







 本文介绍使用Python和requests库从汽车之家网站爬取贵阳地区二手车信息的方法,包括分析网页结构、提取关键数据并保存至Excel文件的过程。
本文介绍使用Python和requests库从汽车之家网站爬取贵阳地区二手车信息的方法,包括分析网页结构、提取关键数据并保存至Excel文件的过程。
python+requests爬取汽车之家贵阳二手车信息
目录
- 分析网页
1.1. 打开网页,获取请求路径
1.2. 找到自己需要的信息 - 提取数据
2.1 定位元素,找到数据
2.2 处理数据,将数据封装成数组
2.3 保存到excel表格中 - 源码展示
3.1 源码及优化
1.分析网页
1 打开网页,获取请求路径
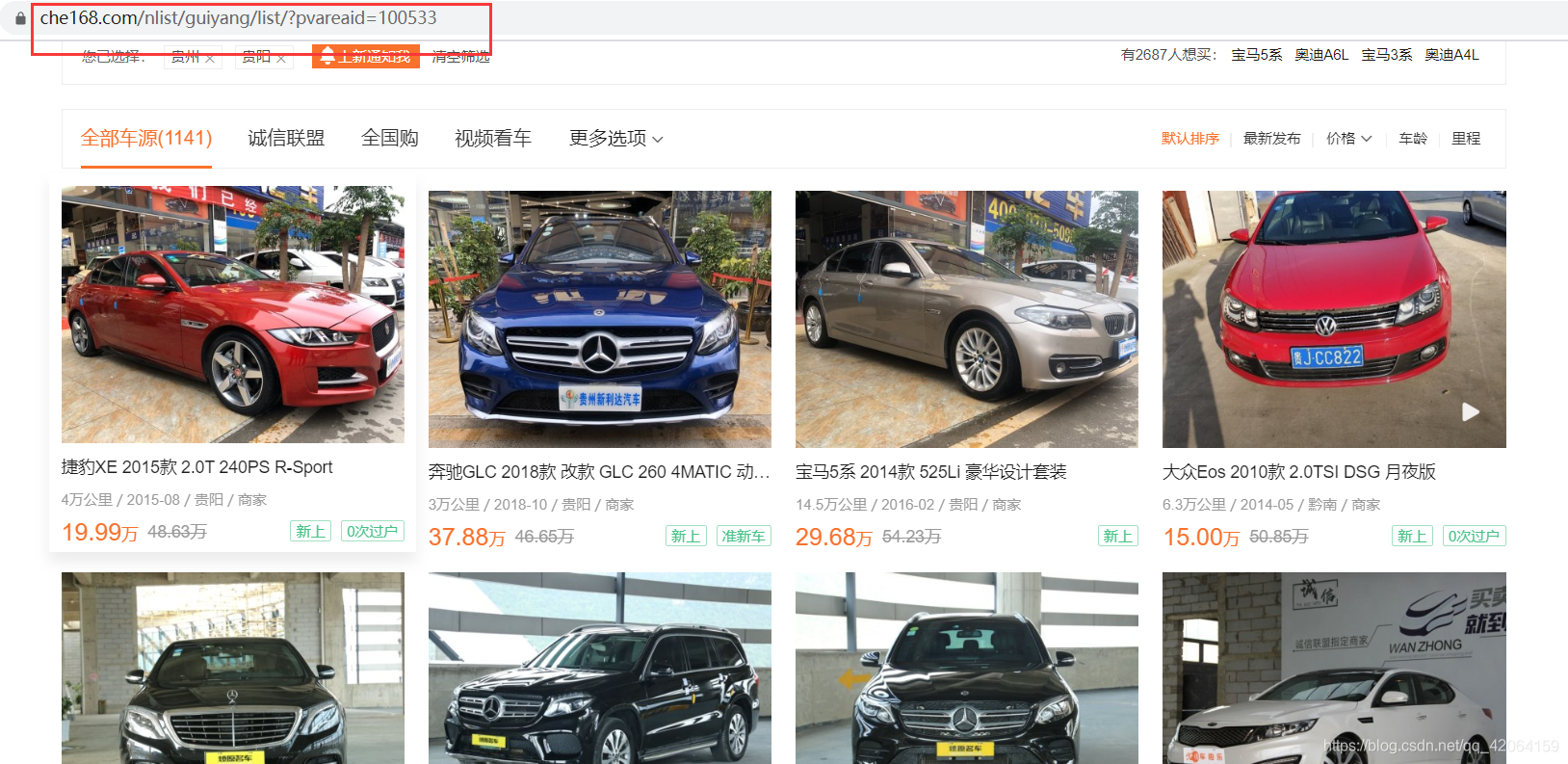
于是请求路径为:
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.che168.com/nlist/guiyang/list/?pvareaid=100533')
print(html.text)
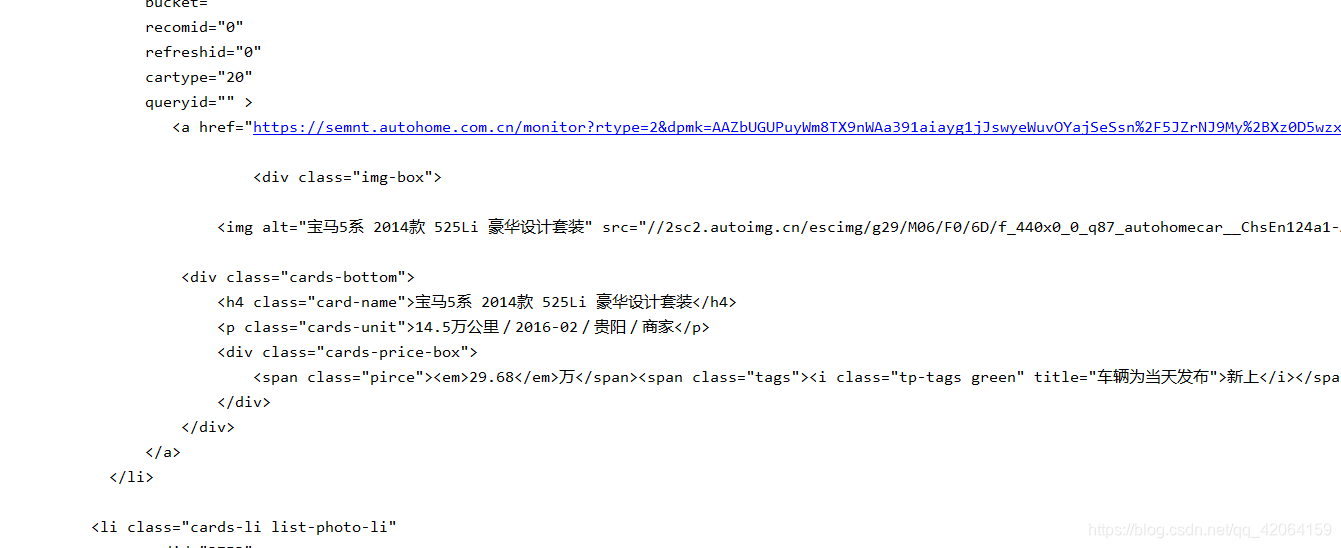
2 找到自己需要的信息
在页面上:右键->检查 或者 直接按f12
点击图片上红框的按钮,定位自己需要的信息
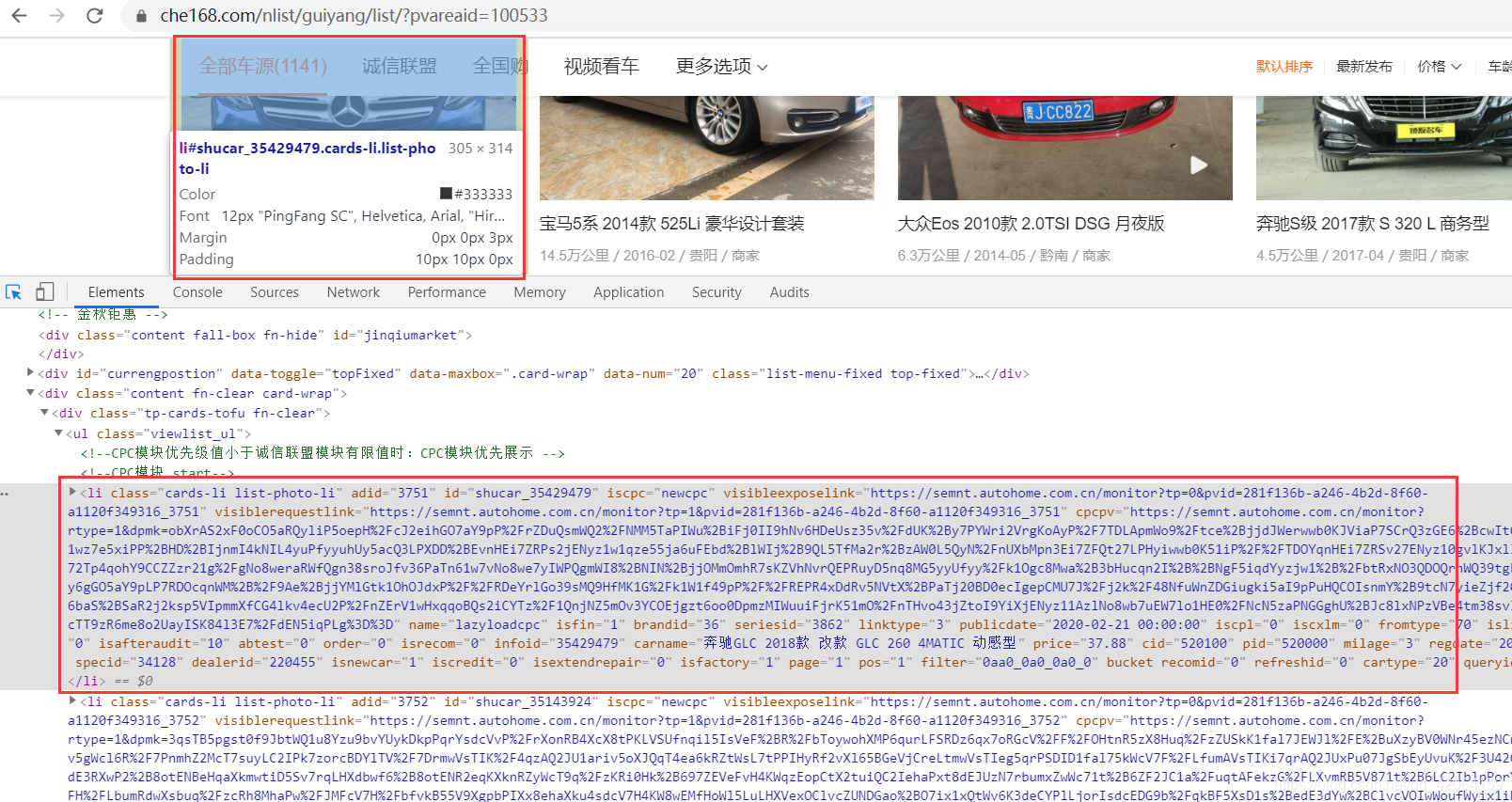
找到对应信息,去页面查询是否是异步加载
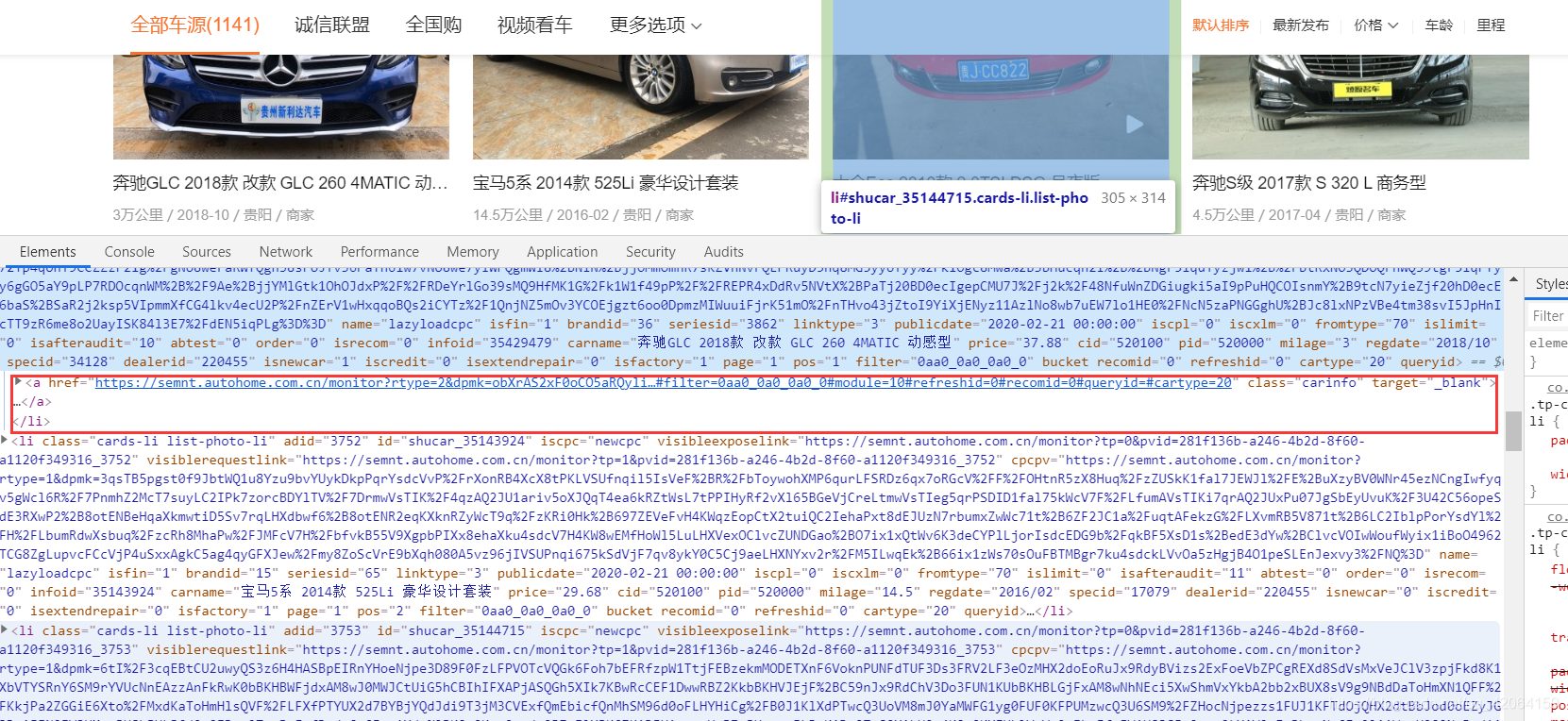
在打印的代码中我们找到了我们要的信息
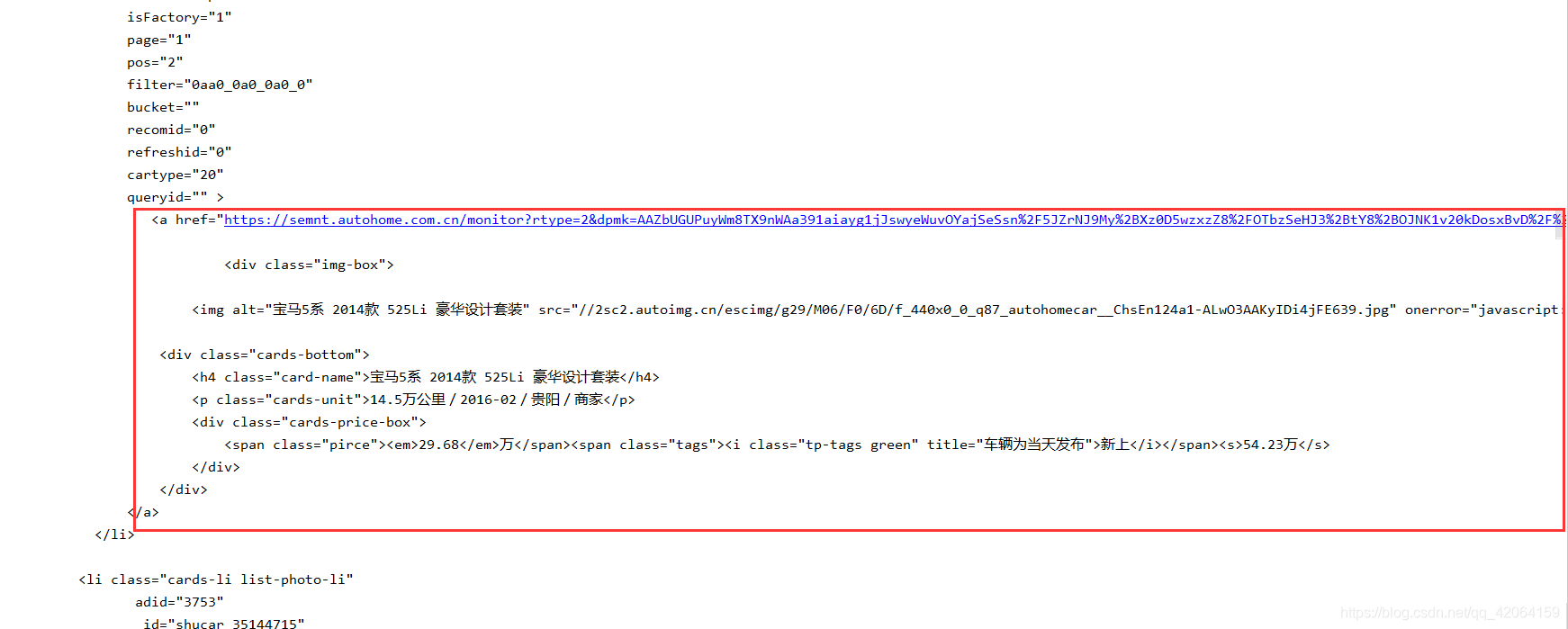
到这里就可以笑了,因为这不是异步加载,我们可以直接拿数据了
2.提取数据
- 定位元素,找到数据
将元素定位到上面我们找到的a标签下carinfo
代码:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html.text, 'html.parser')
lists = soup.select('a.carinfo')
for data in lists:
print(data.text)
结果如下

- 处理数据,将数据封装成数组
lists = soup.select('a.carinfo')
result = []
arr = []
arr2 = []
for data in lists:
name = data.select_one('h4').text
car = data.select_one('p').text
price = data.select_one('span').text
value = data.select_one('s').text
string = name + ',' + car + ',' + price + ',' + value
arr = string.split(',')
print(arr)
result.append(arr)
print(result)
运行代码查看结果:
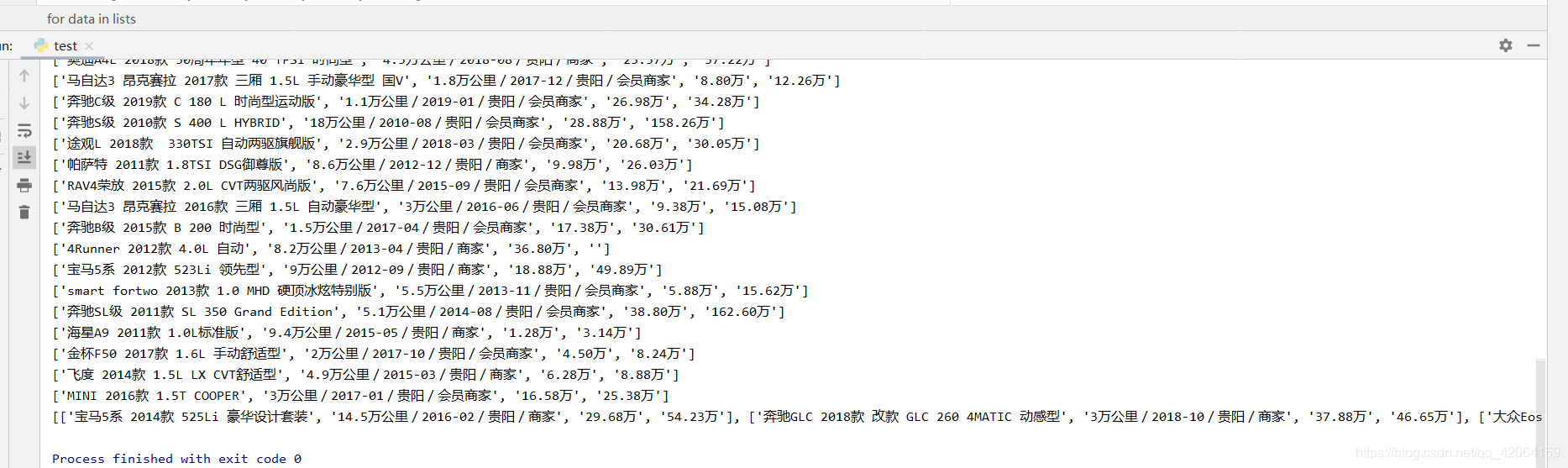
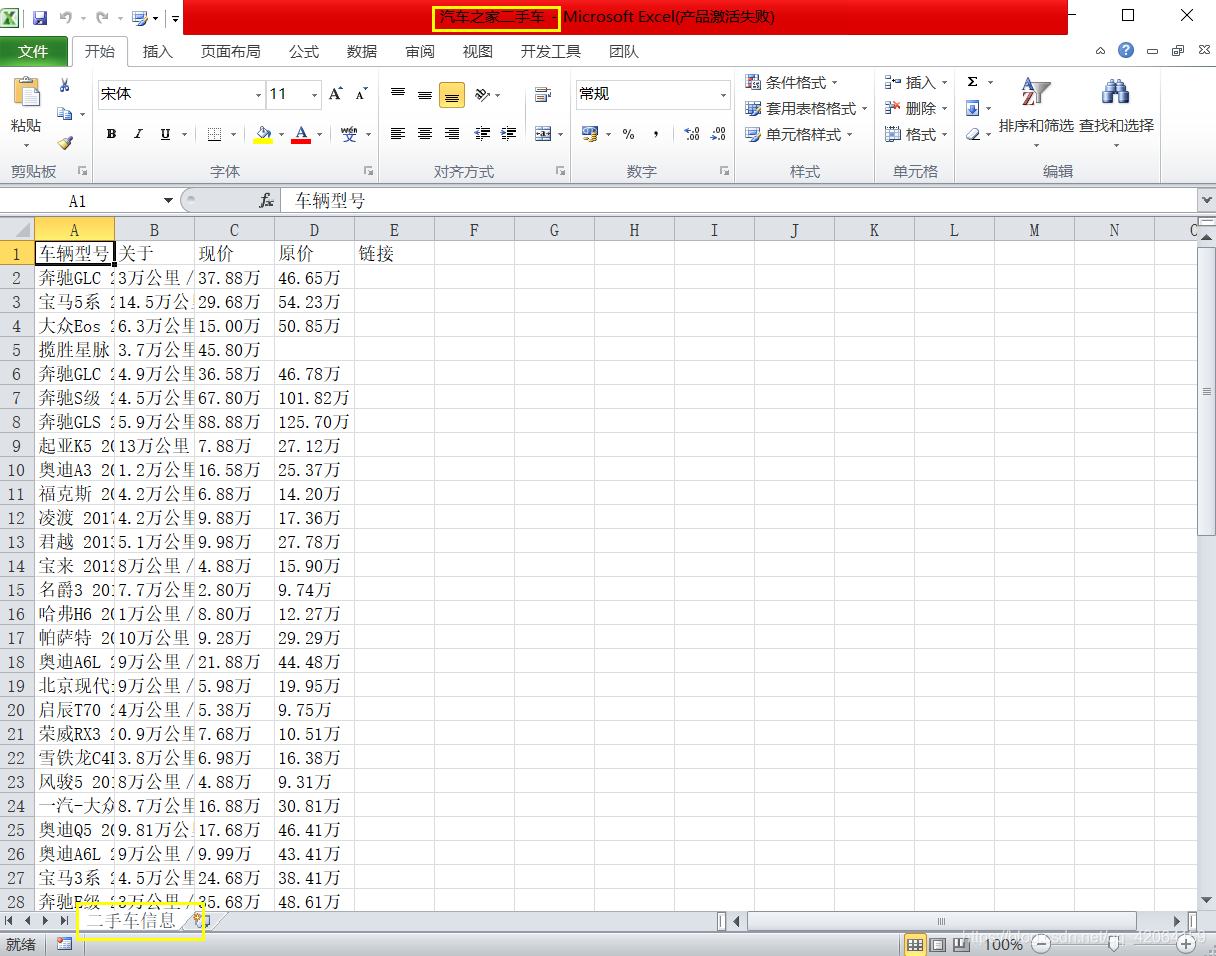
3. 保存到excel表格中
代码:
from openpyxl import Workbook
import xlsxwriter
wb = xlsxwriter.Workbook('汽车之家二手车.xlsx', {'constant_memory': True})
ws = wb.add_worksheet('二手车信息')
head = ['车辆型号', '关于', '现价', '原价', '链接']
ws.write_row(0, 0, head)
m = 1
for val in result:
for j in range(len(val)):
ws.write_row(m, 0, val)
m = m + 1
wb.close()
运行结果:
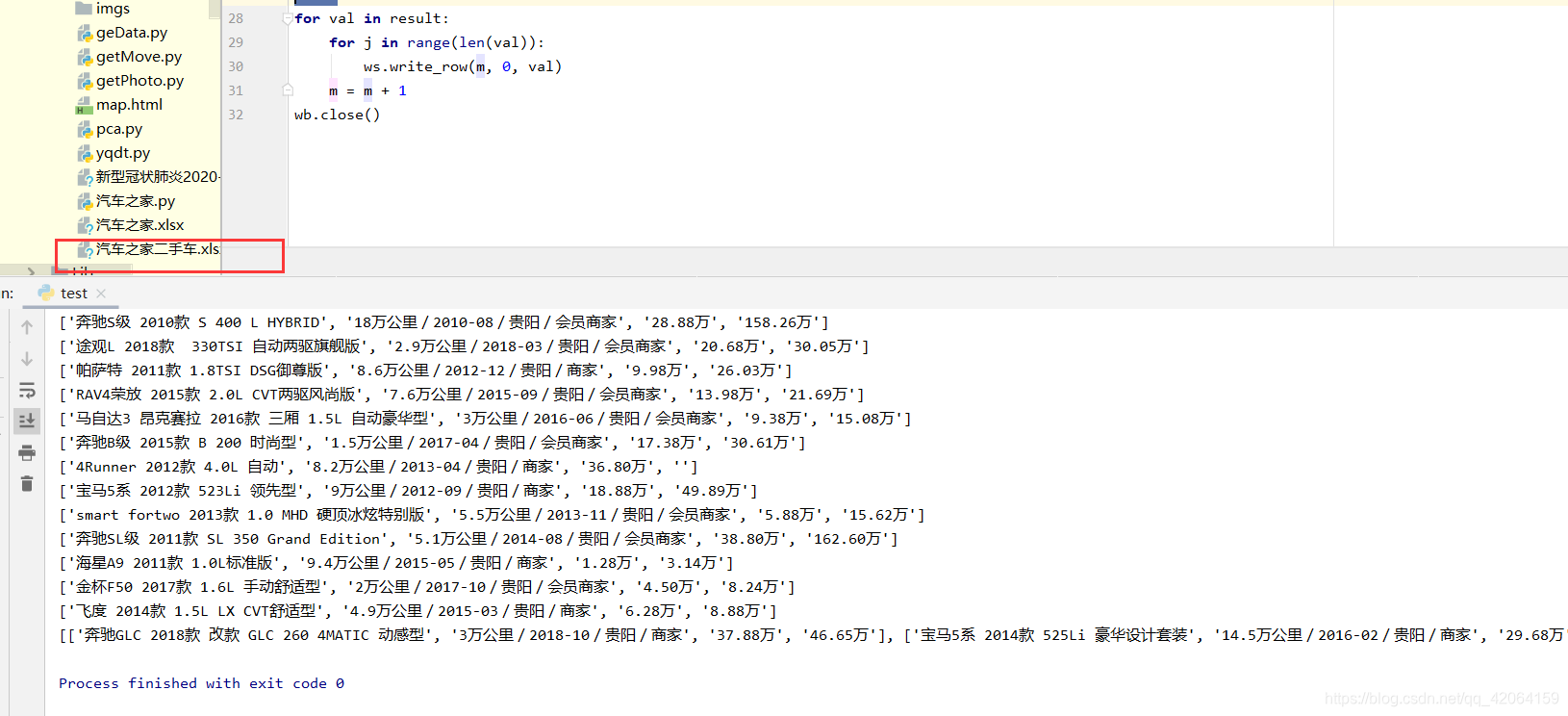
3.源码展示
源码及优化:
import requests
import xlwt
from bs4 import BeautifulSoup
from time import sleep
from openpyxl import Workbook
import xlsxwriter, time
import numpy as np
import pandas as pd
def getHtml(url, m):
start_time = time.time()
html = requests.get(url)
# print(html.text)
wb = xlsxwriter.Workbook('汽车之家.xlsx', {'constant_memory': True})
ws = wb.add_worksheet('二手车信息')
head = ['车辆型号', '关于', '现价', '原价', '链接']
ws.write_row(0, 0, head)
page = int(input('请输入爬取的页数:'))
p = 1
for i in range(page+1):
soup = BeautifulSoup(html.text, 'html.parser')
lists = soup.select('a.carinfo')
if i < page:
print('共%s页,正在爬取第%s页......' % (page, p))
result = []
arr = []
arr2 = []
urls = 'https://www.che168.com/'
k = 1
for data in lists:
if k <= len(lists):
link = urls + data.get('href')
print('共%s条,正在爬取第%s条......url:%s' % (len(lists), k, link))
arr2.append(link)
str = data
name = str.select_one('h4').text
car = str.select_one('p').text
price = str.select_one('span').text
value = str.select_one('s').text
string = name+','+car+','+price+','+value
arr = string.split(',')
arr.extend(arr2)
arr2 = []
result.append(arr)
k = k + 1
else:
break
print(result)
# 写入表格
for val in result:
for j in range(len(val)):
ws.write_row(m, 0, val)
m = m + 1
# print(m)
# result.clear()
next = soup.select_one('a.page-item-next').get('href')
next_page = urls + next
html = requests.get(next_page)
sleep(2)
p = p + 1
wb.close()
end_time = time.time()
print('本次爬取共耗时%s秒'%(end_time-start_time))
if __name__=="__main__":
m = 1
url = 'https://www.che168.com/nlist/guiyang/list/?pvareaid=100533'
getHtml(url, m)

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









