







原文:Consensus One-step Multi-view Subspace Clustering
创新点:
传统的子空间聚类分为两个步骤。首先是学一个亲和矩阵,也就是原文中的 Z Z Z。这个 Z Z Z就代表了各个数据之间的相似关系。然后再将这个 Z Z Z丢到其他聚类算法,比如kmeans或者谱聚类中去进行聚类的步骤。
这篇文章将两个步骤合二为一了。我们可以直接得到 Y Y Y,即隶属度。
这篇文章的实验精度可以说提升得很明显了,表征学习和聚类过程合二为一,是一个值得研究的方向。
目标函数
首先是标准的基于自表示的子空间分割:

Z
Z
Z是亲和矩阵。然后根据
T
h
e
o
r
e
m
1
Theorem 1
Theorem1,理想的亲和矩阵所划分出来的聚类簇数就是其对应的拉普拉斯矩阵的0特征值的个数。一个矩阵的0特征值的个数又等于其维数减去秩。即
k
=
n
−
r
a
n
k
(
L
)
k=n-rank(L)
k=n−rank(L)整理一下并带上视图数量就是:
r
a
n
k
(
L
v
)
=
n
−
k
rank(L^v) = n − k
rank(Lv)=n−k
加在目标函数中:
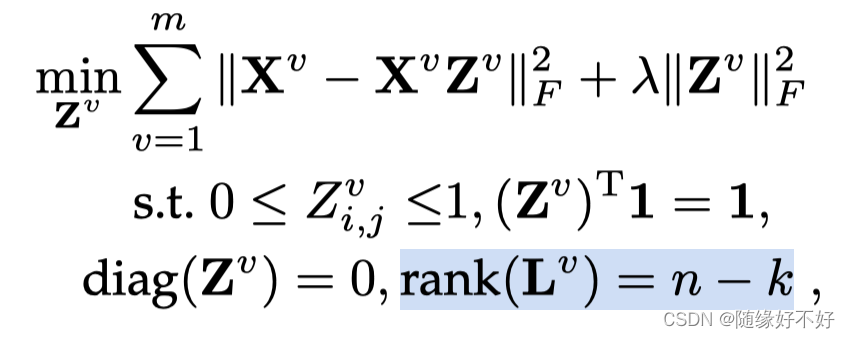
这个形式不好求解,根据参考文献[39],整理为以下形式:
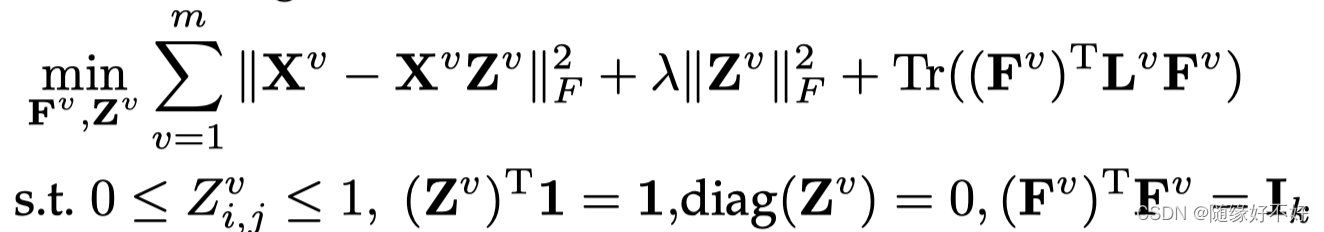
这里的
F
F
F是一个表征矩阵,可以代表
X
X
X,由于特征数量从
d
d
d降到了
k
k
k,所以也相当于做了降维处理。这个
T
r
(
(
F
v
)
T
L
v
F
v
)
Tr((F^v)^TL^vF^v)
Tr((Fv)TLvFv)不好理解,在另一篇论文中,有作者进行了推导:
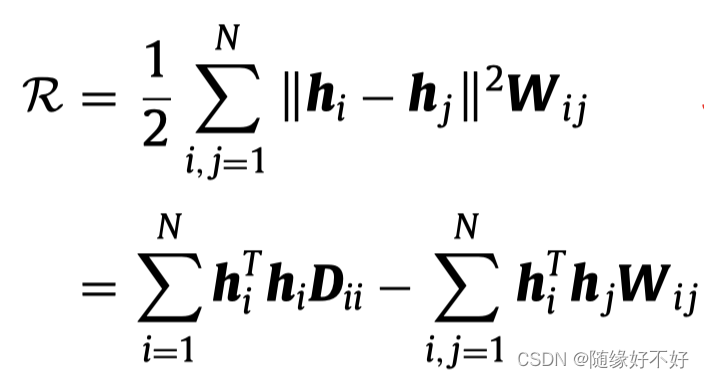
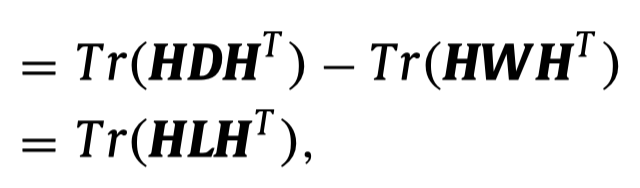
这里的
H
H
H就是
F
F
F,
W
W
W是相似度。还原到第一行可以发现这个公式的意义:在
x
x
x转化为
h
h
h后,距离更近的
x
x
x所转化为的
h
h
h应该更相似。再加上正交这个条件,即每个h都应该尽可能用最少的特征进行表示,可以减少特征之间的冗余度。
然后添加下面这一项,求一个全局的表征矩阵:
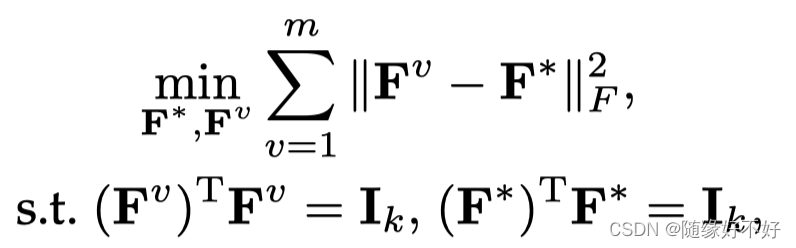
下面这一步是整个算法的精华。表征矩阵求出来之后,并不是提取出来再参与聚类,而是通过下面这一项,将聚类过程也加入了目标函数。
我们先去掉两个求和符号:
![]()
- Y Y Y是隶属度矩阵。
- t c t_c tc是一个 1 ∗ k 1*k 1∗k的向量,该向量只有第 c c c个位置的元素为1,其他位置都为 0 0 0,表示簇中心点的坐标。
- F F F是表征矩阵
- R R R是旋转矩阵。将 F F F在高维空间进行角度旋转,长度不变
隶属度不解释。主要是后面那一项是什么意思?
前面说了,F有个特点,就是每个数据都用尽可能少的特征表示,如果完全正交的话,每个数据只会用一个特征表示。
假如这里有四个三维数据:
x
1
=
[
1
,
0
,
0
]
;
x_1=[1,0,0];
x1=[1,0,0];
x
2
=
[
1
,
0
,
0
]
;
x_2=[1,0,0];
x2=[1,0,0];
x
3
=
[
0
,
1
,
0
]
;
x_3=[0,1,0];
x3=[0,1,0];
x
4
=
[
0
,
0
,
1
]
x_4=[0,0,1]
x4=[0,0,1]
每个数据都只用了一个特征表示。将数据分为三簇, t c t_c tc就应该有三个:
t
1
=
[
1
,
0
,
0
]
;
t_1=[1,0,0];
t1=[1,0,0];
t
2
=
[
0
,
1
,
0
]
;
t_2=[0,1,0];
t2=[0,1,0];
t
3
=
[
0
,
0
,
1
]
t_3=[0,0,1]
t3=[0,0,1]
用肉眼看,很明显 x 1 x_1 x1、 x 2 x_2 x2应该分到 t 1 t_1 t1这一簇, x 3 x_3 x3和 x 4 x_4 x4分别分到 t 2 t_2 t2和t 3 _3 3。如果把各个 t c t_c tc和各个数据之间求距离一个距离,显然每个中心和自己对应的数据之间的距离是最小的。 t 1 t_1 t1到 x 1 x_1 x1的距离肯定比到 x 3 x_3 x3小。
那为什么要旋转呢?
因为…
你比如说,下面这个矩阵也是正交矩阵:
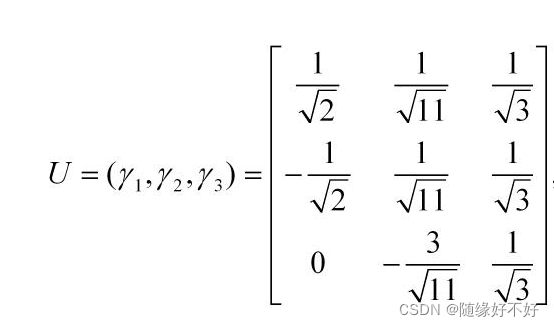
这就需要旋转了。
完整的目标函数:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









