









1 写在前面的话
该博客作为一个小Demo,记录深度学习算法UNet部署到Jetson TX2 NX的全部流程,可将此作为参考,继续部署自己的深度学习算法模型。部署总流程为:
- 1、在服务器端训练模型,一般为pth文件
- 2、在服务器端将pth文件转为onnx文件
- 3、在Jetson TX2 NX端将onnx文件转为trt文件
- 4、在Jetson TX2 NX端推理模型,输出分割结果
2 训练UNet网络
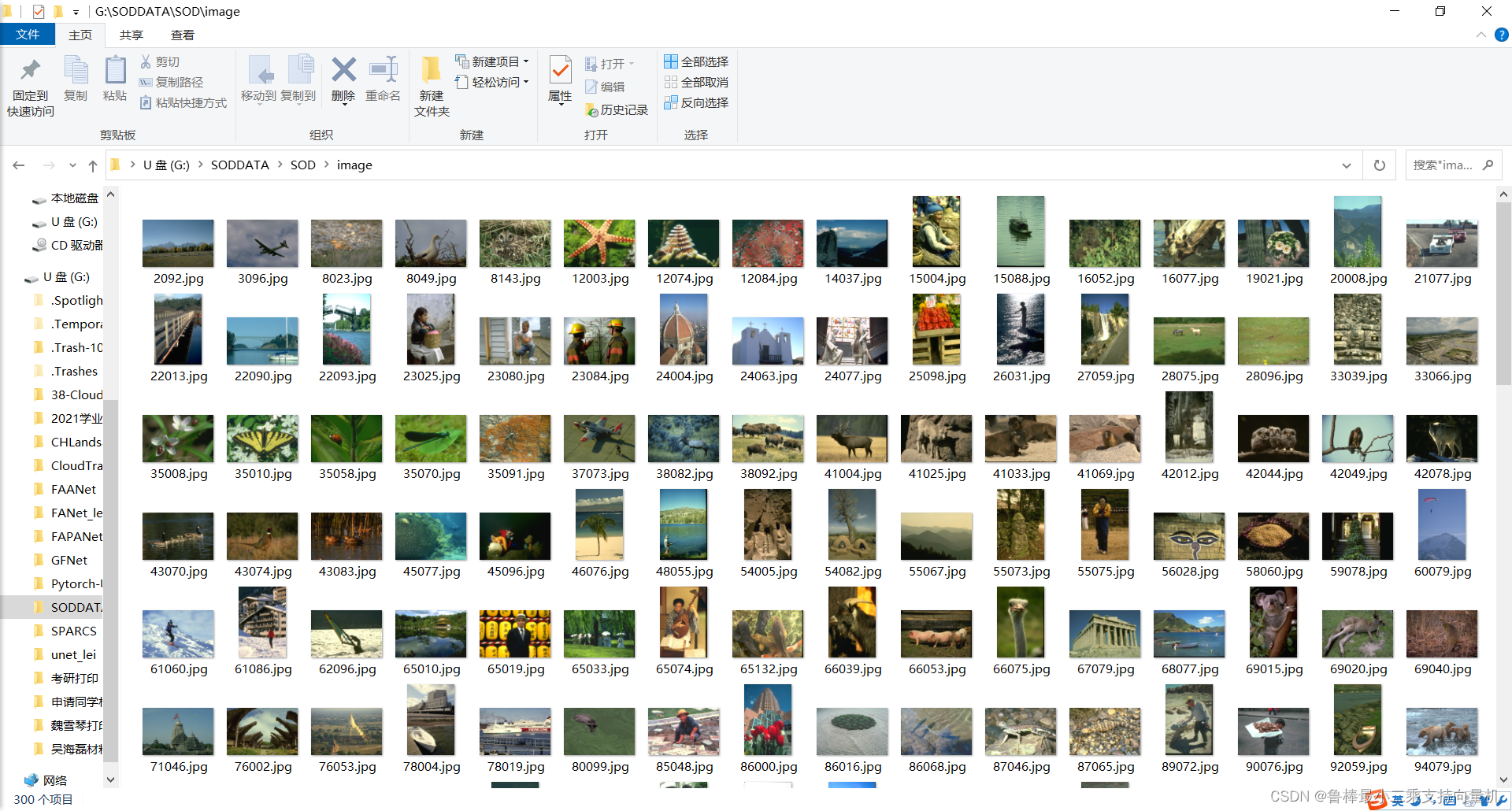
训练和测试数据均为显著性目标检测数据集SOD,image图像如图所示:
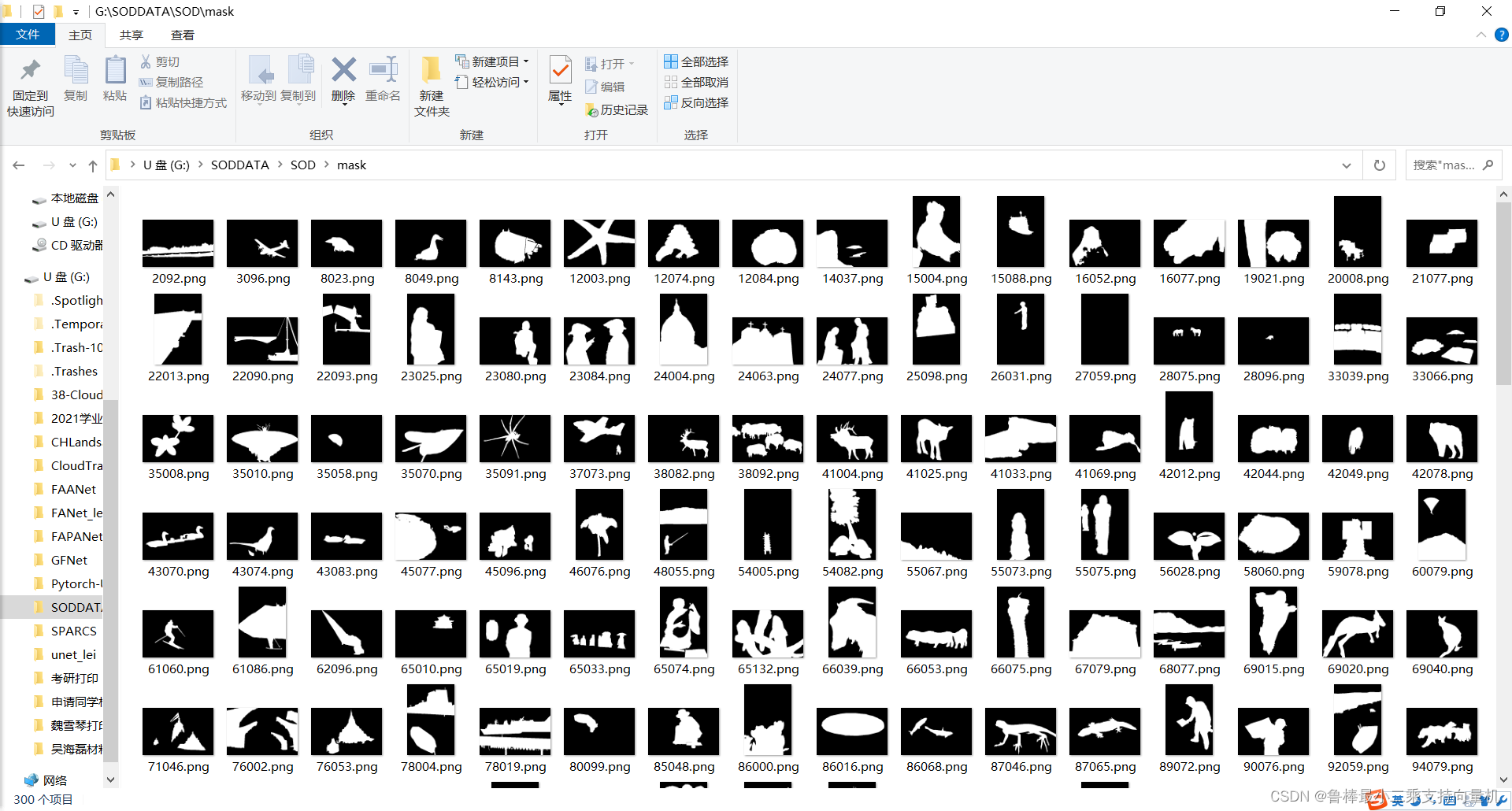
mask图像如图所示:
该项目的代码基于pytorch-UNet进行修改,源代码链接: https://github.com/milesial/Pytorch-UNet 直接下载即可

由于源代码写的比较完美,对于完成这个小Demo稍有复杂,因此进行代码的改写
unet_parts.py代码如下:
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
# diffY = x2.size()[2] - x1.size()[2]
# diffX = x2.size()[3] - x1.size()[3]
# x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
# diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
注意红色框内代码,如图所示,最好是注释掉或者改写,具体原因在onnx文件转为trt文件步骤时会解释

unet_model.py代码如下:
# -*- coding: utf-8 -*-
from unet_parts import *
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = (DoubleConv(n_channels, 64))
self.down1 = (Down(64, 128))
self.down2 = (Down(128, 256))
self.down3 = (Down(256, 512))
factor = 2 if bilinear else 1
self.down4 = (Down(512, 1024 // factor))
self.up1 = (Up(1024, 512 // factor, bilinear))
self.up2 = (Up(512, 256 // factor, bilinear))
self.up3 = (Up(256, 128 // factor, bilinear))
self.up4 = (Up(128, 64, bilinear))
self.outc = (OutConv(64, n_classes))
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
def print_network(model, name):
num_params = 0
for p in model.parameters():
num_params += p.numel()
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(name)
print(model)
print("The number of parameters: {}".format(num_params))
print("The number of total parameters: {}".format(total_num))
print("The number of trainable parameters: {}".format(trainable_num))
if __name__ == '__main__':
input = torch.randn((4, 3, 352, 352))
net = UNet(n_channels=3, n_classes=1, bilinear=False)
C1 = net(input)
print_network(net,'Model Structure')
print(C1.size())
如图所示:

dataset.py代码如下:
# -*- coding: utf-8 -*-
import cv2
import torch
import numpy as np
from torch.utils.data import Dataset, DataLoader
import glob
class LDataset(Dataset):
def __init__(self):
self.inp_path = './data/imgs'
self.out_path = './data/masks'
self.inp_files = sorted(glob.glob(self.inp_path + '/*'))
self.out_files = sorted(glob.glob(self.out_path + '/*'))
def __getitem__(self, idx):
inp_img = cv2.imread(self.inp_files[idx])
inp_img = cv2.cvtColor(inp_img, cv2.COLOR_BGR2RGB)
inp_img = inp_img.astype('float32')
mask_img = cv2.imread(self.out_files[idx], 0)
mask_img = mask_img.astype('float32')
mask_img /= (np.max(mask_img)+1e-15)
# Pad images to target size
inp_img = cv2.resize(inp_img,(480,320))
mask_img = cv2.resize(mask_img,(480,320))
inp_img /= 255.0
inp_img = np.transpose(inp_img, axes=(2, 0, 1))
inp_img = torch.from_numpy(inp_img).float()
mask_img = np.expand_dims(mask_img, axis=0)
return inp_img, torch.from_numpy(mask_img).float()
def __len__(self):
return len(self.inp_files)
注意设置图像和标签的尺寸,后面要统一,如图所示:

train.py代码如下:
# -*- coding: utf-8 -*-
import os
import argparse
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from dataset import LDataset
from unet_model import UNet
def parse_arguments():
parser = argparse.ArgumentParser(description='Parameters to train your model.')
parser.add_argument('--epochs', default=60, help='Number of epochs to train the model for', type=int)
parser.add_argument('--bs', default=2, help='Batch size', type=int)
parser.add_argument('--lr', default=5e-5, help='Learning Rate', type=float)
parser.add_argument('--wd', default=0.0005, help='L2 Weight decay', type=float)
parser.add_argument('--n_worker', default=2, help='Number of workers to use for loading data', type=int)
parser.add_argument('--test_interval', default=2, help='Number of epochs after which to test the weights', type=int)
parser.add_argument('--save_interval', default=10, help='Number of epochs after which to save the weights. If None, does not save', type=int)
parser.add_argument('--save_opt', default=False, help='Whether to save optimizer along with model weights or not', type=bool)
parser.add_argument('--log_interval', default=250, help='Logging interval (in #batches)', type=int)
parser.add_argument('--res_mod', default=None, type=str)
parser.add_argument('--res_opt', default=None, help='Path to the optimizer to resume from', type=str)
parser.add_argument('--use_gpu', default=True, help='Flag to use GPU or not', type=bool)
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
parser.add_argument('--base_save_path', default='./models', help='Base path for the models to be saved', type=str)
return parser.parse_args()
class Engine:
def __init__(self, args):
self.epochs = args.epochs
self.bs = args.bs
self.lr = args.lr
self.wd = args.wd
self.n_worker = args.n_worker
self.test_interval = args.test_interval
self.save_interval = args.save_interval
self.save_opt = args.save_opt
self.log_interval = args.log_interval
self.res_mod_path = args.res_mod
self.res_opt_path = args.res_opt
self.use_gpu = args.use_gpu
self.lr_decay_epoch = [8, 16, 24]
self.model_path = args.base_save_path + '/checkpoint_epoch{}.pth'.format(str(self.epochs))
print('Models would be saved at : {}\n'.format(self.model_path))
if not os.path.exists(os.path.join(self.model_path, 'weights')):
os.makedirs(os.path.join(self.model_path, 'weights'))
if not os.path.exists(os.path.join(self.model_path, 'optimizers')):
os.makedirs(os.path.join(self.model_path, 'optimizers'))
if torch.cuda.is_available():
self.device = torch.device(device='cuda')
else:
self.device = torch.device(device='cpu')
self.model = UNet(n_channels=3, n_classes=1, bilinear=False)
self.model.to(self.device)
self.criterion = nn.BCEWithLogitsLoss()
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr, betas=(0.9, 0.999), eps=1e-08, weight_decay=self.wd)
self.print_network(self.model, 'Net Structure')
# Load model and optimizer if resumed
if self.res_mod_path is not None:
chkpt = torch.load(self.res_mod_path, map_location=self.device)
self.model.load_state_dict(chkpt['model'])
print("Resuming training with checkpoint : {}\n".format(self.res_mod_path))
if self.res_opt_path is not None:
chkpt = torch.load(self.res_opt_path, map_location=self.device)
self.optimizer.load_state_dict(chkpt['optimizer'])
print("Resuming training with optimizer : {}\n".format(self.res_opt_path))
data = LDataset()
self.train_data, self.test_data = torch.utils.data.random_split(data, (240, 60))
self.train_dataloader = DataLoader(self.train_data, batch_size=self.bs, shuffle=True, num_workers=self.n_worker)
self.test_dataloader = DataLoader(self.test_data, batch_size=self.bs, shuffle=False, num_workers=self.n_worker)
def print_network(self, model, name):
num_params = 0
for p in model.parameters():
num_params += p.numel()
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(name)
print(model)
print("The number of parameters: {}".format(num_params))
print("The number of total parameters: {}".format(total_num))
print("The number of trainable parameters: {}".format(trainable_num))
def train(self):
best_test_mae = float('inf')
# batch_num = len(self.train_dataloader) // self.bs# batch的数量
for epoch in range(self.epochs):
self.model.train()
for batch_idx, (inp_imgs, gt_masks) in enumerate(self.train_dataloader):
inp_imgs = inp_imgs.to(self.device)
gt_masks = gt_masks.to(self.device)
self.optimizer.zero_grad()
pred_masks = self.model(inp_imgs)
loss = self.criterion(pred_masks, gt_masks)
loss.backward()
self.optimizer.step()
if batch_idx % self.log_interval == 0:
print('TRAIN :: Epoch : {}\tBatch : {}/{} ({:.2f}%)\t\tTot Loss : {:.4f}'
.format(epoch + 1,
batch_idx + 1, len(self.train_dataloader),
(batch_idx + 1) * 100 / len(self.train_dataloader),
loss.item()))
# 对应epoch对学习率进行lr dacay
if epoch in self.lr_decay_epoch:
self.lr = self.lr * 0.1
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr, betas=(0.9, 0.999), eps=1e-08, weight_decay=self.wd)
# Validation
if epoch % self.test_interval == 0 or epoch % self.save_interval == 0:
te_avg_loss, te_acc, te_pre, te_rec, te_mae = self.test()
mod_chkpt = {'epoch': epoch,
'test_mae' : float(te_mae),
'model' : self.model.state_dict(),
'test_loss': float(te_avg_loss),
'test_acc': float(te_acc),
'test_pre': float(te_pre),
'test_rec': float(te_rec)}
if self.save_opt:
opt_chkpt = {'epoch': epoch,
'test_mae' : float(te_mae),
'optimizer': self.optimizer.state_dict(),
'test_loss': float(te_avg_loss),
'test_acc': float(te_acc),
'test_pre': float(te_pre),
'test_rec': float(te_rec)}
# Save the best model
if te_mae <= best_test_mae:
best_test_mae = te_mae
torch.save(mod_chkpt, self.model_path + '/weights/best-model_epoch-{:03}_mae-{:.4f}_loss-{:.4f}.pth'.
format(epoch, best_test_mae, te_avg_loss))
if self.save_opt:
torch.save(opt_chkpt, self.model_path + '/optimizers/best-opt_epoch-{:03}_mae-{:.4f}_loss-{:.4f}.pth'.
format(epoch, best_test_mae, te_avg_loss))
print('Best Model Saved !!!\n')
continue
# Save model at regular intervals
if self.save_interval is not None and epoch % self.save_interval == 0:
torch.save(mod_chkpt, self.model_path + '/weights/model_epoch-{:03}_mae-{:.4f}_loss-{:.4f}.pth'.
format(epoch, te_mae, te_avg_loss))
if self.save_opt:
torch.save(opt_chkpt, self.model_path + '/optimizers/opt_epoch-{:03}_mae-{:.4f}_loss-{:.4f}.pth'.
format(epoch, best_test_mae, te_avg_loss))
print('Model Saved !!!\n')
continue
print('\n')
def test(self):
self.model.eval()
tot_loss = 0
tp_fp = 0 # TruePositive + TrueNegative, for accuracy
tp = 0 # TruePositive
pred_true = 0 # Number of '1' predictions, for precision
gt_true = 0 # Number of '1's in gt mask, for recall
mae_list = [] # List to save mean absolute error of each image
fscore, cnt, number = 0, 0, 256
mean_pr, mean_re, threshod = 0, 0, np.linspace(0, 1, number, endpoint=False)
with torch.no_grad():
for batch_idx, (inp_imgs, gt_masks) in enumerate(self.test_dataloader, start=1):
inp_imgs = inp_imgs.to(self.device)
gt_masks = gt_masks.to(self.device)
pred_masks = self.model(inp_imgs)
loss = self.criterion(pred_masks, gt_masks)
tot_loss += loss.item()
tp_fp += (pred_masks.round() == gt_masks).float().sum()
tp += torch.mul(pred_masks.round(), gt_masks).sum()
pred_true += pred_masks.round().sum()
gt_true += gt_masks.sum()
ae = torch.mean(torch.abs(pred_masks - gt_masks), dim=(1, 2, 3)).cpu().numpy()
mae_list.extend(ae)
cnt += 1
## F-Score
precision = torch.zeros(number)
recall = torch.zeros(number)
for i in range(number):
temp = (pred_masks >= threshod[i]).float()
precision[i] = (temp*gt_masks).sum()/(temp.sum()+1e-12)
recall[i] = (temp*gt_masks).sum()/(gt_masks.sum()+1e-12)
mean_pr += precision
mean_re += recall
fscore = mean_pr*mean_re*(1+0.3)/(0.3*mean_pr+mean_re+1e-12)
avg_loss = tot_loss / batch_idx
accuracy = tp_fp / (len(self.test_data) * 480 * 320)
precision = tp / pred_true
recall = tp / gt_true
mae = np.mean(mae_list)
maxf = fscore.max()/cnt
print('TEST :: MAE : {:.4f}\tMAXF : {:.4f}\tACC : {:.4f}\tPRE : {:.4f}\tREC : {:.4f}\tAVG-LOSS : {:.4f}\n'.format(mae,
maxf,
accuracy,
precision,
recall,
avg_loss))
return avg_loss, accuracy, precision, recall, mae
if __name__ == '__main__':
rt_args = parse_arguments()
# Driver class
trainer = Engine(rt_args)
trainer.train()
# trainer.test()
由于tensorrt里面还没有实现bilinear双线性插值上采样操作,所以选择使用deconv作为上采样的unet网络结构,因此如图所示,注意UNet模型这,不能使用双线性插值的方式进行上采样,故bilinear=False

模型训练结束后,开始将pth文件转为onnx文件,代码参考大佬 ubuntu18一文学会Pytorch端到端网络部署Tensorrt模型推理
from unet_model import UNet #
import torch
import onnx
# gloabl variable
model_path = "./models/best-model_epoch-000_mae-0.8259_loss-0.5747.pth"
if __name__ == "__main__":
# input shape
dummy_input = torch.randn(1, 3, 320, 480, device="cuda")
# [1] create network
model = UNet(n_channels=3, n_classes=1, bilinear=False)
model = model.cuda()
print("create U-Net model finised ...")
# [2] load weight
device = torch.device(device='cuda')
chkpt = torch.load(model_path, map_location=device)
model.load_state_dict(chkpt['model'])
print("load weight to model finised ...")
# convert torch format to onnx
input_names = ["input"]
output_names = ["output"]
torch.onnx.export(model,
dummy_input,
"unet_deconv.onnx",
verbose=True,
input_names=input_names,
output_names=output_names)
print("convert torch format model to onnx ...")
# [4] confirm the onnx file
net = onnx.load("unet_deconv.onnx")
# check that the IR is well formed
onnx.checker.check_model(net)
# print a human readable representation of the graph
onnx.helper.printable_graph(net.graph)
注意输入shape以及UNet设置与上述设置相同,直接运行即可,如图所示

至此,在服务器端的操作已经完成,然后将所有程序以及训练的模型和onnx文件拷贝到Jetson TX2 NX
3 Jetson TX2 NX实现图像分割
首先安装一些包,输入命令
pip3 install pycuda==2019.1.2 --user
如图所示,该版本可以安装成功

pycuda包安装成功,如图所示,继续安装onnx包,输入命令
pip3 install onnx
最终无法安装成功:

报错如图所示:

解决上述错误,首先安装protobuf,输入命令
pip3 install protobuf
然后就安装protobuf-compiler和libprotoc-dev,输入命令
sudo apt-get install protobuf-compiler libprotoc-dev
如图所示:

然后输入onnx安装命令,注意版本为1.9.0
pip3 install onnx==1.9.0
成功安装,如图所示:

可以尝试在Jetson TX2 NX端进行pth文件转onnx文件,可能会被killed,无法成功,这里可以尝试增加Swap分区,大家自行实验

将在服务器端转换完成的onnx文件拷贝到Jetson TX2 NX,如图所示

开始进行onnx文件转trt文件,输入命令
onnx2trt unet_deconv.onnx -o unet_deconv.trt
这里注意onnx文件位置,以及trt文件需要保存的位置,但是转换出错了,如图所示

参考大佬文章: pytorch模型转tensorrt,pad报错,opset11 我使用了比较简单的方法,即注释掉该部分代码,在以后部署其他深度模型时,可能需要考虑在pytorch中不使用pad操作

于是重复所有步骤,重新在服务器端训练模型,然后将pth文件转为onnx文件,并拷贝到Jetson TX2 NX,如图所示:

然后继续进行onnx文件转trt文件,输入命令
onnx2trt unet_deconv.onnx -o unet_deconv.trt
如图所示

出现问题,进程被killed

我直接关机重启Jetson TX2 NX,然后再次输入命令,成功,大家可以尝试增加Swap分区

接下来开始测试,inference.py代码如下:
import os
import sys
import time
# from PIL import Image
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2
# TensorRT logger singleton
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
def load_engine(trt_path):
# 反序列化引擎
with open(trt_path, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
class TRTInference(object):
"""Manages TensorRT objects for model inference."""
def __init__(self, trt_engine_path, onnx_model_path, trt_engine_datatype=trt.DataType.FLOAT, batch_size=1):
"""Initializes TensorRT objects needed for model inference.
Args:
trt_engine_path (str): path where TensorRT engine should be stored
uff_model_path (str): path of .uff model
trt_engine_datatype (trt.DataType):
requested precision of TensorRT engine used for inference
batch_size (int): batch size for which engine
should be optimized for
"""
# Initialize runtime needed for loading TensorRT engine from file
# TRT engine placeholder
self.trt_engine = None
# Display requested engine settings to stdout
print("TensorRT inference engine settings:")
print(" * Inference precision - {}".format(trt_engine_datatype))
print(" * Max batch size - {}\n".format(batch_size))
# If we get here, the file with engine exists, so we can load it
if not self.trt_engine:
print("Loading cached TensorRT engine from {}".format(
trt_engine_path))
self.trt_engine = load_engine(
trt_engine_path)
# This allocates memory for network inputs/outputs on both CPU and GPU
self.inputs, self.outputs, self.bindings, self.stream = allocate_buffers(self.trt_engine)
# Execution context is needed for inference
self.context = self.trt_engine.create_execution_context()
def infer(self, full_img, output_shapes, new_width, new_height):
"""Infers model on given image.
Args:
image_path (str): image to run object detection model on
"""
assert new_width > 0 and new_height > 0, "Scale is too small"
# resize and transform to array
scale_img = cv2.resize(full_img, (new_width, new_height))
print("scale image shape:{}".format(scale_img.shape))
# scale_img = np.array(scale_img)
# HWC to CHW
scale_img = scale_img.transpose((2, 0, 1))
# 归一化
if scale_img.max() > 1:
scale_img = scale_img / 255
# 扩增通道数
# scale_img = np.expand_dims(scale_img, axis=0)
# 将数据成块
scale_img = np.array(scale_img, dtype=np.float32, order='C')
# Copy it into appropriate place into memory
# (self.inputs was returned earlier by allocate_buffers())
np.copyto(self.inputs[0].host, scale_img.ravel())
# Output shapes expected by the post-processor
# output_shapes = [(1, 11616, 4), (11616, 21)]
# When infering on single image, we measure inference
# time to output it to the user
inference_start_time = time.time()
# Fetch output from the model
trt_outputs = do_inference(
self.context, bindings=self.bindings, inputs=self.inputs,
outputs=self.outputs, stream=self.stream)
print("network output shape:{}".format(trt_outputs[0].shape))
# Output inference time
print("TensorRT inference time: {} ms".format(
int(round((time.time() - inference_start_time) * 1000))))
# Before doing post-processing, we need to reshape the outputs as the common.do_inference will
# give us flat arrays.
outputs = [output.reshape(shape) for output, shape in zip(trt_outputs, output_shapes)]
# And return results
return outputs
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
predict.py代码如下:
import tensorrt as trt
import numpy as np
import cv2
import inference as inference_utils # TRT/TF inference wrappers
if __name__ == "__main__":
# 1. 网络构建
# Precision command line argument -> TRT Engine datatype
TRT_PRECISION_TO_DATATYPE = {
16: trt.DataType.HALF,
32: trt.DataType.FLOAT
}
# datatype: float 32
trt_engine_datatype = TRT_PRECISION_TO_DATATYPE[16]
# batch size = 1
max_batch_size = 1
engine_file_path = "unet_deconv_sim.trt"
onnx_file_path = "unet_deconv_sim.onnx"
new_width, new_height = 480, 320
output_shapes = [(1, new_height, new_width)]
trt_inference_wrapper = inference_utils.TRTInference(
engine_file_path, onnx_file_path,
trt_engine_datatype, max_batch_size,
)
# 2. 图像预处理
image_path = "example.jpg"
img = cv2.imread(image_path)
# inference
trt_outputs = trt_inference_wrapper.infer(img, output_shapes, new_width, new_height)[0]
# 输出后处理
out_threshold = 0.5
print("the size of tensorrt output : {}".format(trt_outputs.shape))
output = trt_outputs.transpose((1, 2, 0))
# 0/1像素值
output[output > out_threshold] = 255
output[output <= out_threshold] = 0
output = output.astype(np.uint8)
result = cv2.resize(output, (img.shape[1], img.shape[0]))
cv2.imwrite("best_output_deconv.jpg", result)
这里需要注意trt文件、onnx文件以及测试图像的位置,如图所示:

最终显著性目标分割结果如图所示,因为该Demo只是用来测试将UNet部署在Jetson TX2 NX。为了节省时间,训练模型只使用了一个epoch,故精度很差

希望本文对大家有帮助,上文若有不妥之处,欢迎指正
分享决定高度,学习拉开差距


















 505
505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











