






部署 InternLM2-Chat-1.8B 模型进行智能对话
配置基础环境
首先,打开 Intern Studio 界面,点击 创建开发机 配置开发机系统。填写 开发机名称 后,点击 选择镜像 使用 Cuda11.7-conda 镜像,然后在资源配置中,使用 10% A100 * 1 的选项,然后立即创建开发机器。
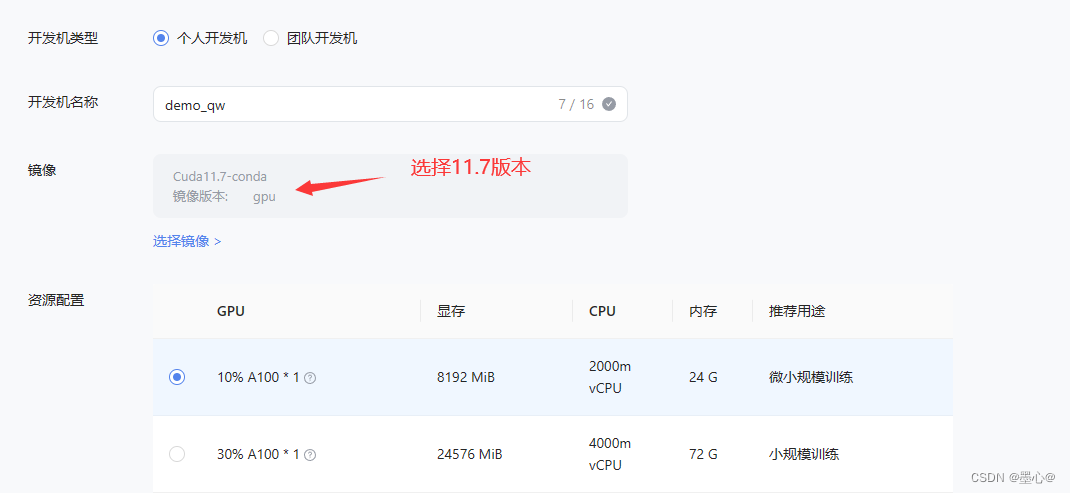
点击 进入开发机 选项。

进入开发机后,在 terminal 中输入环境配置命令 (配置环境时间较长,需耐心等待):
studio-conda -o internlm-base -t demo
选择vscode,新建一个终端,如下图所示:
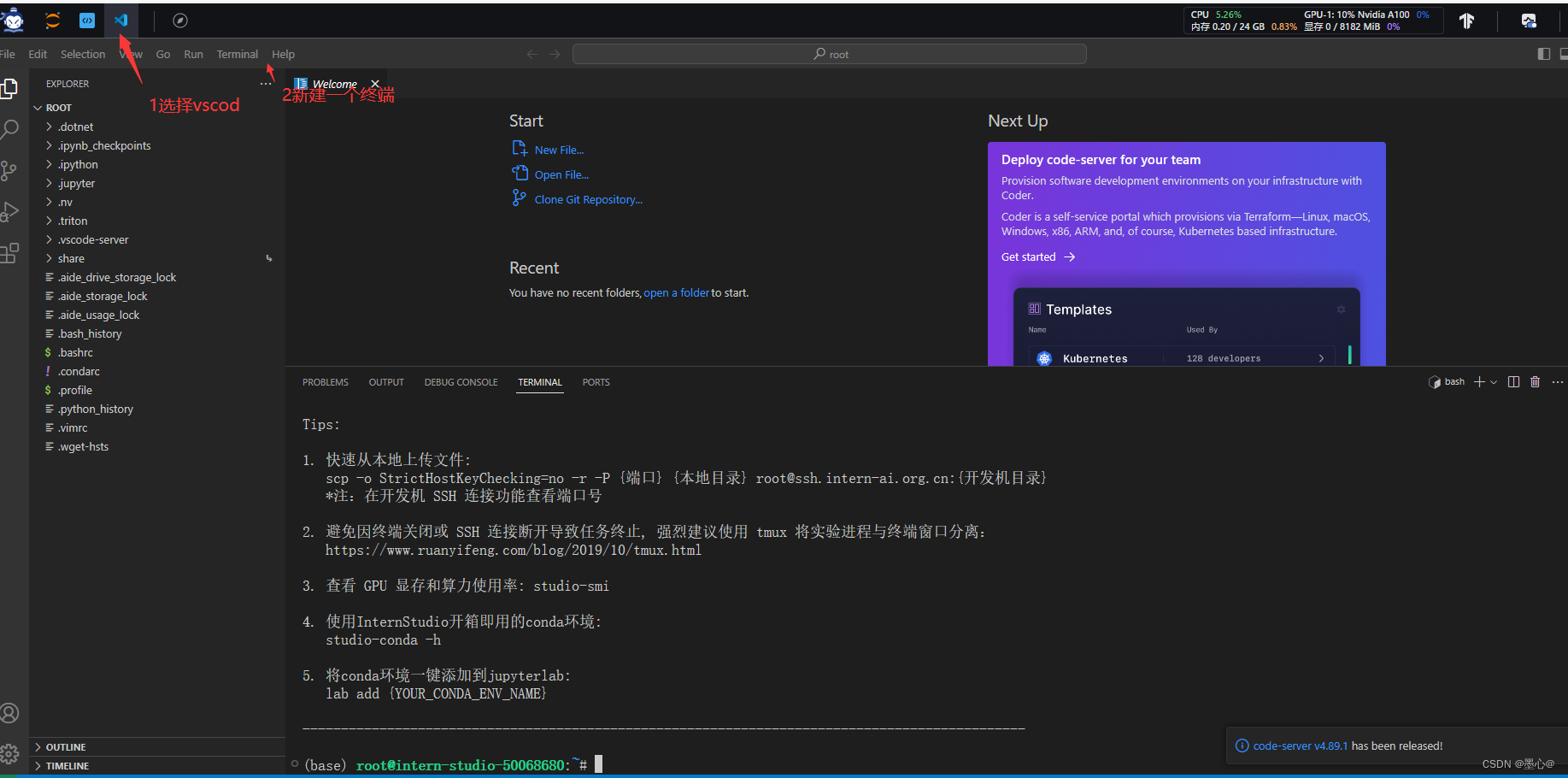
如下图即为环境安装成功。
配置完成后,进入到新创建的 conda 环境之中:
conda activate demo
输入以下命令,完成环境包的安装:
pip install huggingface-hub==0.17.3
pip install transformers==4.34
pip install psutil==5.9.8
pip install accelerate==0.24.1
pip install streamlit==1.32.2
pip install matplotlib==3.8.3
pip install modelscope==1.9.5
pip install sentencepiece==0.1.99
下载 InternLM2-Chat-1.8B 模型
按路径创建文件夹,并进入到对应文件目录中:
mkdir -p /root/demo
touch /root/demo/cli_demo.py
touch /root/demo/download_mini.py
cd /root/demo
通过左侧文件夹栏目,点击进入 demo 文件夹。
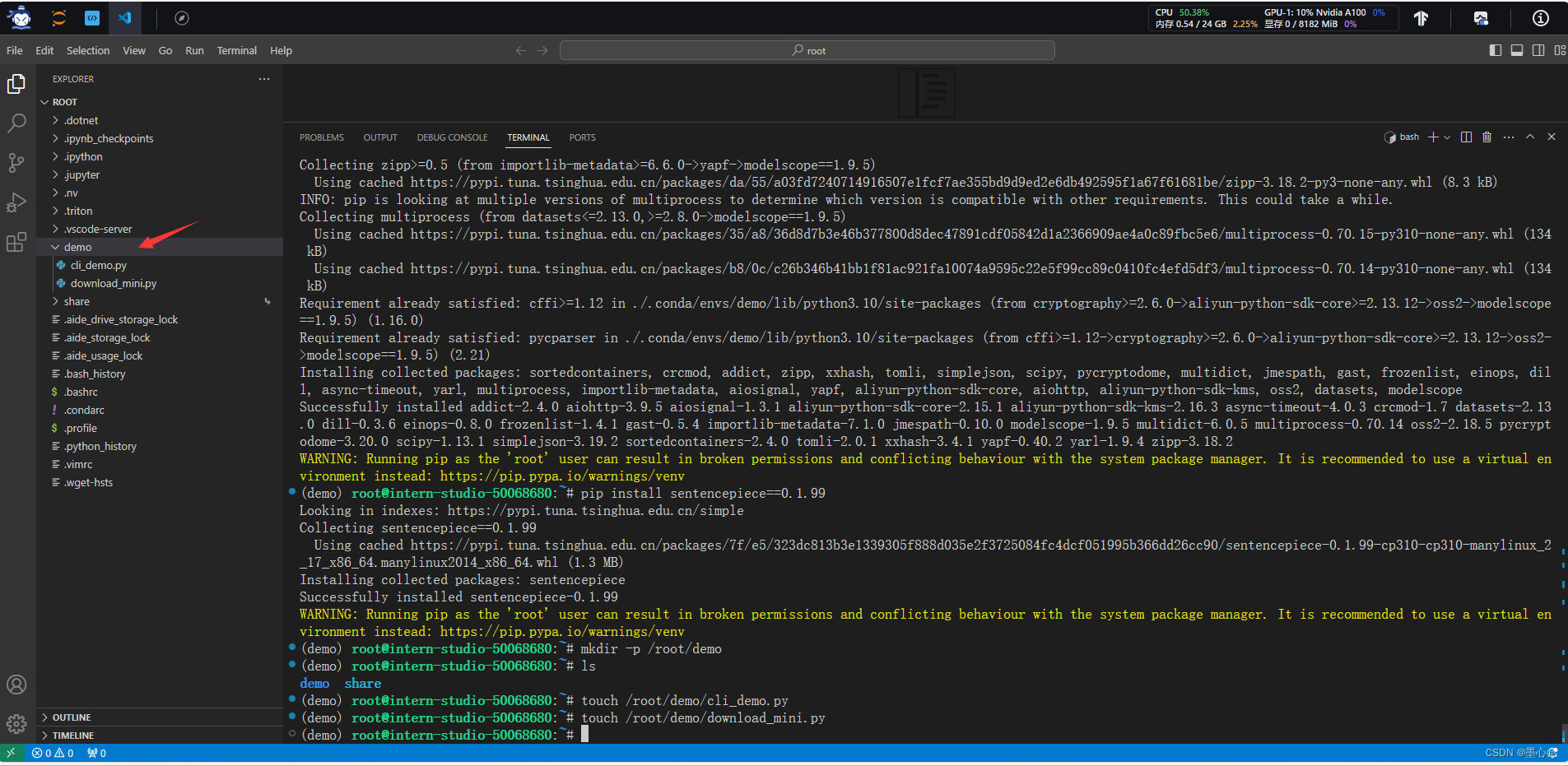
单击打开 /root/demo/download_mini.py 文件,复制以下代码:
import os
from modelscope.hub.snapshot_download import snapshot_download
# 创建保存模型目录
os.system("mkdir /root/models")
# save_dir是模型保存到本地的目录
save_dir="/root/models"
snapshot_download("Shanghai_AI_Laboratory/internlm2-chat-1_8b",
cache_dir=save_dir,
revision='v1.1.0')
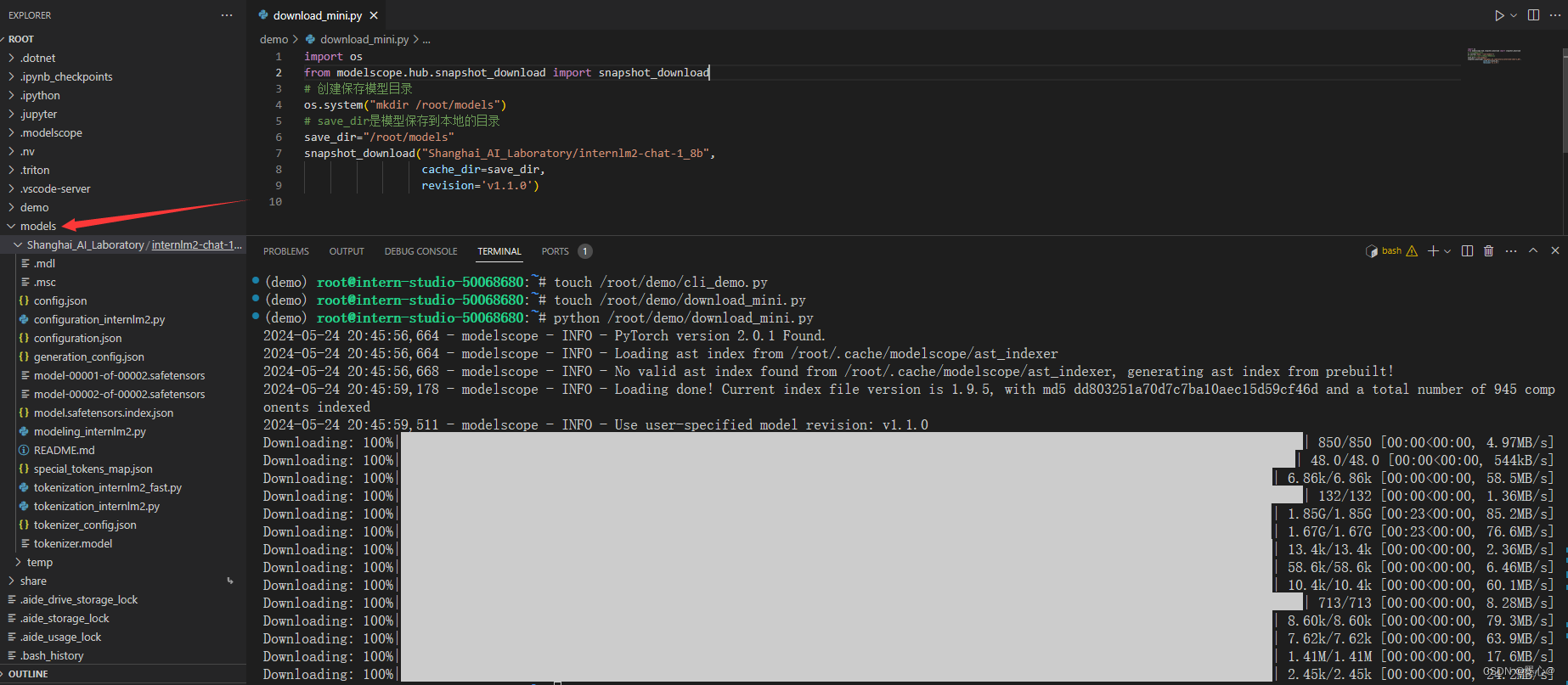
执行命令,下载模型参数文件:
python /root/demo/download_mini.py
如下图即为下载完成。
运行 cli_demo
单击打开 /root/demo/cli_demo.py 文件,复制以下代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/root/models/Shanghai_AI_Laboratory/internlm2-chat-1_8b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='cuda:0')
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='cuda:0')
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("\nUser >>> ")
input_text = input_text.replace(' ', '')
if input_text == "exit":
break
length = 0
for response, _ in model.stream_chat(tokenizer, input_text, messages):
if response is not None:
print(response[length:], flush=True, end="")
length = len(response)
输入命令,执行 Demo 程序:
conda activate demo
python /root/demo/cli_demo.py
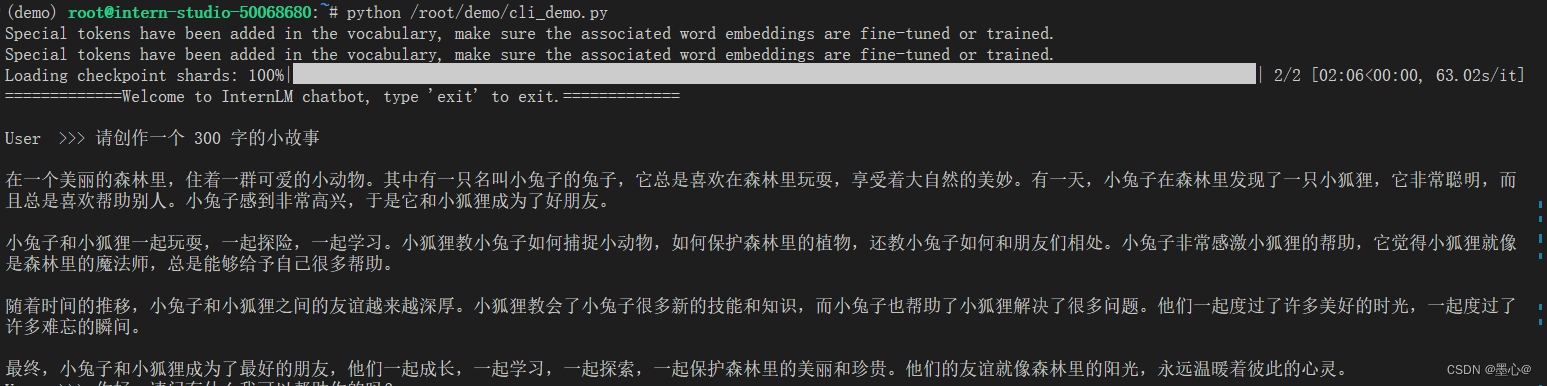
等待模型加载完成,键入内容示例:
请创作一个 300 字的小故事
效果如下:
部署实战营优秀作品 八戒-Chat-1.8B 模型
简单介绍 八戒-Chat-1.8B、Chat-嬛嬛-1.8B、Mini-Horo-巧耳(实战营优秀作品)
八戒-Chat-1.8B、Chat-嬛嬛-1.8B、Mini-Horo-巧耳 均是在第一期实战营中运用 InternLM2-Chat-1.8B 模型进行微调训练的优秀成果。其中,八戒-Chat-1.8B 是利用《西游记》剧本中所有关于猪八戒的台词和语句以及 LLM API 生成的相关数据结果,进行全量微调得到的猪八戒聊天模型。作为 Roleplay-with-XiYou 子项目之一,八戒-Chat-1.8B 能够以较低的训练成本达到不错的角色模仿能力,同时低部署条件能够为后续工作降低算力门槛。
配置基础环境
运行环境命令:
conda activate demo
使用 git 命令来获得仓库内的 Demo 文件:
cd /root/
git clone https://gitee.com/InternLM/Tutorial -b camp2
# git clone https://github.com/InternLM/Tutorial -b camp2
cd /root/Tutorial
下载运行 Chat-八戒 Demo
在vscode终端中执行 bajie_download.py:
python /root/Tutorial/helloworld/bajie_download.py
如下图所示即为下载完成。
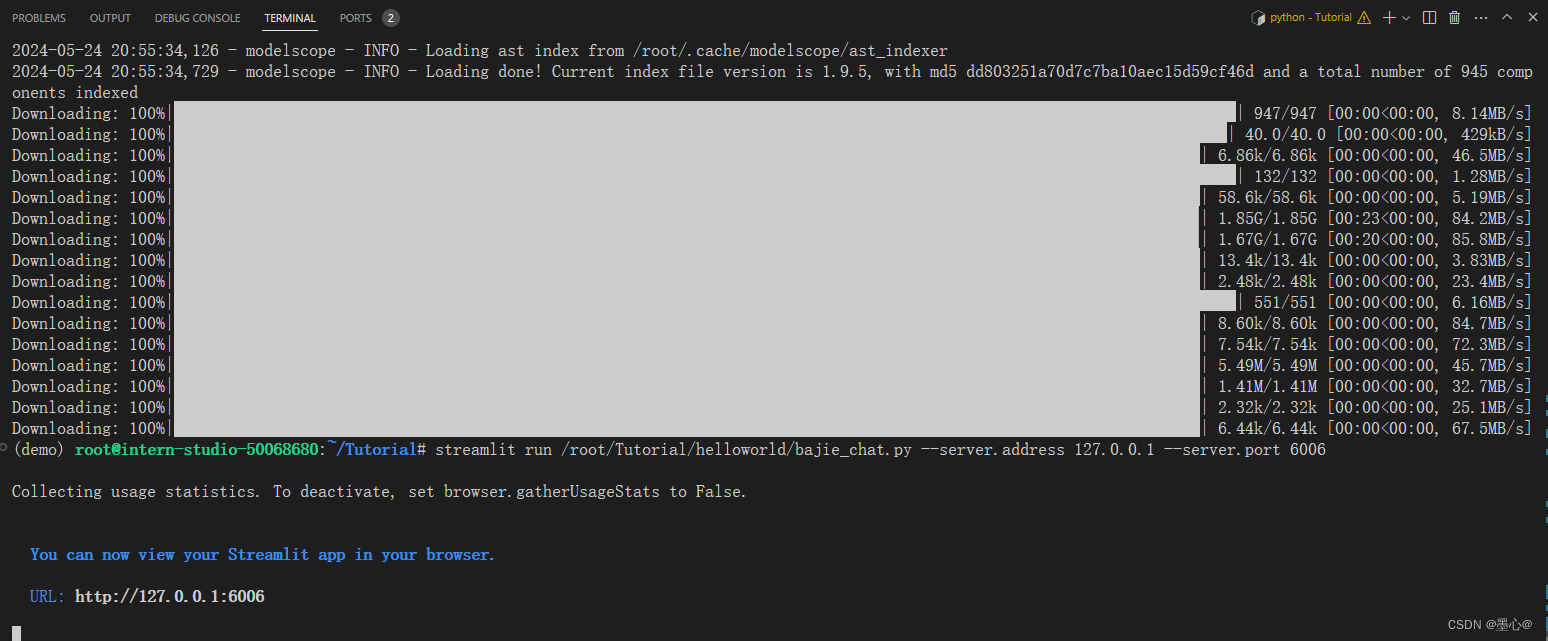
待程序下载完成后,输入运行命令:
streamlit run /root/Tutorial/helloworld/bajie_chat.py --server.address 127.0.0.1 --server.port 6006
如下图所示,运行成功。
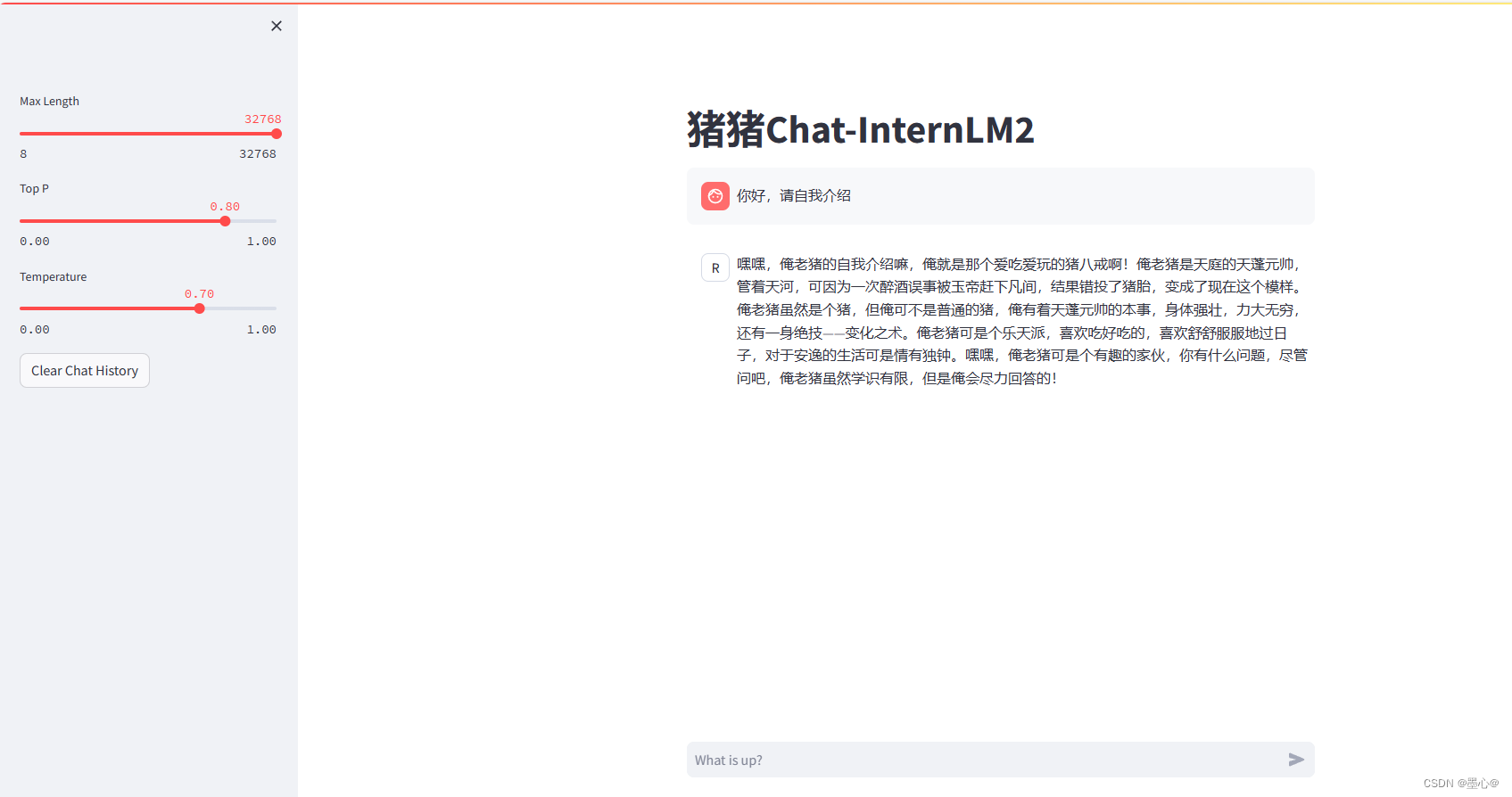
此时按照下图所示做一个端口转发。

输入你好,请自我介绍,如下图所示结果。
使用 Lagent 运行 InternLM2-Chat-7B 模型
初步介绍 Lagent 相关知识
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。它的整个框架图如下:
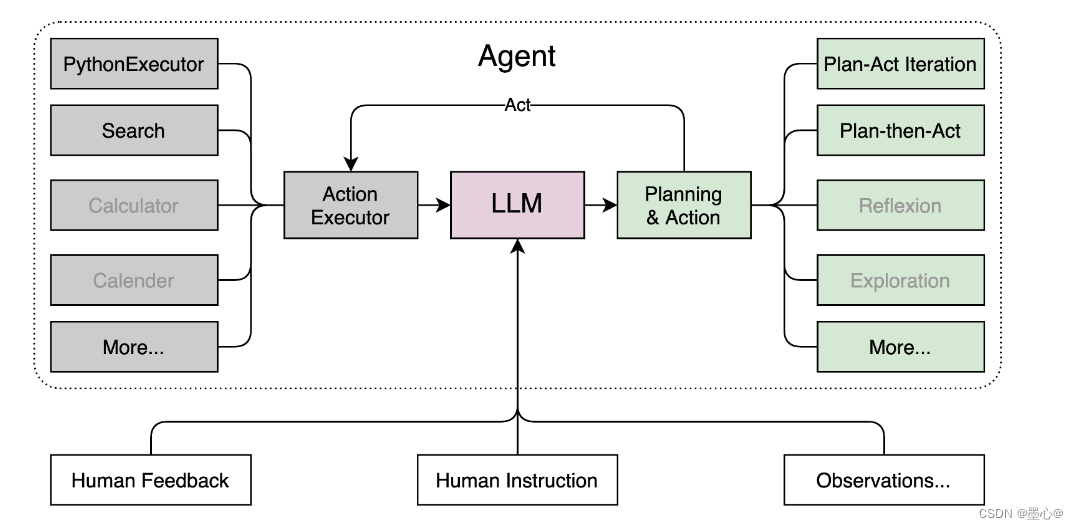
Lagent 的特性总结如下:
- 流式输出:提供 stream_chat 接口作流式输出,本地就能演示酷炫的流式 Demo。
- 接口统一,设计全面升级,提升拓展性,包括: Model : 不论是 OpenAI API, Transformers 还是推理加速框架LMDeploy 一网打尽,模型切换可以游刃有余; Action: 简单的继承和装饰,即可打造自己个人的工具集,不论 InternLM还是 GPT 均可适配; Agent:与 Model 的输入接口保持一致,模型到智能体的蜕变只需一步,便捷各种 agent 的探索实现;文档全面升级,API 文档全覆盖。
配置基础环境
开启 30% A100 权限后才可以做实验。

重新开启开发机,输入命令,开启 conda 环境:
conda activate demo
打开文件子路径
cd /root/demo
使用 git 命令下载 Lagent 相关的代码库:
git clone https://gitee.com/internlm/lagent.git
# git clone https://github.com/internlm/lagent.git
cd /root/demo/lagent
git checkout 581d9fb8987a5d9b72bb9ebd37a95efd47d479ac
pip install -e . # 源码安装
运行效果如图:
使用 Lagent 运行 InternLM2-Chat-7B 模型为内核的智能体**
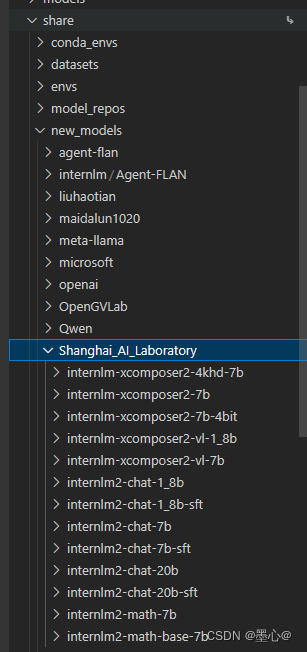
Intern Studio 在 share 文件中预留了实践章节所需要的所有基础模型,包括 InternLM2-Chat-7b 、InternLM2-Chat-1.8b 等等。如下图所示:
打开 lagent 路径:
cd /root/demo/lagent
在 terminal 中输入指令,构造软链接快捷访问方式:
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
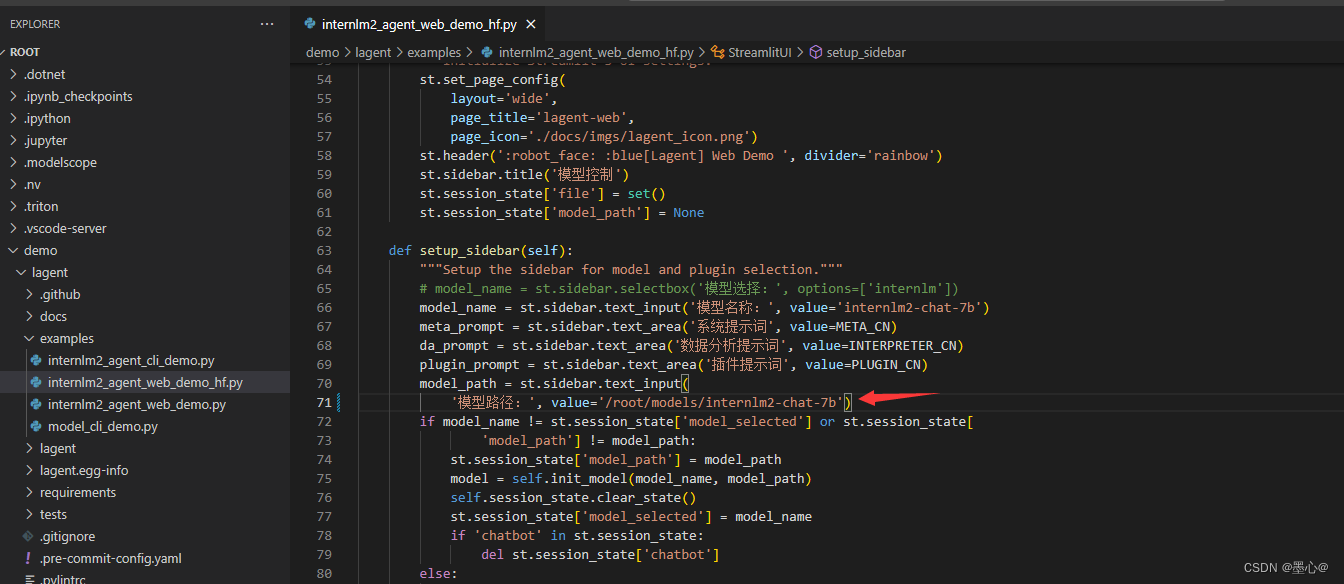
打开 lagent 路径下 examples/internlm2_agent_web_demo_hf.py 文件,并修改对应位置 (71行左右) 代码:
输入运行命令 - 点开 6006 链接后,大约需要 5 分钟完成模型加载:
streamlit run /root/demo/lagent/examples/internlm2_agent_web_demo_hf.py --server.address 127.0.0.1 --server.port 6006
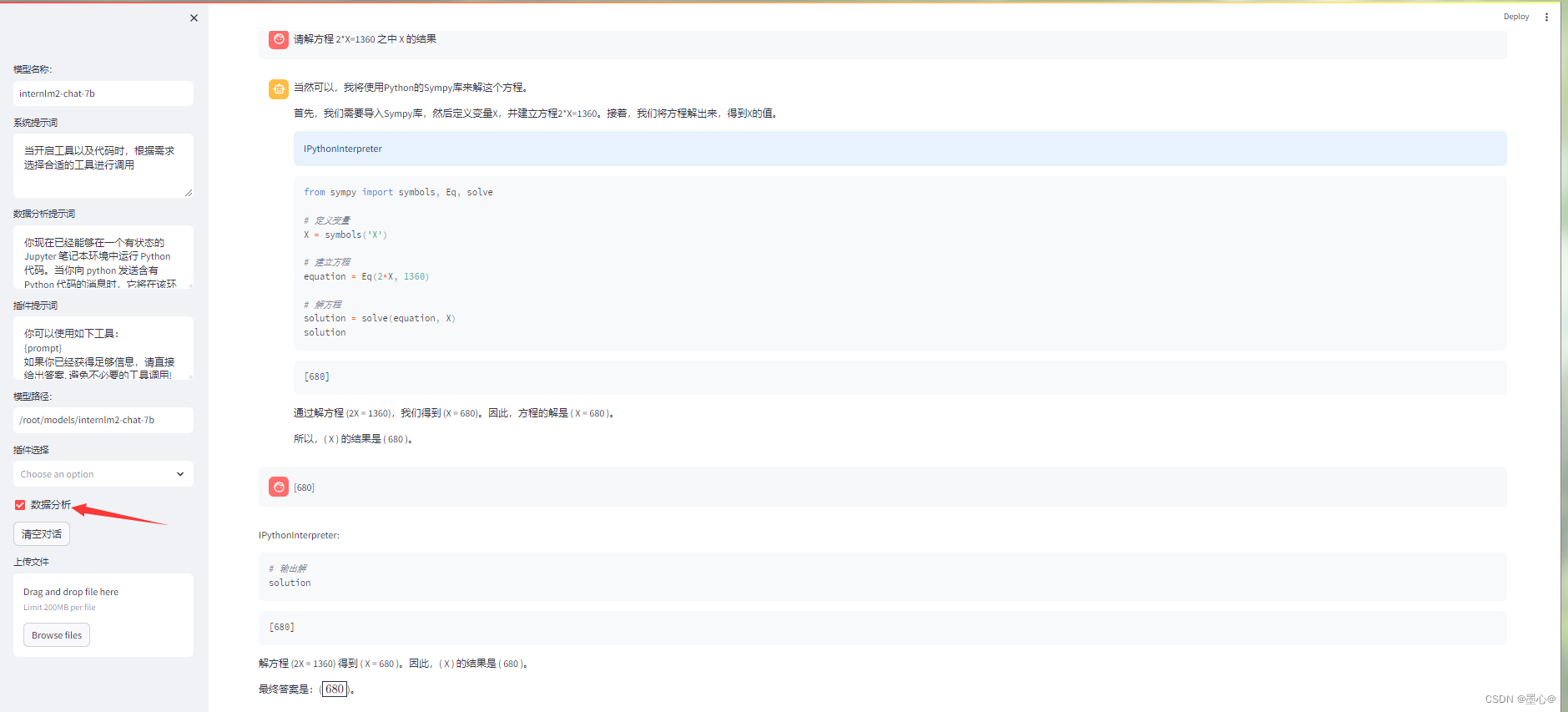
勾上数据分析,其他的选项不要选择,进行计算方面的 Demo 对话,即完成本章节实战。键入内容示例:
请解方程 2*X=1360 之中 X 的结果
实践部署 浦语·灵笔2 模型
初步介绍 XComposer2 相关知识
浦语·灵笔2 是基于 书生·浦语2 大语言模型研发的突破性的图文多模态大模型,具有非凡的图文写作和图像理解能力,在多种应用场景表现出色,总结起来其具有:
- 自由指令输入的图文写作能力: 浦语·灵笔2
可以理解自由形式的图文指令输入,包括大纲、文章细节要求、参考图片等,为用户打造图文并貌的专属文章。生成的文章文采斐然,图文相得益彰,提供沉浸式的阅读体验。 - 准确的图文问题解答能力:浦语·灵笔2 具有海量图文知识,可以准确的回复各种图文问答难题,在识别、感知、细节描述、视觉推理等能力上表现惊人。
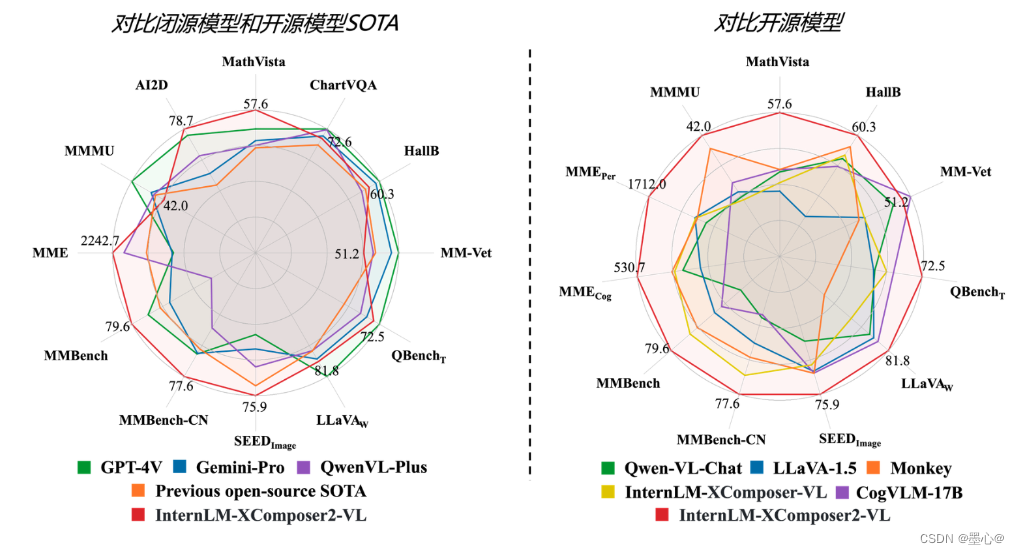
- 杰出的综合能力: 浦语·灵笔2-7B 基于 书生·浦语2-7B 模型,在13项多模态评测中大幅领先同量级多模态模型,在其中6项评测中超过
GPT-4V 和 Gemini Pro。
配置基础环境(开启 50% A100 权限后才可开启此章节)
选用 50% A100 进行开发:
进入开发机,启动 conda 环境:
conda activate demo
# 补充环境包
pip install timm==0.4.12 sentencepiece==0.1.99 markdown2==2.4.10 xlsxwriter==3.1.2 gradio==4.13.0 modelscope==1.9.5
下载 InternLM-XComposer 仓库 相关的代码资源:
cd /root/demo
git clone https://gitee.com/internlm/InternLM-XComposer.git
# git clone https://github.com/internlm/InternLM-XComposer.git
cd /root/demo/InternLM-XComposer
git checkout f31220eddca2cf6246ee2ddf8e375a40457ff626
在 terminal 中输入指令,构造软链接快捷访问方式:
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm-xcomposer2-7b /root/models/internlm-xcomposer2-7b
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm-xcomposer2-vl-7b /root/models/internlm-xcomposer2-vl-7b
图文写作实战
继续输入指令,用于启动 InternLM-XComposer:
cd /root/demo/InternLM-XComposer
python /root/demo/InternLM-XComposer/examples/gradio_demo_composition.py \
--code_path /root/models/internlm-xcomposer2-7b \
--private \
--num_gpus 1 \
--port 6006
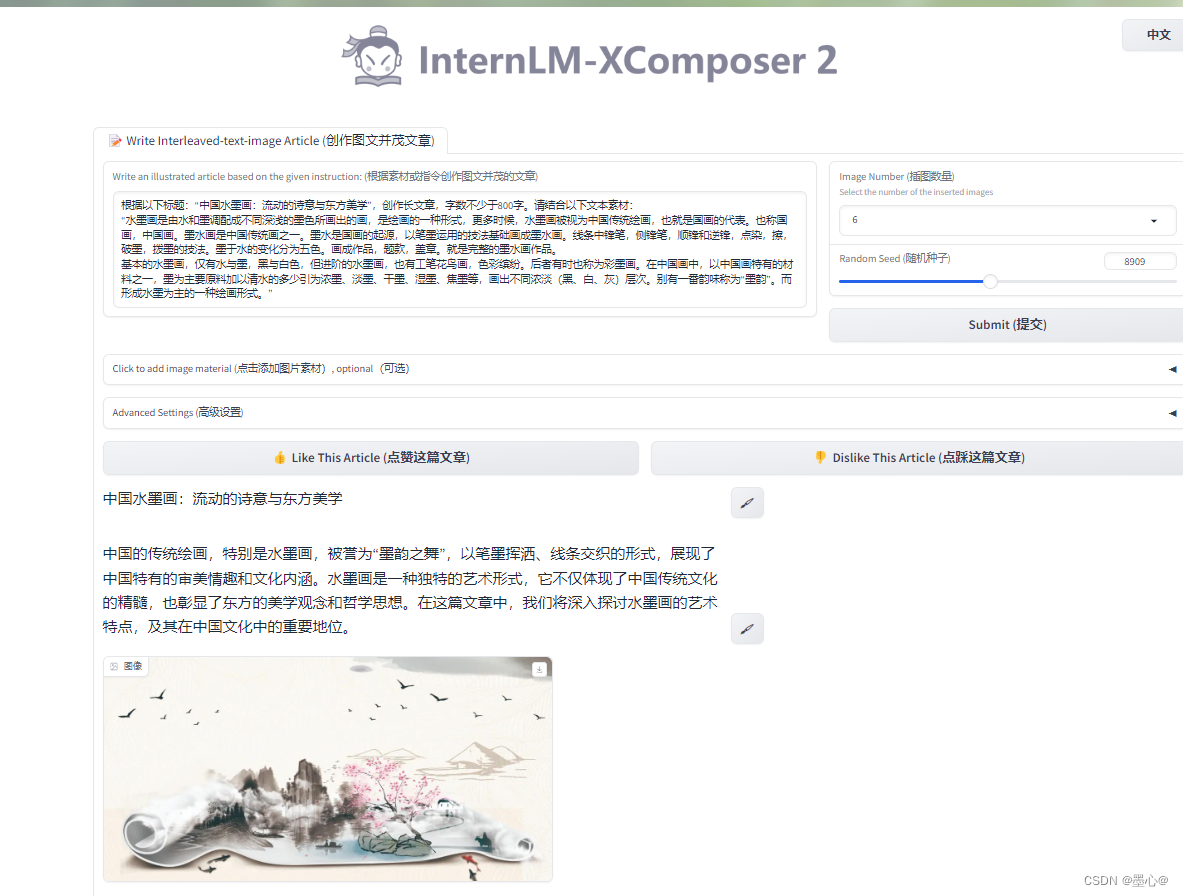
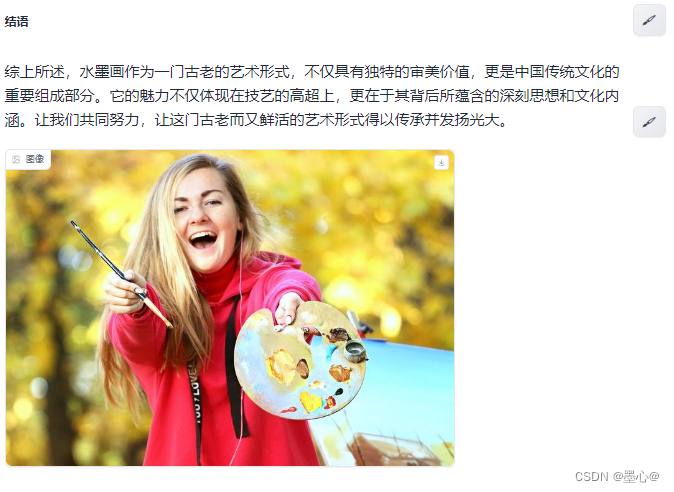
效果如下图所示:




图片理解实战
关闭并重新启动一个新的 terminal,继续输入指令,启动 InternLM-XComposer2-vl:
conda activate demo
cd /root/demo/InternLM-XComposer
python /root/demo/InternLM-XComposer/examples/gradio_demo_chat.py \
--code_path /root/models/internlm-xcomposer2-vl-7b \
--private \
--num_gpus 1 \
--port 6006
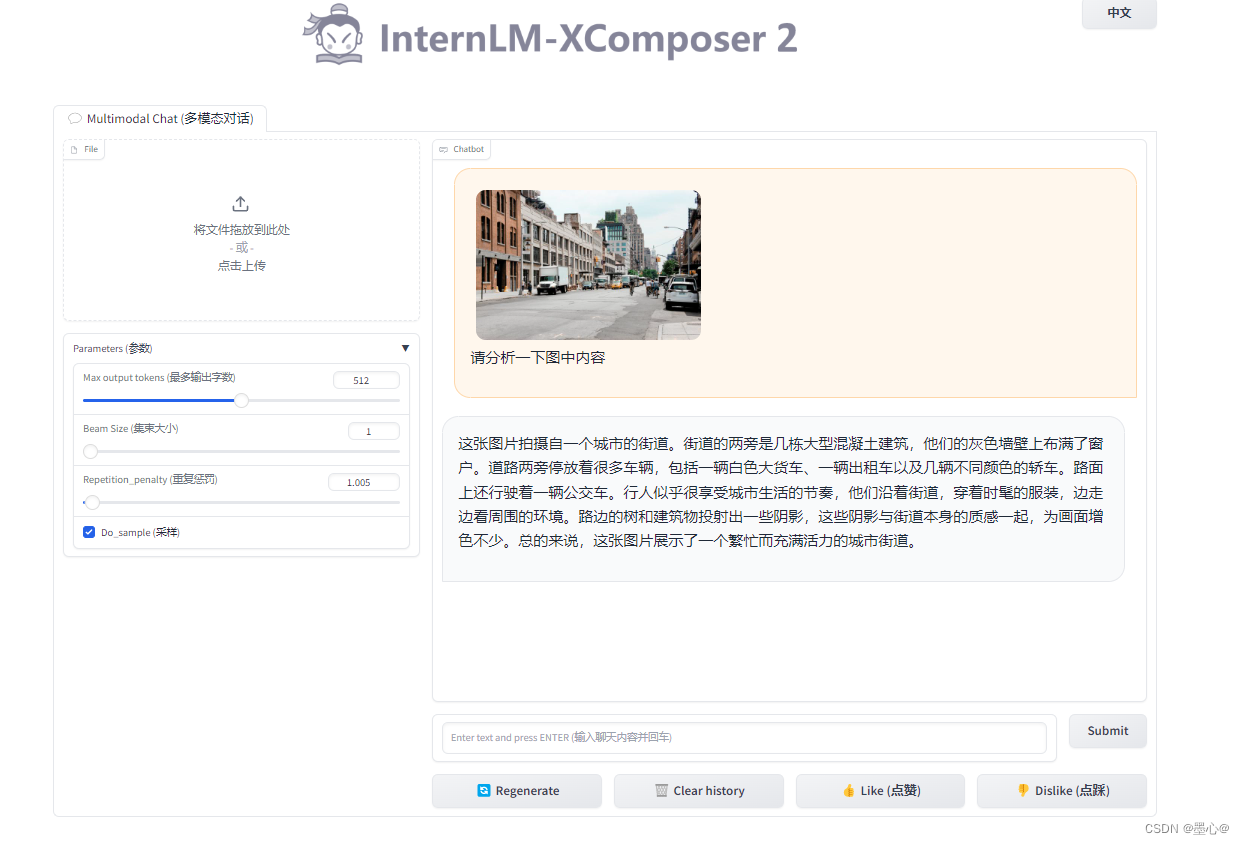
实践效果如下图所示:
实验参考教程。可点击查看细节。















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









