






前言
这对于我属于一个比较大的工程了,所有知识都是新的要慢慢学,同时也是一个没有接触过的领域。但是经过了一周多的时间还是成功解决了,里面肯定有很多不完美的地方,但是我个人觉得对于我这个新手还是很成功的。
宏观需求一句话就是:手动给出番剧名称,自动得到番剧的相关信息并且制成excel,这个excel在后期可以导入到数据库,进而作为网站番剧书架分区的数据。
分布流程如下:
- 在bangumi中手动逐年翻看番剧,把所有自己看过的番剧添加到自己账号的在看中
- 通过油猴脚本将账号中添加的所有在看番剧爬取下来,得到番剧名称+封面url信息制作成excel
- 将此excel制作成txt作为python代码的读取文件
- 通过moegirl_url_get.py文件得到每个番剧在萌娘百科的对应url
- 通过douban_info_get.py文件得到每个番剧在豆瓣中的相关信息,包括:
- 豆瓣评分
- 导演、编剧、主演
- 番剧在豆瓣中对应的url
- 番剧在豆瓣中相关图片页面的url
- 豆瓣给出的豆瓣相关图片
- 通过excel的VLOOKUP函数进行多表合并,把上面得到的两个表的信息与初始表进行合并,进而得到有完整信息的excel表格
注意:爬虫使用时全程开着代理,防止网站检测到爬虫把IP封了,如果封了就换个代理就行,比较方便,别到时候把自己正常ip搭进去了
正文
这里我将根据实际操作的整个流程依次介绍用到的方法或者我写的代码
1.bangumi番剧手动添加
bangumi网站链接是一个很大的动漫社区,里面番剧的数据库比较完全,所以可以把他作为我们整个流程的起点,保证我们看过的番剧都能在这里面找到(同时也会引发一个问题:bangumi分的比较细,导致豆瓣和萌娘有些细分番剧并没有对应词条,爬虫得到的信息是错的)
进去建个号然后慢慢把自己活到现在看过的番都添加到bangumi的在看里面
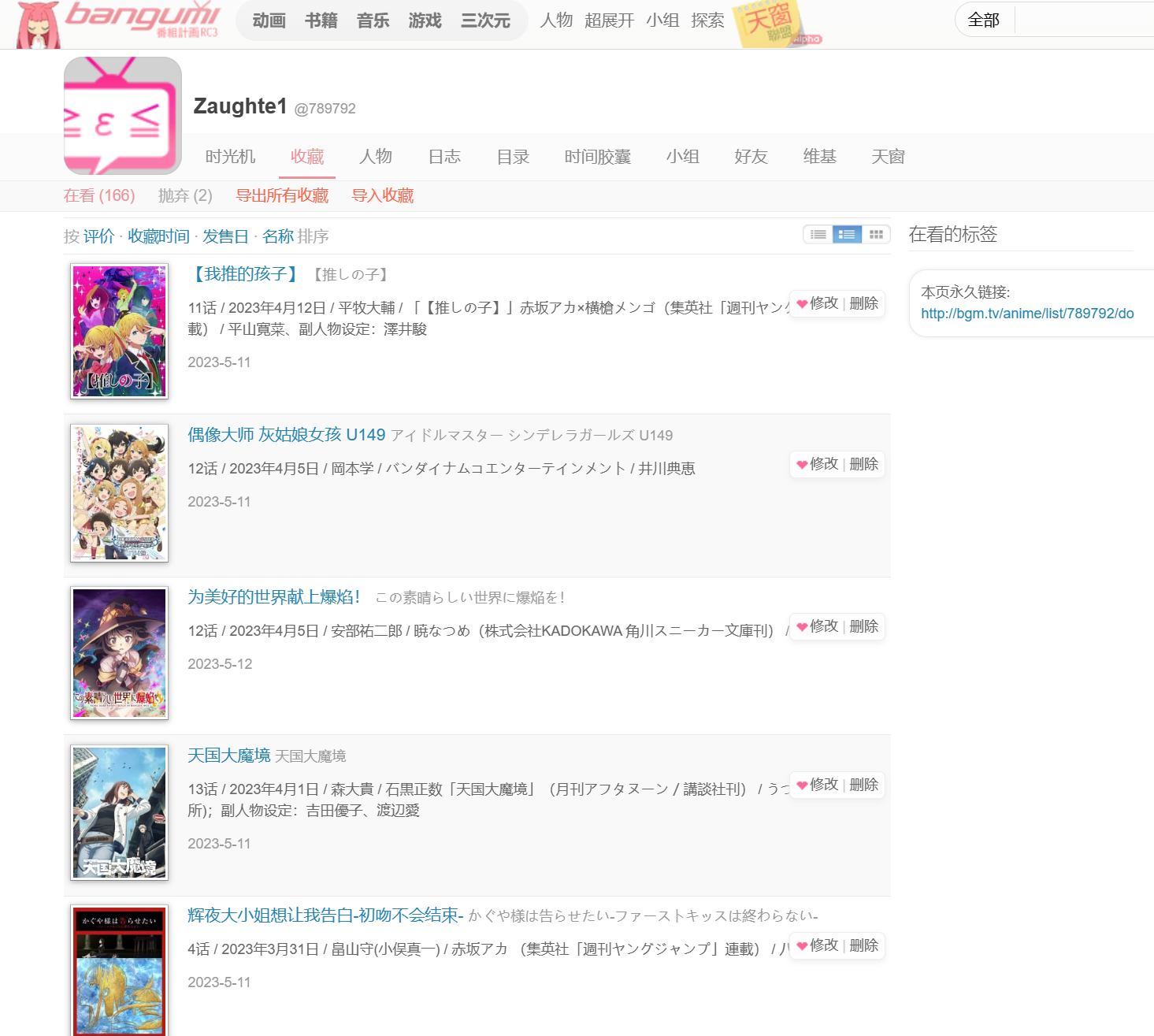
2.利用油猴脚本得到番剧名的excel
我用的是edge浏览器,可以直接添加油猴的扩展,然后去下载一个脚本,地址如下:bangumi collection export tool (greasyfork.org)

安装好后再去bangumi的在看界面,会发现脚本的按钮,于是便可以生成excel了

生成后把不重要的删除,保留重要的信息。这里我为了方便后面流程的展示就保留了22个番剧(我咋可能只看22个捏)
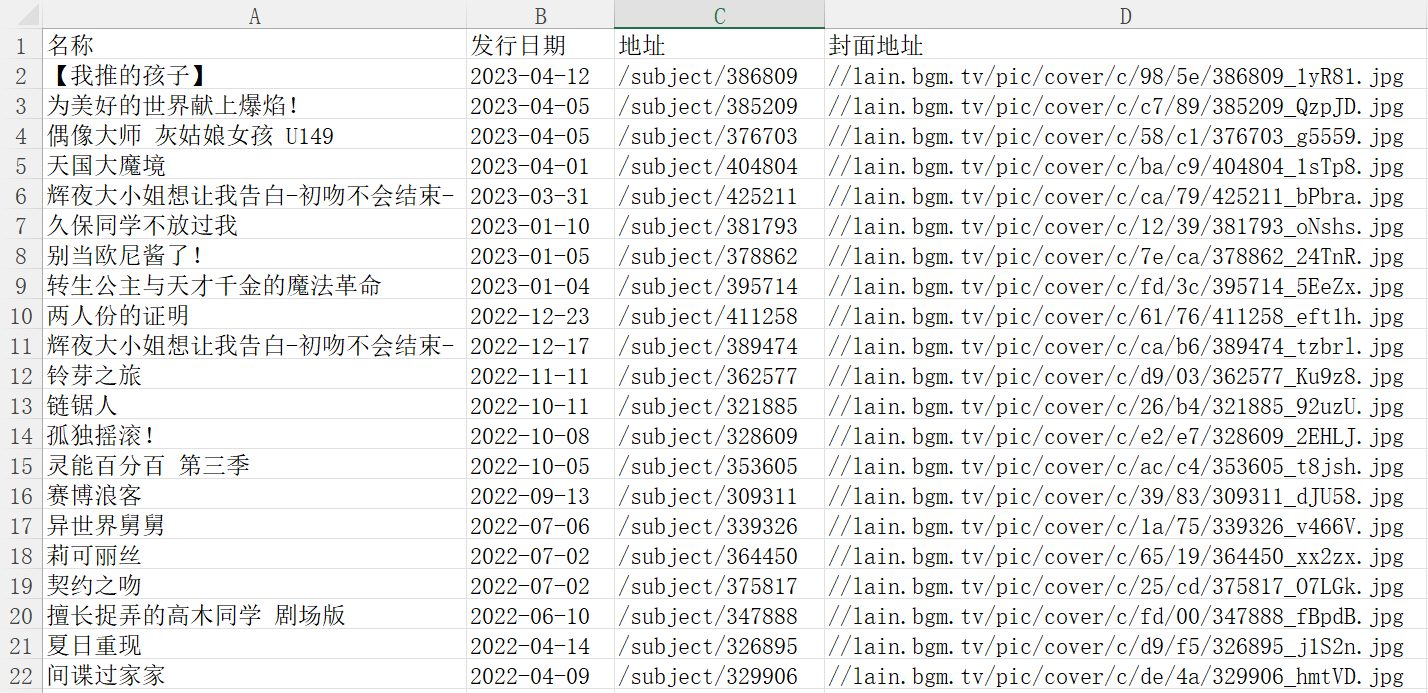
最后将封面地址中的内容进行替换,如下:
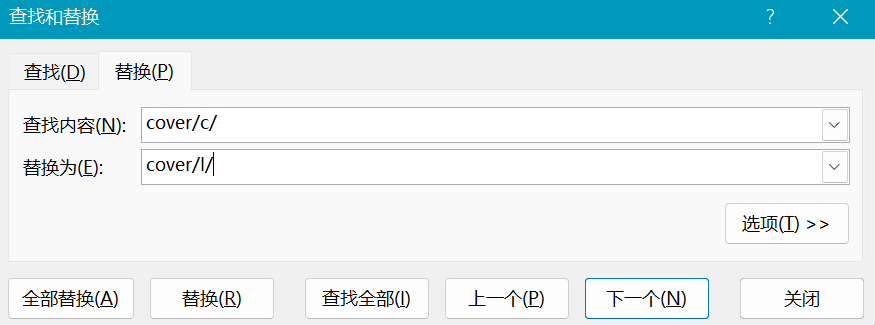
油猴脚本得到的封面图是最小版本的,不是很清晰,通过查看其他图片的url发现/c/是小图片,/l/是大图片,所以我们把excel中的都替换成大图片。如图左边为/l/,右边有/c/

3.excel转换为txt
非常简单的一步,上一篇文章我也说过了
由于我们只需要番剧名称,所以可以复制一份表,把其他东西全删掉


结果为:

4.moegirl_url_get.py
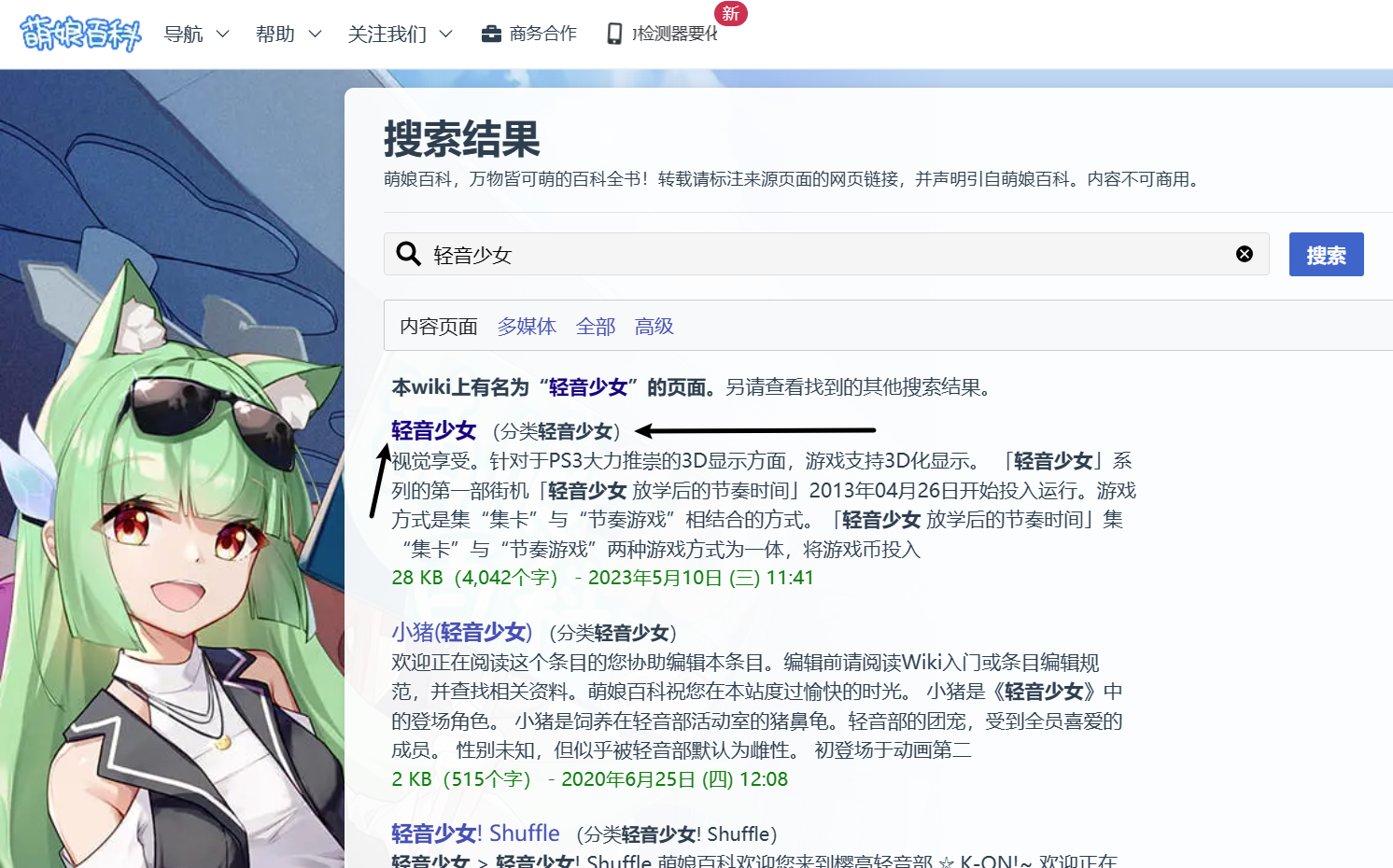
这个爬虫的思路其实很简单,就是模拟我们正常使用的流程,在萌娘百科的搜索页面搜索一个番剧名,查找后我们会得到一系列答案,爬虫默认第一个词条是我们要查找的结果,返回他的url
导入库
# coding=gbk
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
Movie类初始化
class Movie():
def __init__(self, name):
# 搜索url = 基础url + 名字
self.name = name
self.url = f'https://zh.moegirl.org.cn/index.php?search={name}&title=Special:搜索&profile=default&fulltext=1'
# 访问headers
self.headers = 'User-Agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36"'
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument(self.headers)
self.path = Service('chromedriver.exe')
self.browser = webdriver.Chrome(options=self.chrome_options, service=self.path)
self.wait = WebDriverWait(self.browser, 10)
首先我们要分析搜索页面的url构成
正常如下:https://zh.moegirl.org.cn/index.php?search=轻音少女&title=Special:搜索&profile=default&fulltext=1&searchToken=bzu62v92dvwr9ijjl0eq61hum
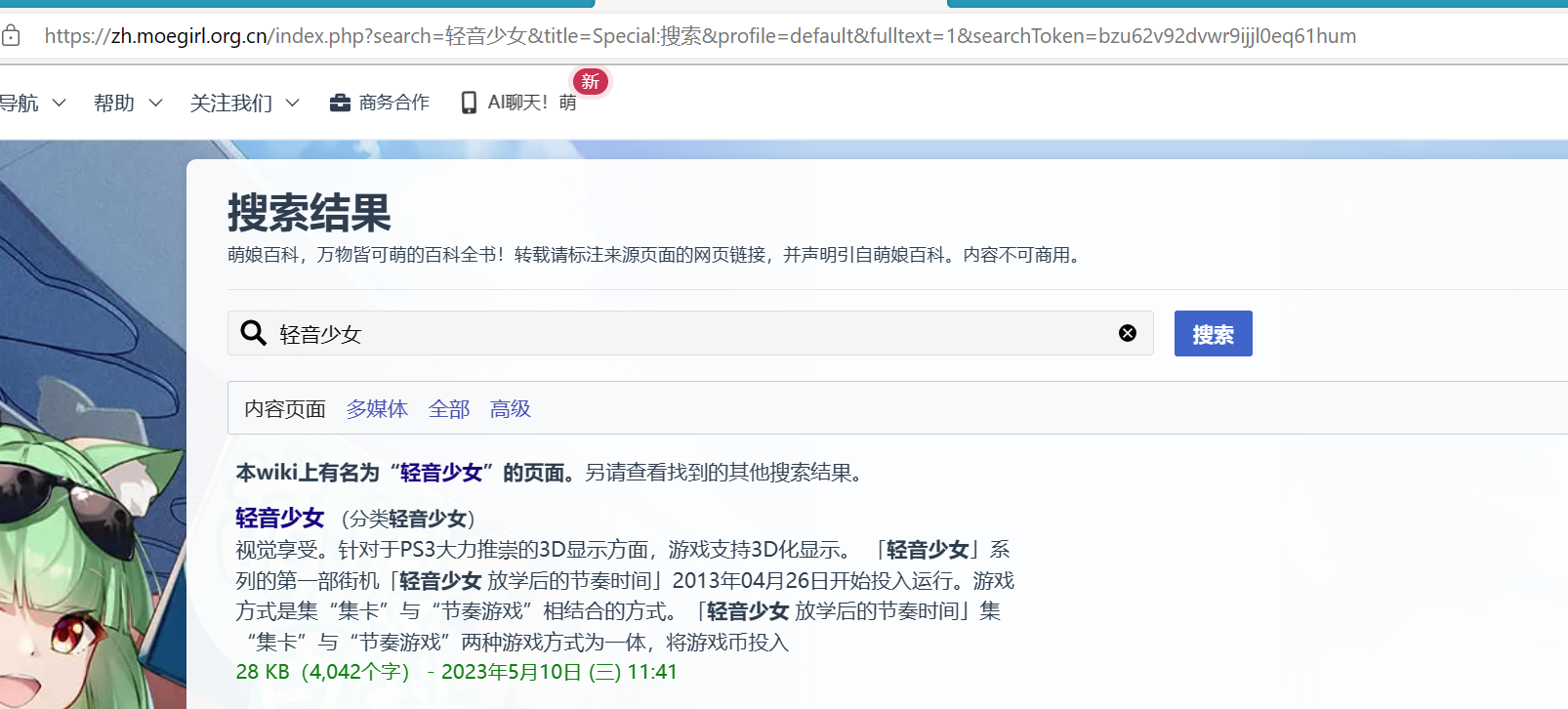
通过尝试,我们发现url尾部的searchToken并不是必要的,删除他的url:https://zh.moegirl.org.cn/index.php?search=轻音少女&title=Special:搜索&profile=default&fulltext=1会重定向到上面那个完整的url
我们发现搜索页面的搜索内容其实就是search后面的内容,其他的我们都不用改,因此我们就知道了方法
给Movie两个属性,一个是番名,一个是url模板+番名拼接形成的针对于该番剧的搜索页面url
访问headers固定,可以用我代码里的,也可以自己按F12查看一下,在搜索页面刷新一下看一下
其他属性默认
Movie方法
获取搜索结果,以便进一步选择
def get_search(self, log, o_list):
self.browser.get(self.url)
try: response = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".mw-search-result-heading > a")))
except:
TimeoutError
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
return None
print("success")
if response:
# print('请选择:')
movies = []
url = response.get_attribute('href')
self.browser.close()
o_list.write(str(self.name) + '\t' + str(url) + '\n')
print("查询到词条!")
return movies
else:
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
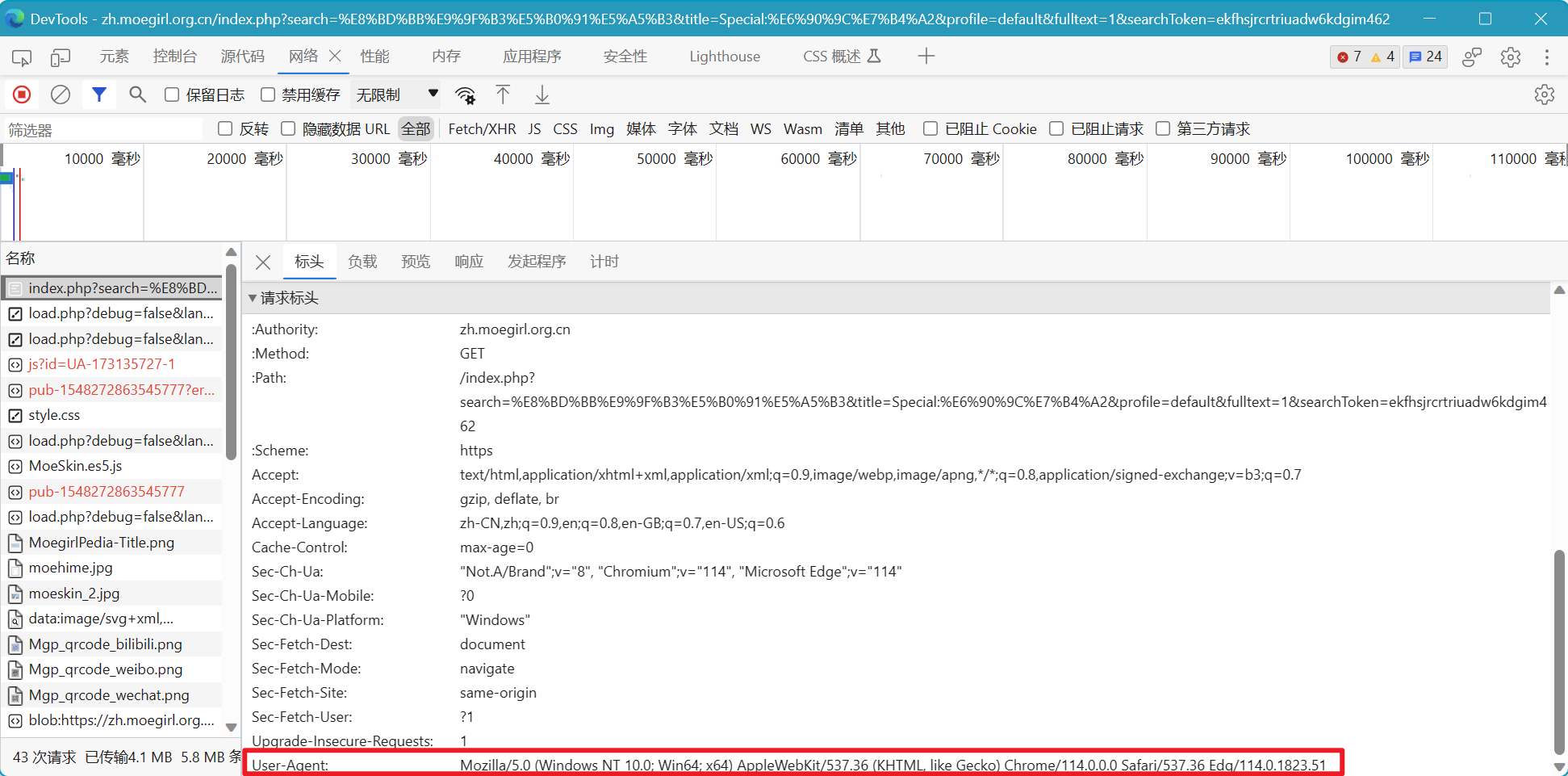
通过函数去拿搜索页面返回的response,这里需要我们按F12打开审查元素去找网站代码规律
首先通过EC.presence_of_element_located去定位资源,这个函数判断特定元素是否存在于页面DOM树中,如果是,返回该元素(单个元素),否则报错。更多内容可参考:Selenium学习之显式等待中的EC模块详解_,掌握 Selenium 元素定位,解决 Web 自动化测试痛点
定位方式我们选择By.CSS_SELECTOR,通过css表达式定位资源,更多内容可参考:Python - selenium-元素定位

通过查看页面CSS,我们发现搜索结果在class="mw-search-result-heading"空标签下的a标签中。我们默认第一个是正确答案,而正好EC.presence_of_element_located返回的是第一个内容。我们的CSS语法为.mw-search-result-heading > a,也就是我们找一个class属性为mw-search-result-heading的标签下的a标签
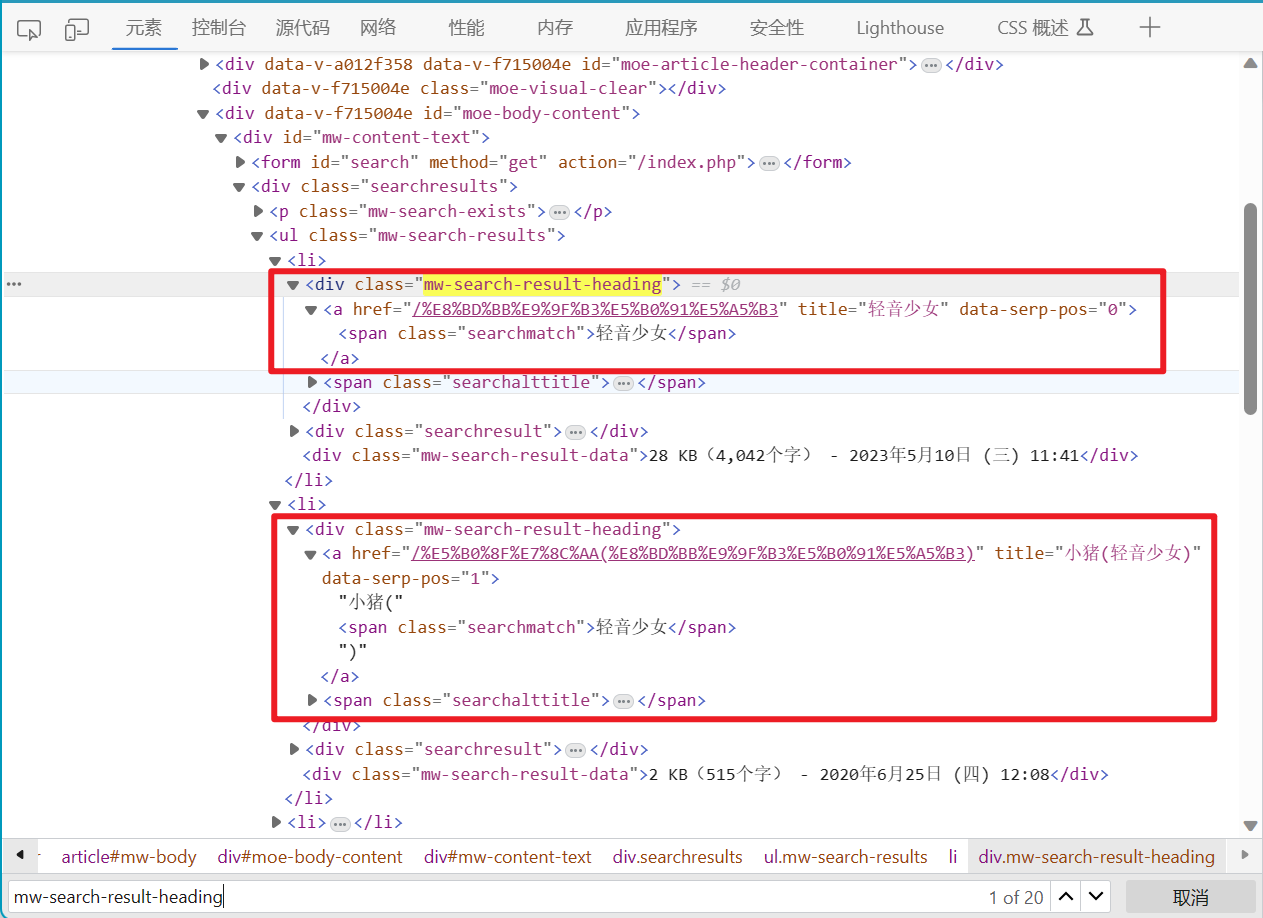
后面跟个try-catch,防止因为搜索时间过长爆TimeoutError导致整体爬虫被迫停止,except中我们为了方便检查,一条语句让把失败信息输出到控制台,一条语句让把报错的日志写到一个txt文件夹中汇总。后面的if-else则是防止没有找到词条爆错。
except:
TimeoutError
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
return None
如果我们搜索没有超时,同时确实得到了response,接下来就是简单的字符串获取
if response:
# print('请选择:')
movies = []
url = response.get_attribute('href')
self.browser.close()
o_list.write(str(self.name) + '\t' + str(url) + '\n')
print("查询到词条!")
return movies
我们获取response信息(a标签内容)中的href属性,那个便是第一个词条的url关键内容
最后做个拼接,把番剧内容和url写到一个txt文件中汇总,同时两个信息用制表符间隔
主函数
def main():
start_time = time.time()
path = 'C:/Users/zaughter/Desktop/test.txt'
o_list = open('moegirl_list.txt', mode='w')
log = open('moegirl_log.txt', mode='w')
i = 0
global_total = 0
with open(path) as f:
line = f.readline()
while line:
global_total += 1
i += 1
print("==========================")
print("正在处理第" + str(i) + "组数据")
movie_name = line.strip()
m = Movie(movie_name)
movies = m.get_search(log, o_list)
line = f.readline()
print("==========================")
end_time = time.time()
print("处理完毕! 共处理" + str(global_total) + "条数据,共用时:" + str(end_time-start_time) + "s")
if __name__ == '__main__':
main()
- 用
time函数分别记录开始与结束的时间戳,算出总用时,最后输出作为指示 path为步骤3生成的txt的位置- 创建两个txt,一个为输出文件,一个为日志文件
- 然后开始逐行读取txt文件,使用Movie对象的方法搞就完了
完整代码
# coding=gbk
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class Movie():
def __init__(self, name):
# 搜索url = 基础url + 名字
self.name = name
self.url = f'https://zh.moegirl.org.cn/index.php?search={name}&title=Special:搜索&profile=default&fulltext=1'
# 访问headers
self.headers = 'User-Agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36"'
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument(self.headers)
self.path = Service('chromedriver.exe')
self.browser = webdriver.Chrome(options=self.chrome_options, service=self.path)
self.wait = WebDriverWait(self.browser, 10)
# 获取搜索结果,以便进一步选择
def get_search(self, log, o_list):
self.browser.get(self.url)
try: response = self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".mw-search-result-heading > a")))
except:
TimeoutError
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
return None
print("success")
if response:
# print('请选择:')
movies = []
url = response.get_attribute('href')
self.browser.close()
o_list.write(str(self.name) + '\t' + str(url) + '\n')
print("查询到词条!")
return movies
else:
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
def main():
start_time = time.time()
path = 'C:/Users/zaughter/Desktop/test.txt'
o_list = open('moegirl_list.txt', mode='w')
log = open('moegirl_log.txt', mode='w')
i = 0
global_total = 0
with open(path) as f:
line = f.readline()
while line:
global_total += 1
i += 1
print("==========================")
print("正在处理第" + str(i) + "组数据")
movie_name = line.strip()
m = Movie(movie_name)
movies = m.get_search(log, o_list)
line = f.readline()
print("==========================")
end_time = time.time()
print("处理完毕! 共处理" + str(global_total) + "条数据,共用时:" + str(end_time-start_time) + "s")
if __name__ == '__main__':
main()
示例
输入txt文件如下:

萌娘百科最大的问题就是访问速度极慢,导致很容易出现TimeoutError,或者爬虫处理速度极慢,挂机就完了
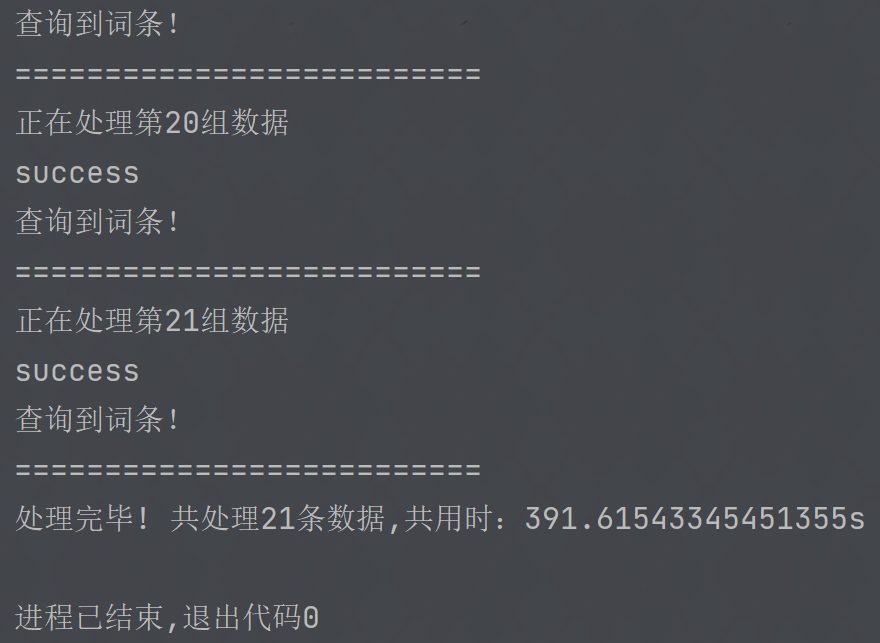
控制台输出结果如下:
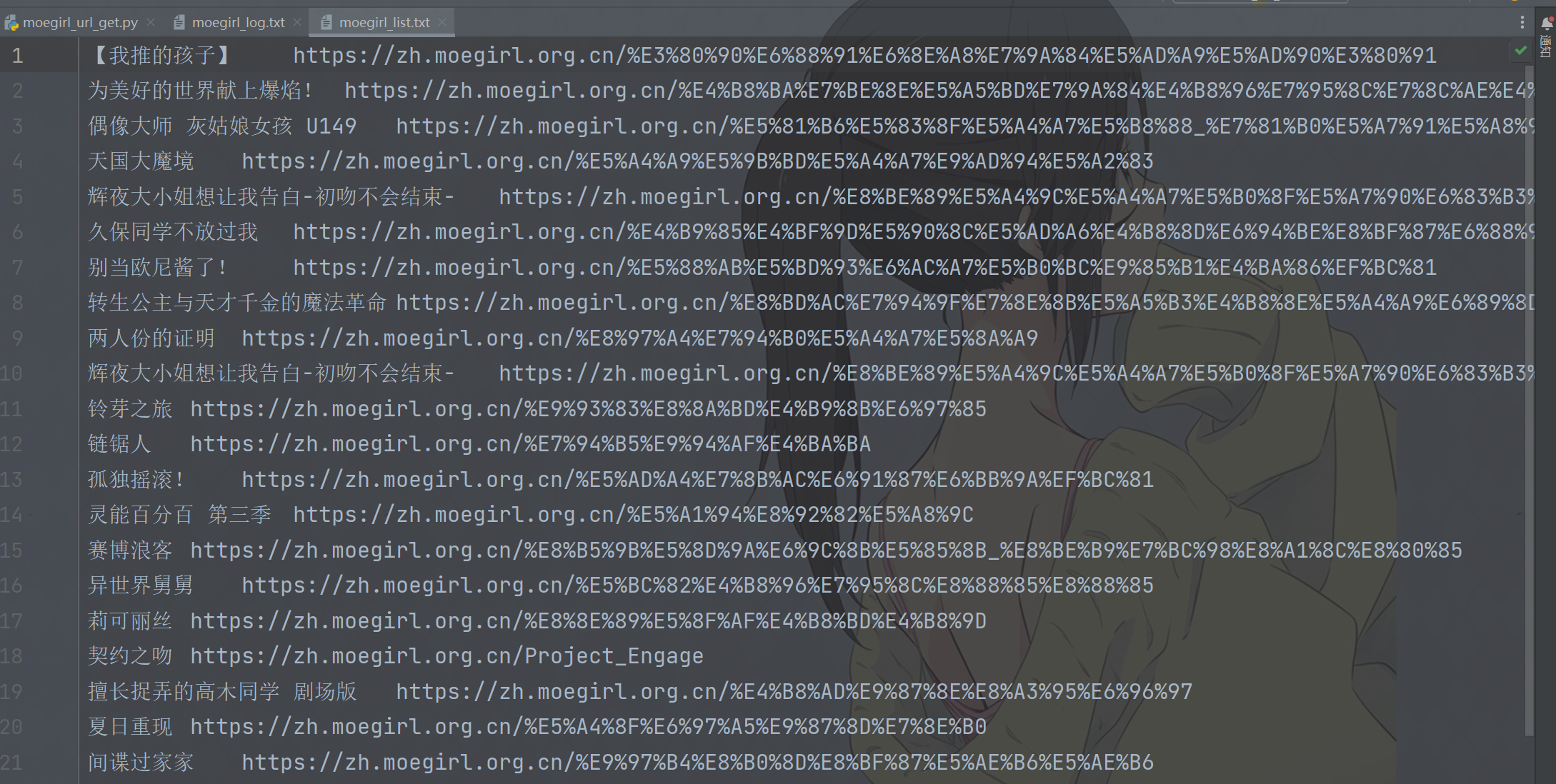
输出文件结果如下:
输出文件可能存在编码问题,直接“以GBK重新加载”即可

5.douban_info_get.py
基本内容与思路都与上面的相似甚至相同,所以这里我就不细讲了(打文章坐的屁股开始疼了)
导入库
import os.path
import re
import bs4
import time
import requests
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
Movie类初始化
与豆瓣一样
class Movie():
def __init__(self, name):
# 搜索url = 基础url + 名字
self.name = name
self.url = f'https://search.douban.com/movie/subject_search?search_text={name}'
# 访问headers
self.headers = 'User-Agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36"'
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument(self.headers)
self.path = Service('chromedriver.exe')
self.browser = webdriver.Chrome(options=self.chrome_options, service=self.path)
self.wait = WebDriverWait(self.browser, 10)
Movie方法1:找到页面url
# 获取搜索结果,以便进一步选择
def get_search(self, log):
self.browser.get(self.url)
try:response = self.wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.title > a')))
except:
TimeoutError
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
if response:
# print('请选择:')
movies = []
name = response[0].text
url = response[0].get_attribute('href')
# print(f'{[i]}.{name}')
movies.append([name, url])
self.browser.close()
print("查询到词条!")
return movies
else:
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
这里用了EC.presence_of_all_elements_located,获取的是所有符合的元素放到了一个数组里,由于我们现在为了方便直接默认是第一个,所以后面就直接用response[0]。如果处理番剧数较少,我们可以在控制台输出前5个词条,手动选择正确的那个,可以提高数据正确率(有些番剧有第二季或者有剧场版,可能导致爬虫数据结果有问题)
看一下CSS,其实还有一些标签也符合class属性,但是他们子标签没有a标签

拿到response,取数组第0位,也即是第一个词条,然后拿href属性内容,那个就是番剧在豆瓣里的对应页面的url
注意:movies.append([name, url]),我们是把一对数据作为整体存进movies数组里的,后面要考
Movie方法2:爬取信息
# 在影片详情页面提取影片基本信息
def get_movie_info(self, movie, o_list, movie_name, log):
name = movie[0]
url = movie[1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'}
resp = requests.get(url, headers=headers)
try:
if resp.status_code == 200:
soup = bs4.BeautifulSoup(resp.text, 'html.parser')
info = soup.find(name='div', attrs={'id': 'info'}).text
# 1:导演
# 2:编剧
# 3:主演
# 8:首播
info_list = info.split('\n')
rating = soup.find(name='div', attrs={'class': 'rating_self'})
rating_num = rating.strong.text
# 名字 时间 评分 导演 编剧 主演 豆瓣url 海报url
o_list.write(movie_name + '\t' + rating_num + '\t' + info_list[1] + '\t' + info_list[2] + '\t' + info_list[3] + '\t' + url + '\t' + url + 'photos?type=R' + '\n')
print("数据爬取成功!")
picd = Picdown(url + 'photos?type=R')
picd.download_pic(movie_name, log)
else:
return None
except requests.exceptions:
print(str(self.name) + " " + "数据获取失败")
log.write(str(self.name) + " " + "数据获取失败\n")
return None
name和url的提取就是我上面说的,因为我们存movies里的是一个数组,所以单个元素也是个数组,现在我们再把这个数组拆开,内容分开存储
通过BeautifulSoup得到response里面的内容,按照属性(id=info)查找div标签,然后返回
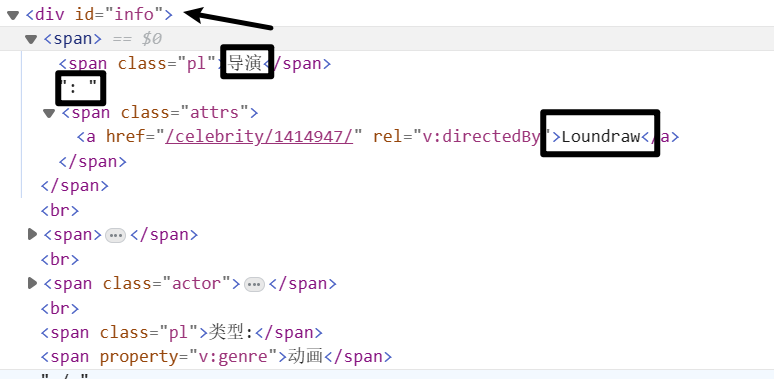
我们再通过spilt拆分,即可得到各个信息
Picdown初始化
这个是用来爬取番剧相关图片的类,初始化与Movie同理,注意一下传入的url即可
def __init__(self, u):
self.url = f'{u}'
# 访问headers
self.headers = 'User-Agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36"'
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument(self.headers)
self.path = Service('chromedriver.exe')
self.browser = webdriver.Chrome(options=self.chrome_options, service=self.path)
self.wait = WebDriverWait(self.browser, 10)
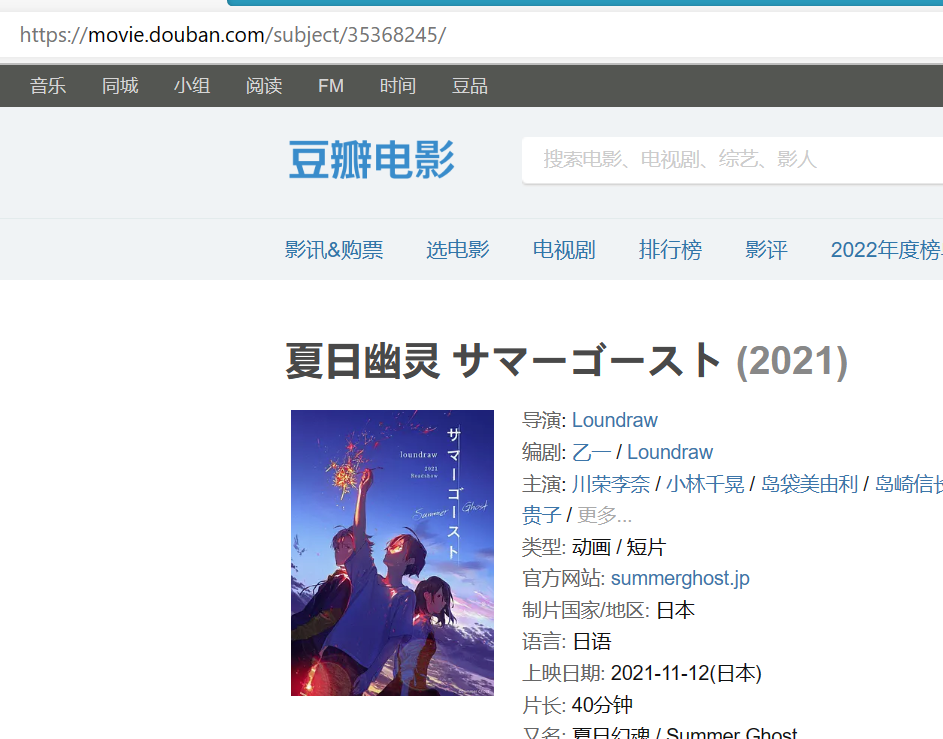
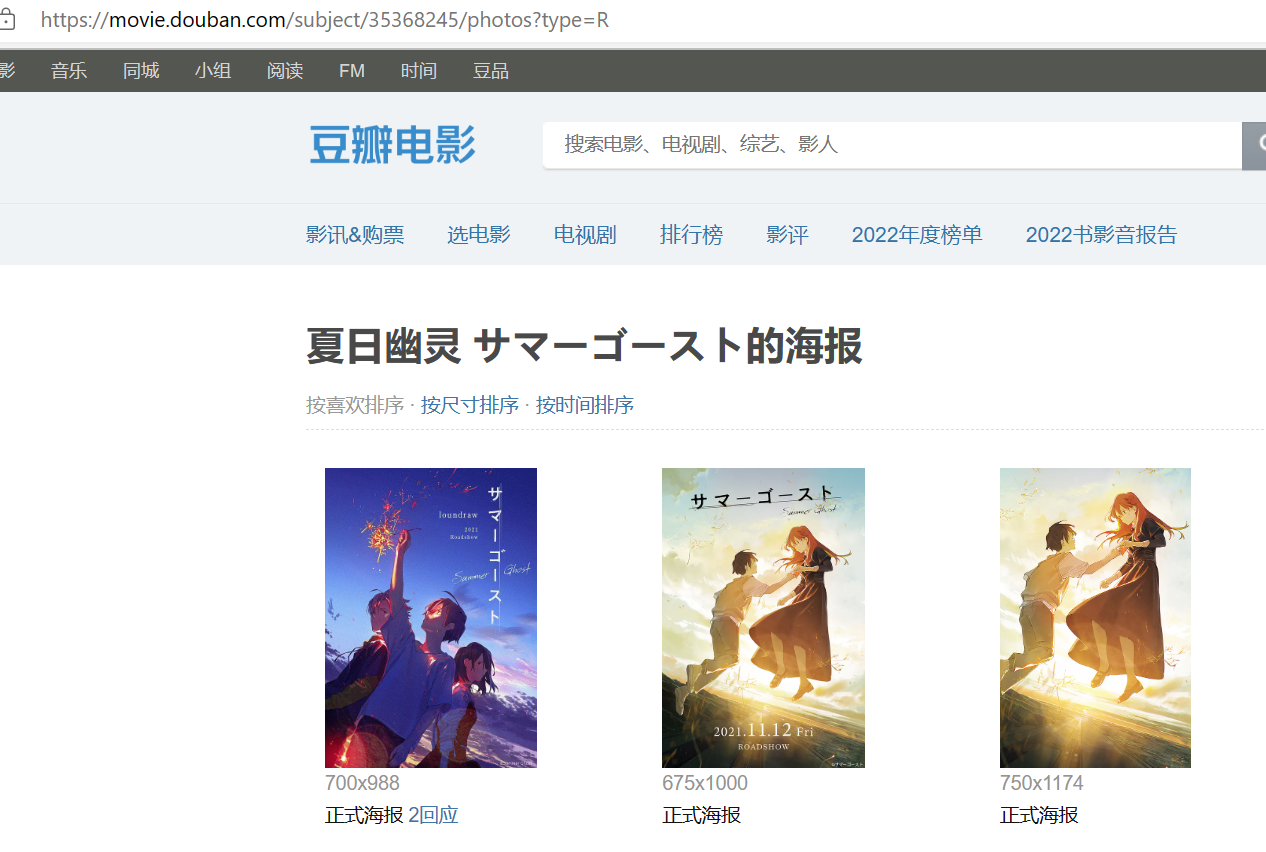
在进入番剧页面后,我们发现有个相关图片的url,而且规律是可以直接推出来的,我们就是要进那里下载图片。规律如下:picd = Picdown(url + 'photos?type=R'),其实url为番剧页面
Picdown方法:下载图片
def download_pic(self, name, log):
url = self.url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'}
resp = requests.get(url, headers=headers)
try:
if resp.status_code == 200:
soup = bs4.BeautifulSoup(resp.text, 'html.parser')
pic_url_list = soup.find_all(name="img", src=re.compile('doubanio.com/view/photo'))
i = 1
fix_name = name.replace("/", " ")
print(fix_name)
if not os.path.exists("图库/" + str(fix_name)):
try:
os.makedirs("图库/" + str(fix_name))
except OSError:
print(name + " " + "名称不合法")
log.write(name + " " + "名称不合法\n")
return None
for pic_url in pic_url_list:
raw_pic_url = str(pic_url).replace('/m/', '/l/').split('\"')[1]
r = requests.get(raw_pic_url, headers=headers)
local = "图库/" + str(fix_name) + '/' + str(i) + ".jpg"
f = open(local, 'wb')
f.write(r.content)
f.close()
print("下载图片进度:" + str(i) + "/" + str(len(pic_url_list)))
i += 1
print("图片下载成功!")
return None
except requests.exceptions:
print(name + " " + "下载图片失败")
log.write(name + " " + "下载图片失败\n")
return None
首先要得到所有图片的具体url
pic_url_list = soup.find_all(name="img", src=re.compile('doubanio.com/view/photo'))
我们查找name为img的标签,但是发现存在问题,因为还有一部分这类标签存的是用户头像我们不需要
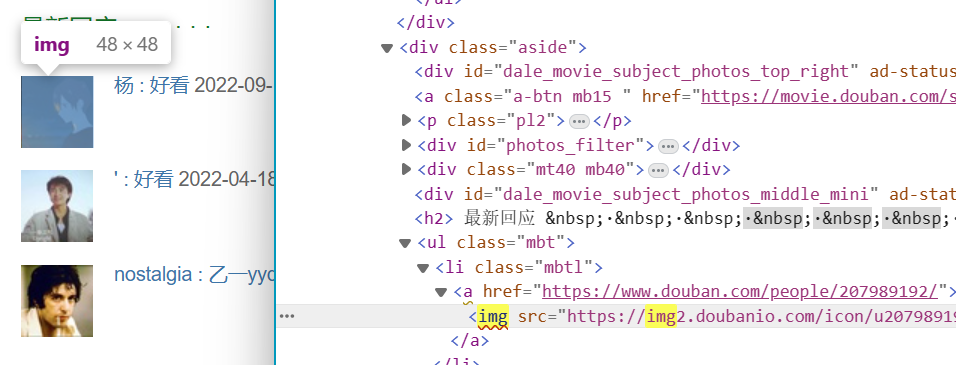
因此再使用src=re.compile让爬虫只查找含有doubanio.com/view/photo的内容,这样头像url因为不含有这个字符串而被筛选掉了

后面下载前,我们把图片url中的/m/改成/l/,原因同理,这样的图片更大。其实还有个/r/(意思是raw,未处理图片),但是这个图片url进入的时候会检测账号,影响脚本效率,所以不用。而且有时候l和r是一个尺寸

主函数
def main():
path = 'C:/Users/zaughter/Desktop/test.txt'
o_list = open('douban_list.txt', mode='a', encoding='utf-8')
log = open('douban_log.txt', mode='a', encoding='utf-8')
i = 0
global_total = 0
start_time = time.time()
with open(path) as f:
line = f.readline()
while line:
global_total += 1
i += 1
print("==========================")
print("正在处理第" + str(i) + "组数据")
movie_name = line.strip()
m = Movie(movie_name)
movies = m.get_search(log)
m.get_movie_info(movies[0], o_list, movie_name, log)
line = f.readline()
print("==========================")
end_time = time.time()
print("处理完毕! 共处理" + str(global_total) + "条数据,共用时:" + str(end_time-start_time) + "s")
if __name__ == '__main__':
main()
完整代码
import os.path
import re
import bs4
import time
import requests
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class Picdown():
def __init__(self, u):
self.url = f'{u}'
# 访问headers
self.headers = 'User-Agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36"'
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument(self.headers)
self.path = Service('chromedriver.exe')
self.browser = webdriver.Chrome(options=self.chrome_options, service=self.path)
self.wait = WebDriverWait(self.browser, 10)
# 下载图片
def download_pic(self, name, log):
url = self.url
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'}
resp = requests.get(url, headers=headers)
try:
if resp.status_code == 200:
soup = bs4.BeautifulSoup(resp.text, 'html.parser')
pic_url_list = soup.find_all(name="img", src=re.compile('doubanio.com/view/photo'))
i = 1
fix_name = name.replace("/", " ")
print(fix_name)
if not os.path.exists("图库/" + str(fix_name)):
try:
os.makedirs("图库/" + str(fix_name))
except OSError:
print(name + " " + "名称不合法")
log.write(name + " " + "名称不合法\n")
return None
for pic_url in pic_url_list:
raw_pic_url = str(pic_url).replace('/m/', '/l/').split('\"')[1]
r = requests.get(raw_pic_url, headers=headers)
local = "图库/" + str(fix_name) + '/' + str(i) + ".jpg"
f = open(local, 'wb')
f.write(r.content)
f.close()
print("下载图片进度:" + str(i) + "/" + str(len(pic_url_list)))
i += 1
print("图片下载成功!")
return None
except requests.exceptions:
print(name + " " + "下载图片失败")
log.write(name + " " + "下载图片失败\n")
return None
class Movie():
def __init__(self, name):
# 搜索url = 基础url + 名字
self.name = name
self.url = f'https://search.douban.com/movie/subject_search?search_text={name}'
# 访问headers
self.headers = 'User-Agent="Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' \
'Chrome/78.0.3904.108 Safari/537.36"'
self.chrome_options = webdriver.ChromeOptions()
self.chrome_options.add_argument('--headless')
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument(self.headers)
self.path = Service('chromedriver.exe')
self.browser = webdriver.Chrome(options=self.chrome_options, service=self.path)
self.wait = WebDriverWait(self.browser, 10)
# 获取搜索结果,以便进一步选择
def get_search(self, log):
self.browser.get(self.url)
try:response = self.wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.title > a')))
except:
TimeoutError
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
if response:
# print('请选择:')
movies = []
name = response[0].text
url = response[0].get_attribute('href')
# print(f'{[i]}.{name}')
movies.append([name, url])
self.browser.close()
print("查询到词条!")
return movies
else:
print("没有搜到" + str(self.name))
log.write(str(self.name) + " " + "未搜索到词条\n")
# 在影片详情页面提取影片基本信息
def get_movie_info(self, movie, o_list, movie_name, log):
name = movie[0]
url = movie[1]
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'}
resp = requests.get(url, headers=headers)
try:
if resp.status_code == 200:
soup = bs4.BeautifulSoup(resp.text, 'html.parser')
info = soup.find(name='div', attrs={'id': 'info'}).text
# 1:导演
# 2:编剧
# 3:主演
# 8:首播
info_list = info.split('\n')
rating = soup.find(name='div', attrs={'class': 'rating_self'})
rating_num = rating.strong.text
# 名字 时间 评分 导演 编剧 主演 豆瓣url 海报url
o_list.write(movie_name + '\t' + rating_num + '\t' + info_list[1] + '\t' + info_list[2] + '\t' + info_list[3] + '\t' + url + '\t' + url + 'photos?type=R' + '\n')
print("数据爬取成功!")
picd = Picdown(url + 'photos?type=R')
picd.download_pic(movie_name, log)
else:
return None
except requests.exceptions:
print(str(self.name) + " " + "数据获取失败")
log.write(str(self.name) + " " + "数据获取失败\n")
return None
def main():
path = 'C:/Users/zaughter/Desktop/test.txt'
o_list = open('douban_list.txt', mode='a', encoding='utf-8')
log = open('douban_log.txt', mode='a', encoding='utf-8')
i = 0
global_total = 0
start_time = time.time()
with open(path) as f:
line = f.readline()
while line:
global_total += 1
i += 1
print("==========================")
print("正在处理第" + str(i) + "组数据")
movie_name = line.strip()
m = Movie(movie_name)
movies = m.get_search(log)
m.get_movie_info(movies[0], o_list, movie_name, log)
line = f.readline()
print("==========================")
end_time = time.time()
print("处理完毕! 共处理" + str(global_total) + "条数据,共用时:" + str(end_time-start_time) + "s")
if __name__ == '__main__':
main()
示例
输入txt内容如下:

控制台输出如下:

生成txt如下:

未出错,日志为空。
爬取图片如下:
6.excel合并
思路与方法
- 基于bangumi得到的excel进行整理

-
将两个爬虫得到的txt转换为excel
-
-

-
通过复制粘贴做成普通excel

-
-
目前我们有两个工作表:用户收藏+moegirl_list,前者为步骤1的,后者为步骤2中萌娘百科的
-
在用户收藏中新建一列用来保存萌娘百科地址的数据

-
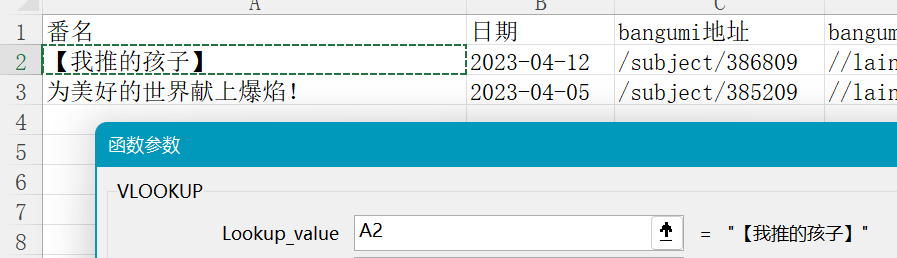
对E2使用VLOOKUP函数
-
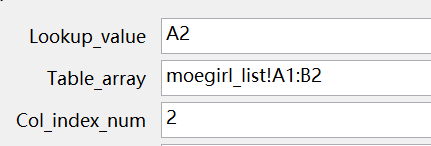
里面一共有4个参数,我们一个一个看
-
Lookup_value(查找值):用来关联两表的共同信息,这里我们是通过番名来关联的,所以选择A2
-
Table_array(数据表):要合并的那张表的目标数据,包括匹配列和目标数据列。我们这里切换到萌娘百科的那一个工作表,把所有内容圈上,意思是我们的共同项和对应的要合并的数据在这个范围内,系统自己去找

-
Col_index_num(列序数):指要合并的内容在第二个参数中选中的那一片数据的哪一列。它是以匹配列为基准计算的。我们最后要合并的是萌百工作表中的第二列那些地址,所以我们输入数字2
-
Range_lookup(匹配条件):最好理解的就是这个了,精确匹配:FALSE, 大致匹配:TRUE
-
最后匹配成功


-
-
快速处理其他行:我们直接拉动,发现函数出现了一些问题,我们看第二行的函数变成了:

第一个值没问题,第二个值的范围变了,原来是红色区域,现在是蓝色区域

然而这个值是不会变化的,所以我们直接对第一个函数进行修改,加上绝对符号$,然后再拉

现在第二行的函数为:

结束!
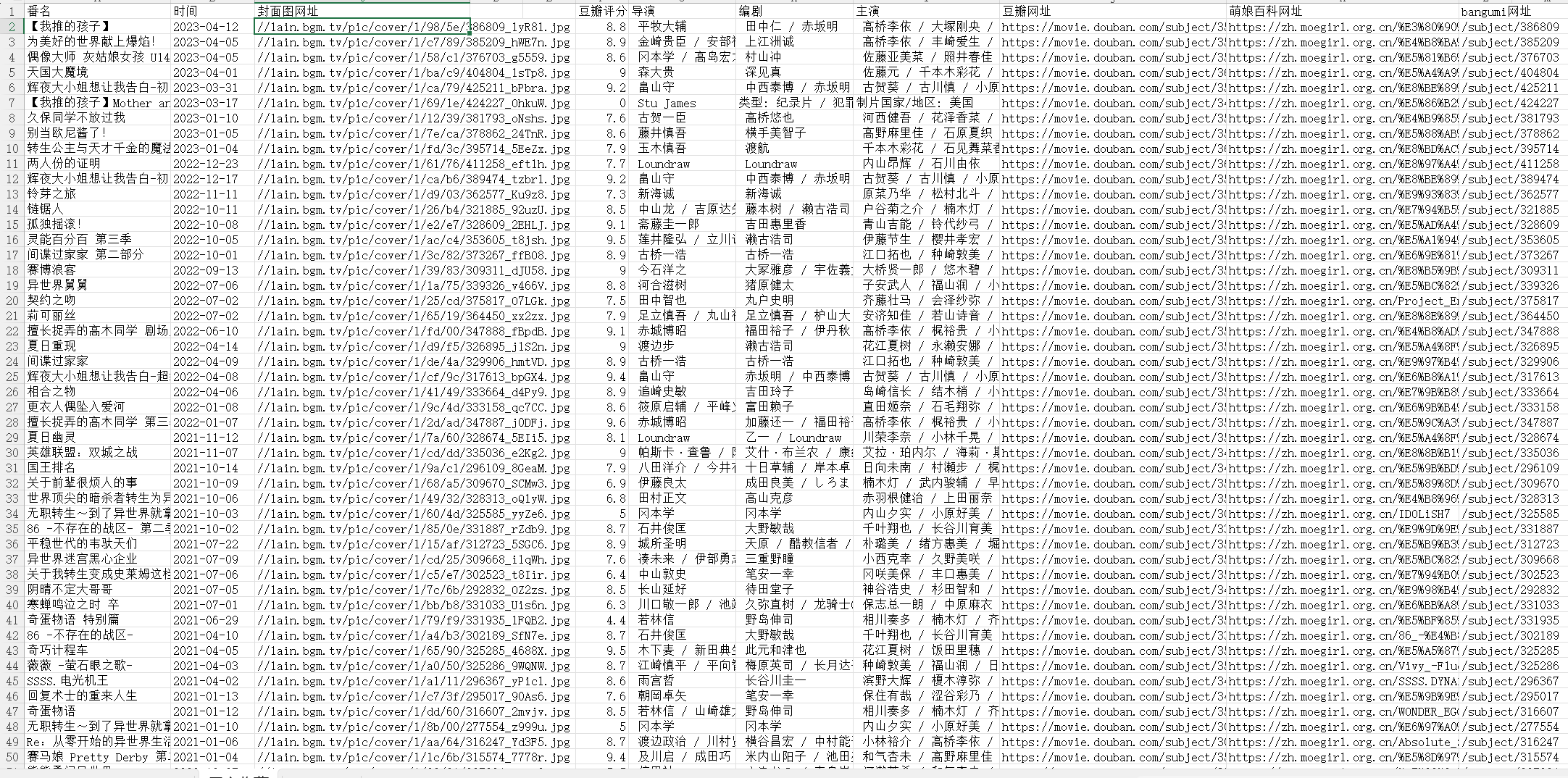
成果展示
结语
不容易,终于写完了,当时写了一半沉迷游戏润了,回学校后给写完了。
属于第一次为爱付出努力,感觉还是挺有意义的,期间学到了很多知识。














 8673
8673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









