






前言
该项目属于是我完成网站动漫书架板块的一个组件。
因为我打算每一个动漫都展示出一些关于他的图片信息,比如封面,他的相关图片。所以当我从网络上把图片下载下来后我需要有一个代码能够快速把他们上传到我的阿里云oss桶里,上传成功后要能够返回他的图床url。
其中需要解决的两个现实问题:
- 图片有jpg,png等多种格式,要有泛化能力
- 图片从网上下载,名字一般都是乱码,我们需要修改成正确的动漫名
其实我的这个代码里面还是有一些现实问题的,比如txt编码,部分动漫名称不合法导致抛出异常,异常抛出与日志,这些我懒得解决了,等我真正遇到的时候再解决,如果解决了我再来更新这篇博客。
代码分布解析
导入库,导入基础的os库和阿里oss提供的oss2库
import os
import oss2
初始化自己阿里云的access信息
# 填写自己的 access信息
access_key_id = '你的key_id'
access_key_secret = '你的key_secret'
填写自己oss的目标桶和目标路径
比如我就把我的图片都上传到桶的anime文件夹内了
# 填写自己的 Bucket 名称和上传地址
upload_path = 'anime/'
bucket_name = 'blog-zaughter-01'
创建oss链接
根据access创建了auth信息
注意oss2.Bucket中第二个参数是endpoint,根据桶地区的不同是不一样的,详细如下:
# 创建 OSS 链接
auth = oss2.Auth(access_key_id, access_key_secret)
bucket = oss2.Bucket(auth, 'https://oss-cn-hangzhou.aliyuncs.com', bucket_name)
通过输入的txt文件处理文件夹内的图片
# 通过txt文件处理文件夹内图片
local_url = []
# 我们传入的txt文件位置
f_path = r'C:/Users/zaughter/Desktop/test.txt'
# 我们图片所在的文件夹,这里我是直接把图片扔桌面上了
pic_path = 'C:/Users/zaughter/Desktop/'
with open(f_path) as f:
line = f.readline()
while line:
# 我们的txt文件是通过excel生成的,所以文件的每一行都有如下格式
# 动漫名称(火影忍者) + 制表符\t + 图片文件名称(1.jpg)
line_str = line.split('\t')
# 首先line_str[1]内容为:1.jpg\n
# 通过第一个split得到前面的1.jpg
# 接着把1(文件名)和jpg(后缀名)拆分保存到数组中
suffix_tmp = line_str[1].split('\n')[0].split('.')
# 得到数组最后一个内容(后缀名)
# 不直接使用[1]是为了防止文件名里有.导致数组元素不止两个,但其实后缀名一定是最后一个
suffix = suffix_tmp[len(suffix_tmp) - 1]
# 得到图片的完整路径,同时这个图片的名称为动漫名
# 图片所在文件夹 + 动漫名称(火影忍者) + . + 后缀名(jpg)
dst = os.path.join(pic_path + pic_path, line_str[0] + '.' + suffix)
# 把本地文件重命名
# 从 1.jpg 变为 火影忍者.jpg
os.rename(line_str[1].split('\n')[0], dst)
# 添加到数组中保存
local_url.append(dst)
# 读取文件下一行以达到循环的效果
line = f.readline()
定义方法上传图片到oss端
# 上传文件到 OSS
# 这里的file_path就是上面我们保存到local_url容器里面的dst
def oss_upload_file(file_path):
# 通过basename方法得到路径最后的文件名,也就是图片名(火影忍者.jpg)
file_name = os.path.basename(file_path)
# 构造oss中的路径,我这里就是:anime/火影忍者.jpg
oss_path = upload_path + file_name
# 上传文件,以二进制方式(rb)打开图片上传
with open(file_path, 'rb') as file_obj:
result = bucket.put_object(oss_path, file_obj)
测试
# 测试
o_list = open("oss_list.txt", mode="w")
# 从local_url容器里依次提取重命名图片
for file_path in local_url:
oss_upload_file(file_path)
# 同理,这样可以拿到动漫的名字
tmp = file_path.split('/')
name = tmp[len(tmp) - 1].split('.')[0]
# 打印结果
print("=========================")
# 依次输出:
# 番剧名、重命名后的本地图片地址、oss中的url(通过人为拼接)
print("番剧名:" + name + "\n文件地址:" + file_path
+ "\nurl:https://blog-zaughter-01.oss-cn-hangzhou.aliyuncs.com/anime/"
+ name + "." + tmp[len(tmp) - 1].split('.')[1])
# 在生成个输出的txt,返回番名和oss的url(博客写完后才想起来的点,赶快把代码补上了)
o_list.write(name + "\t" + " https://blog-zaughter-01.oss-cn-hangzhou.aliyuncs.com/anime/"
+ name + "." + tmp[len(tmp) - 1].split('.')[1] + "\n")
print("=========================")
完整代码
import os
import oss2
# 填写自己的 access信息
access_key_id = 'key_id'
access_key_secret = 'key_secret'
# 填写自己的 Bucket 名称和上传地址
upload_path = 'anime/'
bucket_name = 'blog-zaughter-01'
# 创建 OSS 链接
auth = oss2.Auth(access_key_id, access_key_secret)
bucket = oss2.Bucket(auth, 'https://oss-cn-hangzhou.aliyuncs.com', bucket_name)
# 通过txt文件处理文件夹内图片
local_url = []
f_path = r'C:/Users/zaughter/Desktop/test.txt'
pic_path = 'C:/Users/zaughter/Desktop/'
with open(f_path) as f:
line = f.readline()
while line:
line_str = line.split('\t')
suffix_tmp = line_str[1].split('\n')[0].split('.')
suffix = suffix_tmp[len(suffix_tmp) - 1]
dst = os.path.join(pic_path + pic_path, line_str[0] + '.' + suffix)
os.rename(line_str[1].split('\n')[0], dst)
local_url.append(dst)
line = f.readline()
# 上传文件到 OSS
def oss_upload_file(file_path):
# 构造上传路径
file_name = os.path.basename(file_path)
oss_path = upload_path + file_name
# 上传文件
with open(file_path, 'rb') as file_obj:
result = bucket.put_object(oss_path, file_obj)
# 测试
o_list = open("oss_list.txt", mode="w")
for file_path in local_url:
oss_upload_file(file_path)
tmp = file_path.split('/')
name = tmp[len(tmp) - 1].split('.')[0]
print("=========================")
print("番剧名:" + name + "\n文件地址:" + file_path
+ "\nurl:https://blog-zaughter-01.oss-cn-hangzhou.aliyuncs.com/anime/"
+ name + "." + tmp[len(tmp) - 1].split('.')[1])
o_list.write(name + "\t" + " https://blog-zaughter-01.oss-cn-hangzhou.aliyuncs.com/anime/"
+ name + "." + tmp[len(tmp) - 1].split('.')[1] + "\n")
print("=========================")
使用教程
通过excel创建txt文档
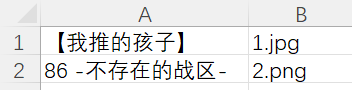
这里我就拿两个番来举例好了,同时两张图片的后缀名也不一样,我还是把图片扔到我的桌面

接着去创建一个excel表格写好内容,分别是动漫名称和图片名
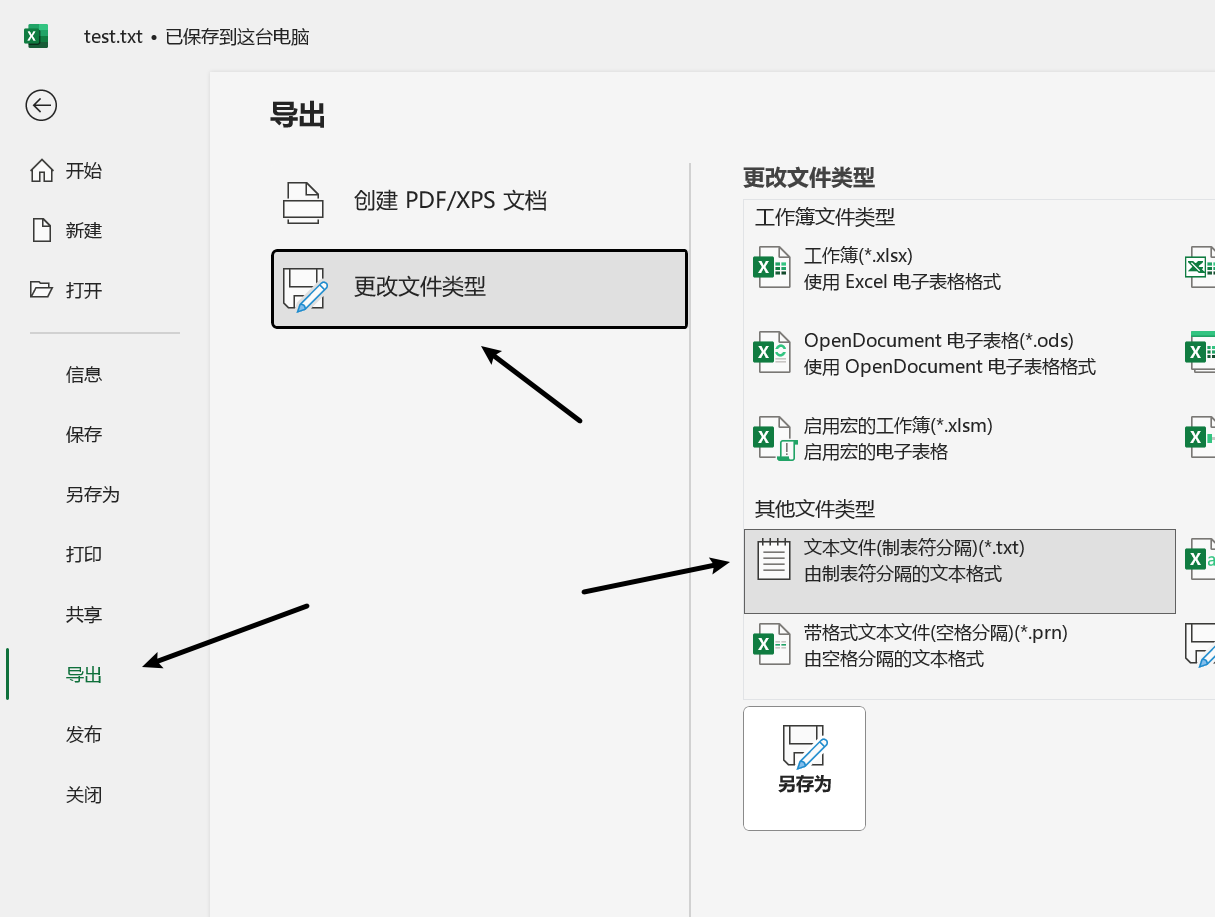
接着去到处为txt格式,注意这个txt与自己新建txt的编码是不一样的,自己写我的程序可能会报错
txt文件内容如下:

运行代码
注意运行前先看代码分布解析,把所有参数都写正确
结果
运行输出结果如下:

生成的txt如下,这个txt是可以反向生成为excel表格的,同时我们还可以用一些方法把他和另一个表以动漫名为索引拼接,把oss的url信息补充到大表里面,以后把大表转为数据库(具体转excel与拼接我下篇爬虫博客再说)

再看桌面,图片的名称已经修正了:

最后看oss文件列表,也成功了:
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









