










1 简介
今天向大家介绍一个帮助往届学生完成的毕业设计项目,微博情感分析可视化系统。
搜集了大量微博研究的相关文献之后,目前使用最多的研究方法是情感词典的方法:通过构建相应的微博情感词典,分析微博评论的极性;另一种是机器学习的方法,通过构建的模型判断文字正负。建立了专属于微博的情感词典,选择相关的微博评论,提高情感分类的准确率。
****过程概述:****获取相关评论文本,进行预处理,然后,使用专属于微博的情感词典,对其进行特征提取等操作,和相应的处理消极词汇、程度副词、微博表情符号、情感词和评价对象的微博评论。最后采用算法公式,对已处理好的数据进行正负分类,达到一个准确的分类效果。
在微博上挑选热点话题,实验数据包含生活、交通事故、微博话题领域的科学与技术三个领域。
主要研究内容和挑战:
结合汉语情感词本体数据库,构建了具有情感强度的基本情感词。也会构建程度副词和否定词等情感词典。提出了一种计算词汇语义相似度的方法,构建了一个领域情感词典。
首先对文本进行观点识别,再进行评论分析。
采用情感倾向加权的方法对微博评论进行情感计算。加权方式区分情感强弱,体现差异性。
研究步骤:
获取评论数据,预处理,删除有噪声的信息,如位置信息,url,昵称等。再利用word2vec转为词向量。
分为正负两组极性评论。
每个特征值贡献值不一样,采用权重分配,对于贡献值最大的特征,赋予较大的权重。
微博文章有很强的语言特性,开放数据集比较小,抓取数据时如何处理数据是一个复杂的工作,删除噪音信息
中文微博情感分析的挑战:
中文语言变化丰富,不同语境不同含义,不规范化,多样化。语法复杂。穿插表情或图片。
情感词典构建困难。《普通询问者》是一部比较完整的中国情感辞典。
微博内容含有未记录词语,国内分析研究不成熟。
文本预处理;
分词包:庖丁解牛分词包,IKAnalyzer,jieba分词
停用词处理
情感词典:
知网how net
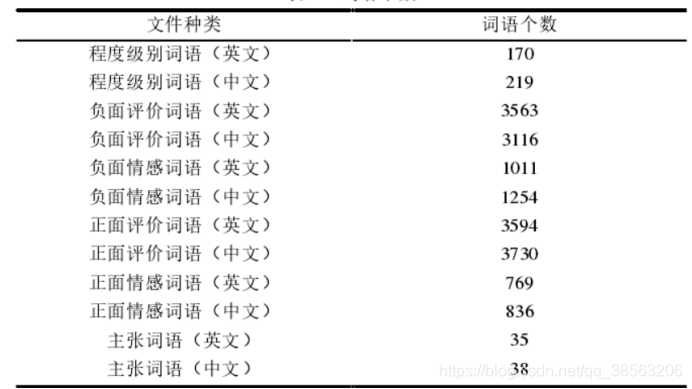
大连理工-情感词汇本体库
按照词语极性分类,正-1,负-2,中-0
台湾大学NTUSD
正负面情绪词集:2810、8276
哈工大同义词词林扩展版
****特征降维:****特征提取维数太多降低特征提取的准确率。通常采用特征选择和特征抽取。
特征选择:从所有维度特征中选择一个子集,将子集作为新的特征。
基于文档频率特征提取,卡方统计量,信息增益法,互信息法。
特征抽取:将高纬度特征通过函数映射到低纬度,得到新的特征。非监督的主成分分析法,监督的局部线性嵌入。
****微博特征选取:****基于语义规则的特征提取也经常被用到,它比基于统计的方法更加准备有效,该方法考虑上下文以及内在关系,经常被使用。
一段微博评论文本,除情感词外,删除无关特征词。在特征选择上注意图片,表情符号。取哪些特征值得思考。
分类器种类:朴素贝叶斯分类器,决策树,k-最近邻法,支持向量机。
评估指标:准确率accuracy,召回率recall,F-测度值(改变变量值,f1,f2,f0.5值)

基于情感词典微博评论情感分类:
构建情感词典:
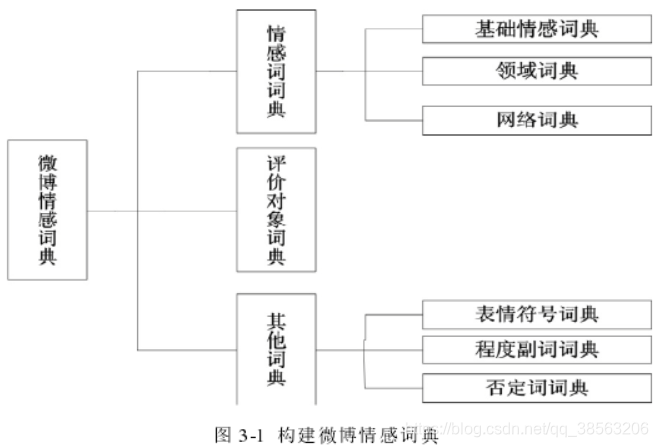
文章主要构建了五个部分的情感词典:
****基础情感词典:****采用林鸿飞教授等人的数据库,结合微博特点,构建微博情感词典
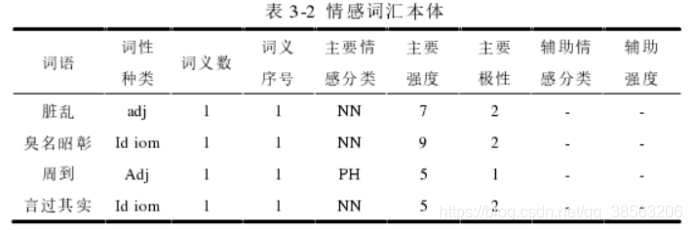
积极情绪:10541种,消极情绪:10102种,中性情绪4127种

程度副词词典:
41个低级,37个中级,42个高级,99个极级

否定词词典:

表情符号词典构建:
搜集了网络上常用表情符号,也汇总了搜狗输入法中的表情符号。

网络用语词典构建:
搜狗细胞词汇表的网络用语:

微博评论文本特征:
内容简短,情感倾向明确:

评价对象多:

多样化。
****微博特征项抽取算法:****参考平滑算法,结合情感词典,获取数据,预处理,去噪,使用特征算法提取数据集关键词,随之与情感词典相匹配,直至匹配完整个数据集。
****情感词抽取:****上下滑动法
2 设计概要
本系统基于python技术,使用UML建模,采用django框架组合进行设计,Mysql数据库存储数据。
本系统的功能主要包括本系统的功能主要包括:
- 用户注册、登录、
- 信息维护、
- 会员搜索、
- 个性化推荐以及管理员进行信息管理等。
- 数据爬虫爬取
- 情感分析
- 可视化分析
3 系统关键技术
使用python,django,mysql进行开发
4 开发工具
开发工具主要有:Pycharm、Python3.8、Django3、mysql5.7、Navicat等。
5 代码展示
import os
import sys
from pathlib import Path
from django.core.wsgi import get_wsgi_application
# This allows easy placement of apps within the interior
# booksys directory.
ROOT_DIR = Path(__file__).resolve(strict=True).parent.parent
sys.path.append(str(ROOT_DIR / "booksys"))
# We defer to a DJANGO_SETTINGS_MODULE already in the environment. This breaks
# if running multiple sites in the same mod_wsgi process. To fix this, use
# mod_wsgi daemon mode with each site in its own daemon process, or use
# os.environ["DJANGO_SETTINGS_MODULE"] = "config.settings.production"
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "config.settings.production")
# This application object is used by any WSGI server configured to use this
# file. This includes Django's development server, if the WSGI_APPLICATION
# setting points here.
application = get_wsgi_application()
# Apply WSGI middleware here.
# from helloworld.wsgi import HelloWorldApplication
# application = HelloWorldApplication(application)
6 系统功能描述
项目功能演示

















 1389
1389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









