









On the Integration of Self-Attention and Convolution
代码
很棒的解读
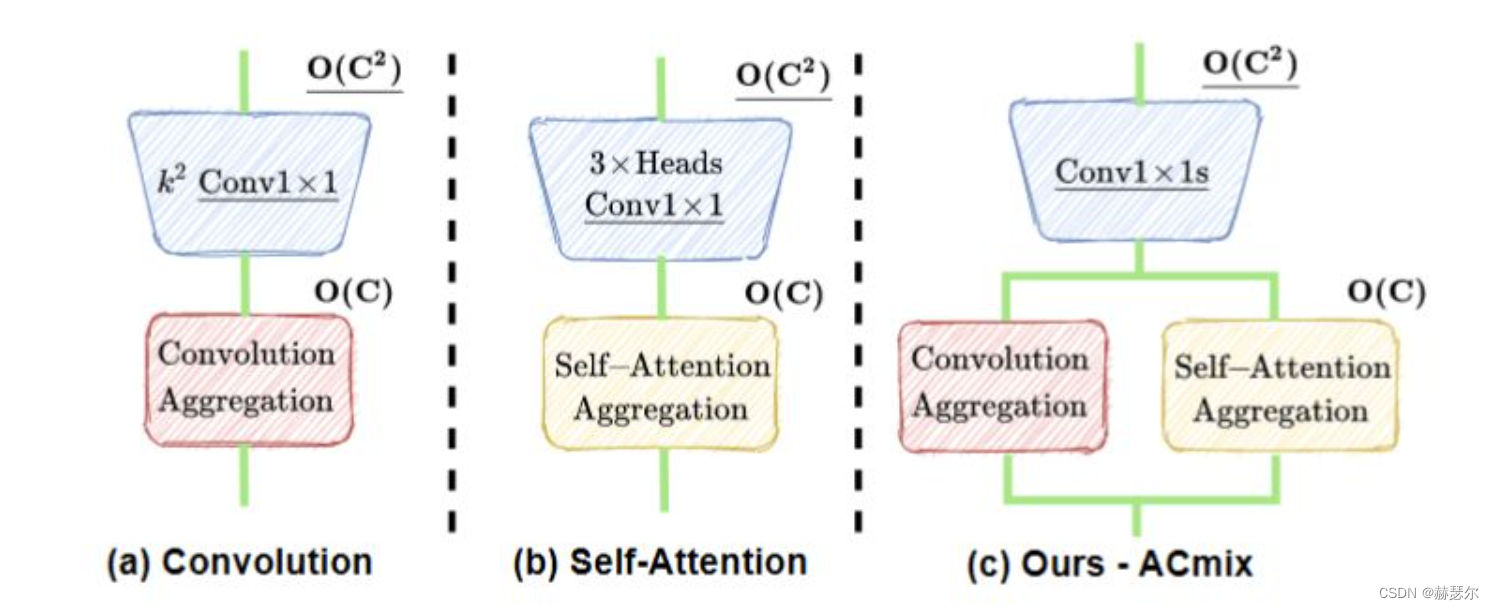
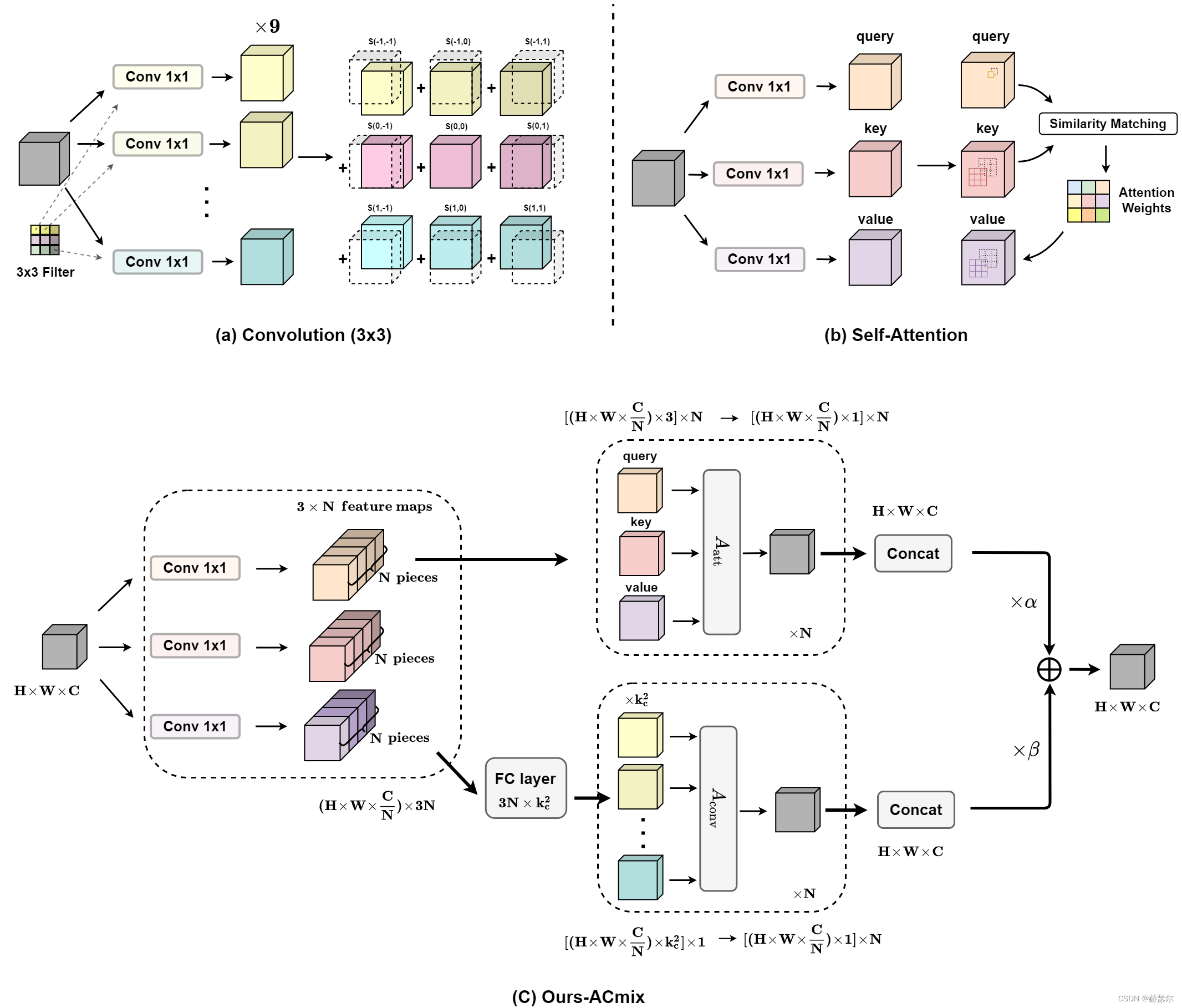
ATT分支: 通过3个1x1的卷积,生成3个feature map(主要是针对self attention的q、k和v),并将3个feature map分别在深度方向上分为N组(针对self attention的N 个 heads)。
卷积分支: 卷积,先通过通道层的全连接对通道扩张,后面处理和卷积第二步的处理相同,先对其偏移后,再去聚合成对应的维度。自注意力部分,按照上面的描述进行计算就可以。最后,将两个分支进行融合![[公式]](https://img-blog.csdnimg.cn/3665674a862c42c5b03ff87ca72306c7.png) ,系数
,系数 ![[公式]](https://img-blog.csdnimg.cn/ca090358c679410db36bb6618e7140a0.png) 和
和 ![[公式]](https://img-blog.csdnimg.cn/bfee4abd3dd94e13ac25c24fccfc4b98.png) 为可以学习的参数。
为可以学习的参数。
acmix block
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
# ### att
# ## positional encoding
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
## conv
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
基于resnet的acmix
import torch
import torch.nn as nn
from torchvision.models.utils import load_state_dict_from_url
from test_bottleneck import ACmix
def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
def conv1x1(in_planes, out_planes, stride=1):
"""1x1 convolution"""
return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)
class Bottleneck(nn.Module):
# Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2)
# while original implementation places the stride at the first 1x1 convolution(self.conv1)
# according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385.
# This variant is also known as ResNet V1.5 and improves accuracy according to
# https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch.
expansion = 4
def __init__(self, inplanes, planes, k_att, head, k_conv, stride=1, downsample=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = ACmix(width, width, k_att, head, k_conv, stride=stride, dilation=dilation)
self.bn2 = norm_layer(width)
self.conv3 = conv1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, k_att=7, head=4, k_conv=3, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
# each element in the tuple indicates if we should replace
# the 2x2 stride with a dilated convolution instead
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0], k_att, head, k_conv)
self.layer2 = self._make_layer(block, 128, layers[1], k_att, head, k_conv, stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layers[2], k_att, head, k_conv, stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layers[3], k_att, head, k_conv, stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# Zero-initialize the last BN in each residual branch,
# so that the residual branch starts with zeros, and each residual block behaves like an identity.
# This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
def _make_layer(self, block, planes, blocks, rate, k, head, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
conv1x1(self.inplanes, planes * block.expansion, stride),
norm_layer(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, rate, k, head, stride, downsample, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expansion
for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, rate, k, head, groups=self.groups,
base_width=self.base_width, dilation=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
# See note [TorchScript super()]
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
def _resnet(block, layers, **kwargs):
model = ResNet(block, layers, **kwargs)
return model
def ACmix_ResNet(layers=[3,4,6,3], **kwargs):
return _resnet(Bottleneck, layers, **kwargs)
if __name__ == '__main__':
model = ACmix_ResNet().cuda()
input = torch.randn([2,3,224,224]).cuda()
total_params = sum(p.numel() for p in model.parameters())
print(f'{total_params:,} total parameters.')
total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'{total_trainable_params:,} training parameters.')
print(model(input).shape)
# print(summary(model, torch.zeros((1, 3, 224, 224)).cuda()))














 4030
4030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









