







简介
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中, GLM-4-9B 表现出超越 Llama-3-8B 的卓越性能。除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。
环境配置以及模型的复现
查看服务配置信息
输入命令 studio-smi 具体效果图如下图:
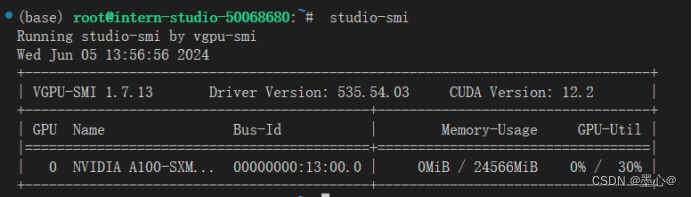
从图中可以看出CUDA版本为12.2,那么需要安装的pytorch的CUDA版本不能超过12.2。
其次在服务器中 anaconda 的 base 环境中创建一个空的虚拟环境,使用的命令如下:
conda create -n GLM4 python=3.10
激活环境使用命令
conda activate GLM4
本次实验使用的CUDA是11.8版本。安装命令如下:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
下载好进行验证 torch 是否安装好,效果图如下:

环境安装完毕,从 github 下载项目,项目地址。
在github上的项目目录图如下:
使用命令:
git clone https://github.com/THUDM/GLM-4.git
下载好的目录如下:
以下内容为基础的 GLM-4-9B的使用和开发代码
- base: 在这里包含了
使用 transformers 和 VLLM 后端的交互代码
OpenAI API 后端交互代码
Batch 推理代码 - composite_demo:
在这里包含了GLM-4-9B 以及 GLM-4V-9B 开源模型的完整功能演示代码,包含了 All Tools 能力、长文档解读和多模态能力的展示。
fintune_demo: 在这里包含了
PEFT (LORA, P-Tuning) 微调代码
SFT 微调代码
本次复现base里边的transformers 代码部分
最低硬件要求:运行官方提供的最基础代码 (transformers 后端) ,需要:Python >= 3.10,内存不少于 32 GB。运行官方提供的本文件夹的所有代码,还需要:Linux 操作系统 (Debian 系列最佳)大于 8GB 显存的,支持 CUDA 或者 ROCM 并且支持 BF16 推理的 GPU 设备 (A100以上GPU,V100,20以及更老的GPU架构不受支持)。此时切换目录到basic_demo下边,执行命令:
pip install -r requirements.txt
出现下图结果:
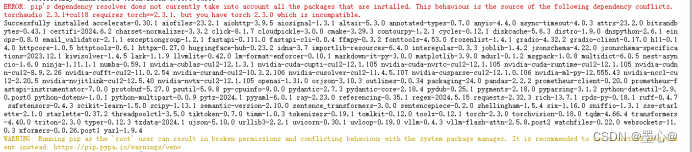
此时出现包冲突问题,再次执行下边命令:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
即可将冲突问题解决。使用ModelScope进行模型下载,首先安装modelscope包,使用以下命令:
pip install modelscope
然后创建down_load.py,将下面代码贴入文件中。
import os
from modelscope.hub.snapshot_download import snapshot_download
# 创建保存模型目录
# os.system("mkdir /root/models")
# save_dir是模型保存到本地的目录
save_dir="/root/models"
# modelscope上边的名字
path="ZhipuAI/glm-4-9b"
snapshot_download(path, cache_dir=save_dir)
运行python down_load.py ,即可下载。下载好文件目录如下
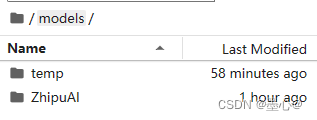
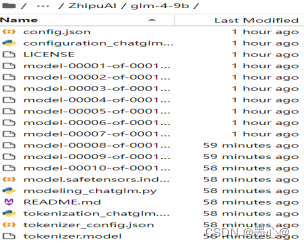
- 使用 transformers 后端代码
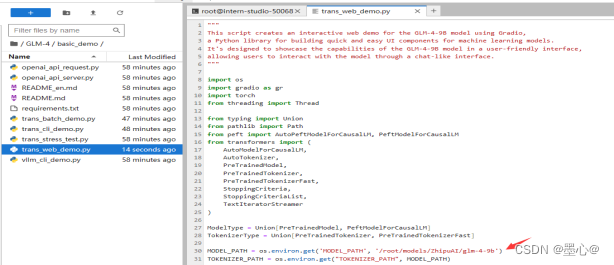
使用 Gradio 网页端与 glm-4-9b 模型进行对话:此时还需要修改trans_web_demo.py 文件,修改里边模 型加载的路径,将加载的模型指向 model 文件夹,使用模型存储的绝对路径。修改如下图所示:
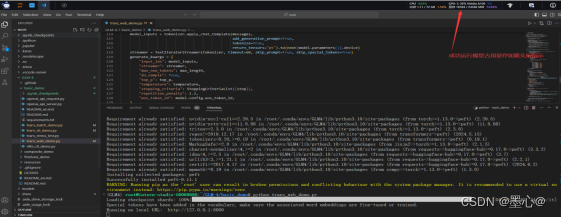
运行 python trans_web_demo.py ,会出现以下错误:

根据提示安装peft包,命令为pip install peft。等待安装完成后,继续执行 python trans_web_demo.py,运行模型所需要占用达到显存所示:
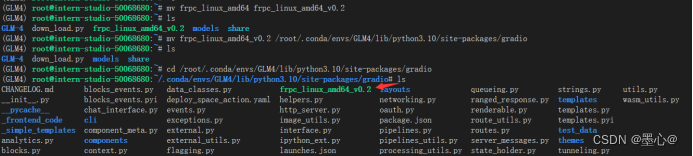
此时访问运行的程序会出现这个问题,如下图随时。

根据终端输出信息,进行下载文件,移动到相应位置即可。

再次运行的效果图如下所示:

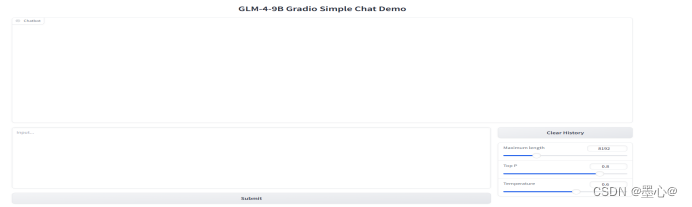
- 使用 命令行 与 glm-4-9b 模型进行对话
此时还需要修改trans_cli_demo.py 文件,修改里边模 型加载的路径,将加载的模型指向 model 文件夹,使用模型存储的绝对路径。修改如下图所示:
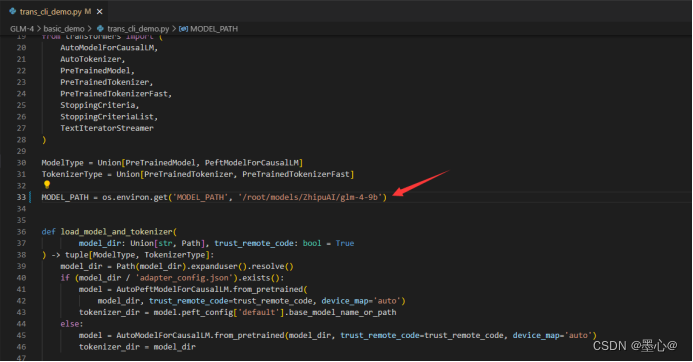
运行python trans_cli_demo.py即可。

- 使用 Batch 推理
此时还需要修改trans_batch_demo.py 文件,修改里边模 型加载的路径,将加载的模型指向 model 文件夹,使用模型存储的绝对路径。修改如下图所示:
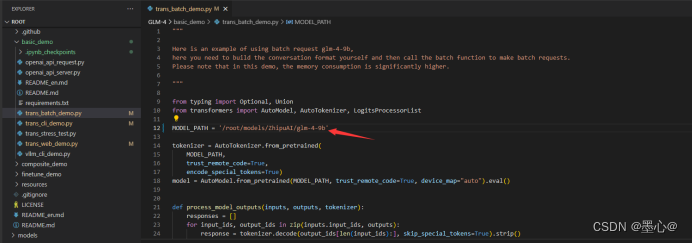
运行python trans_batch_demo.py即可。
本次复现实验参考GLM4项目,具体细节可访问查看。















 1581
1581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









