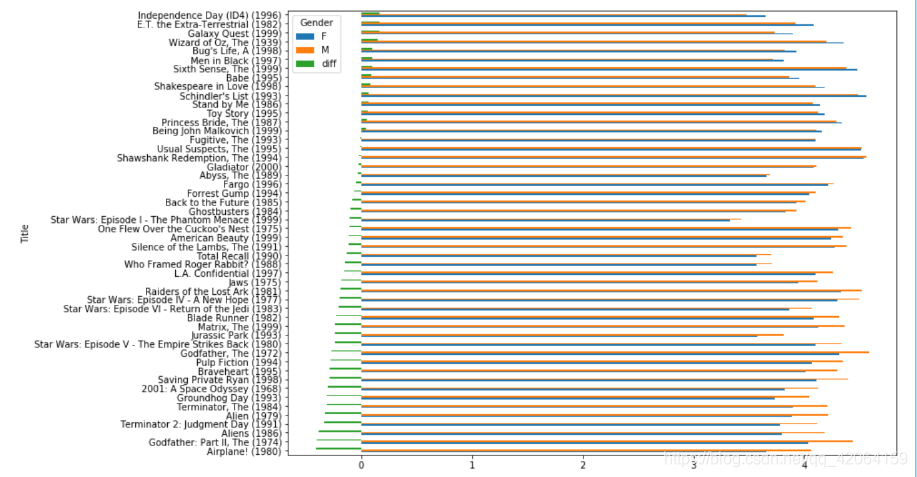
8.1.3 结果可视化
df1.plot(kind='barh', figsize=(12, 9))
8.2 加入评分次数限制来分析平均分高的电影
8.2.1 建立索引
index = movie_data.groupby('Title').size().sort_values()[::-1][:50].index
index.shape

8.2.2 索引出符合条件的数据
flag = movie_rat_mean.index.isin(index)
# 热门电影平均分
movie_rating_top_mean = movie_rat_mean[flag]
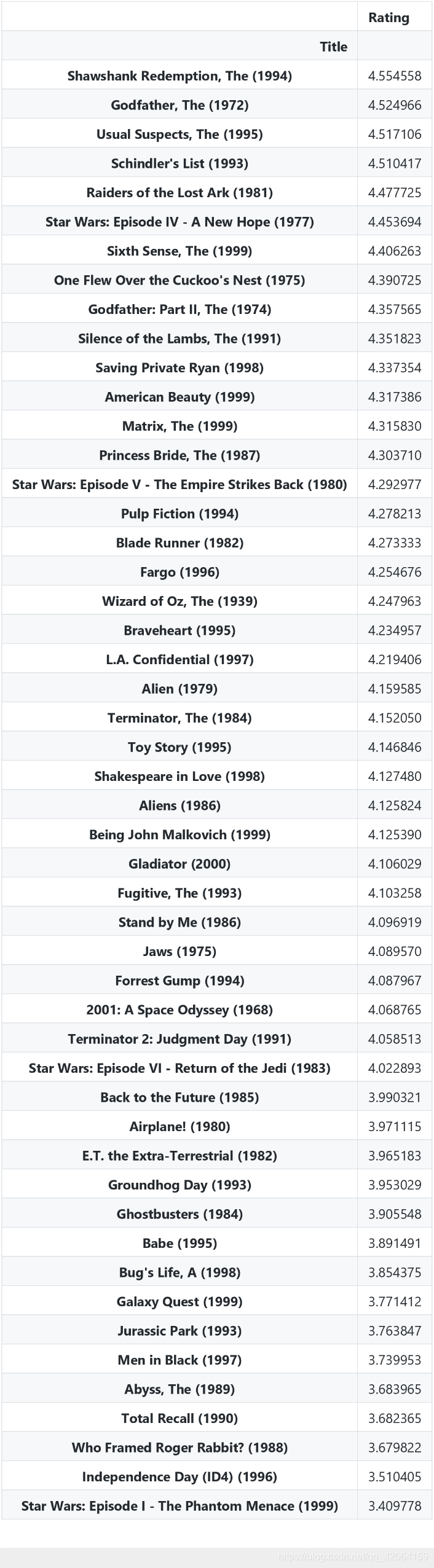
movie_rating_top_mean.sort_values(by='Rating', ascending=False)














 8623
8623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









