









Scrapy的使用(1) – 爬取b站新番排行榜
scrapy框架笔记(1),参考官方文档与部分教程,完成一个简单的爬虫程序,爬取了b站的2021年1月新番数据
1. 创建项目
在需要存储的代码目录下输入
scrapy startproject animeRankSpider
该命令生成如下文件夹结构
|--animeRankSpider
|--scrapy.cfg
|--animeRankSpider
|--__init__.py
|--items.py
|--middlewares.py
|--pipelines.py
|--settings.py
|--spiders.py
|--__init__.py
这些文件分别为:
scrapy.cfg为scrapy的配置文件items.py为爬取内容的每个小单元设计,称之为itemmiddlewares.py为爬虫中间件pipelines.py为信息处理过程的设计setting.py为爬虫的一些设置
2. 设计爬虫单元(scrapy中称为item)
观察b站新番相关数据,我准备爬取的内容为新番标题、弹幕量、播放量、追番人数、排名。
打开items.py,输入如下内容
import scrapy
class AnimerankspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
rank = scrapy.Field()
view = scrapy.Field()
bullet = scrapy.Field()
like = scrapy.Field()
pass
3. 网页分析
爬取的网站为https://www.bilibili.com/v/popular/rank/bangumi ,可以在终端中输入下面的指令帮助分析
scrapy shell "https://www.bilibili.com/v/popular/rank/bangumi"
例如,在输入时
response.xpath('//*[@id="app"]/div[2]/div[2]/ul/li[1]/div[2]/div[2]/a/text()')
会有输出
[<Selector xpath='//*[@id="app"]/div[2]/div[2]/ul/li[1]/div[2]/div[2]/a/text()' data='Re:从零开始的异世界生活 第二季 后半'>]
也就是说可以根据页面中元素的xpath路径可以找到网页中元素的位置,这正是爬虫所需要的
这里安利一款chrome插件Xpath Helper ,可以帮助分析Xpath
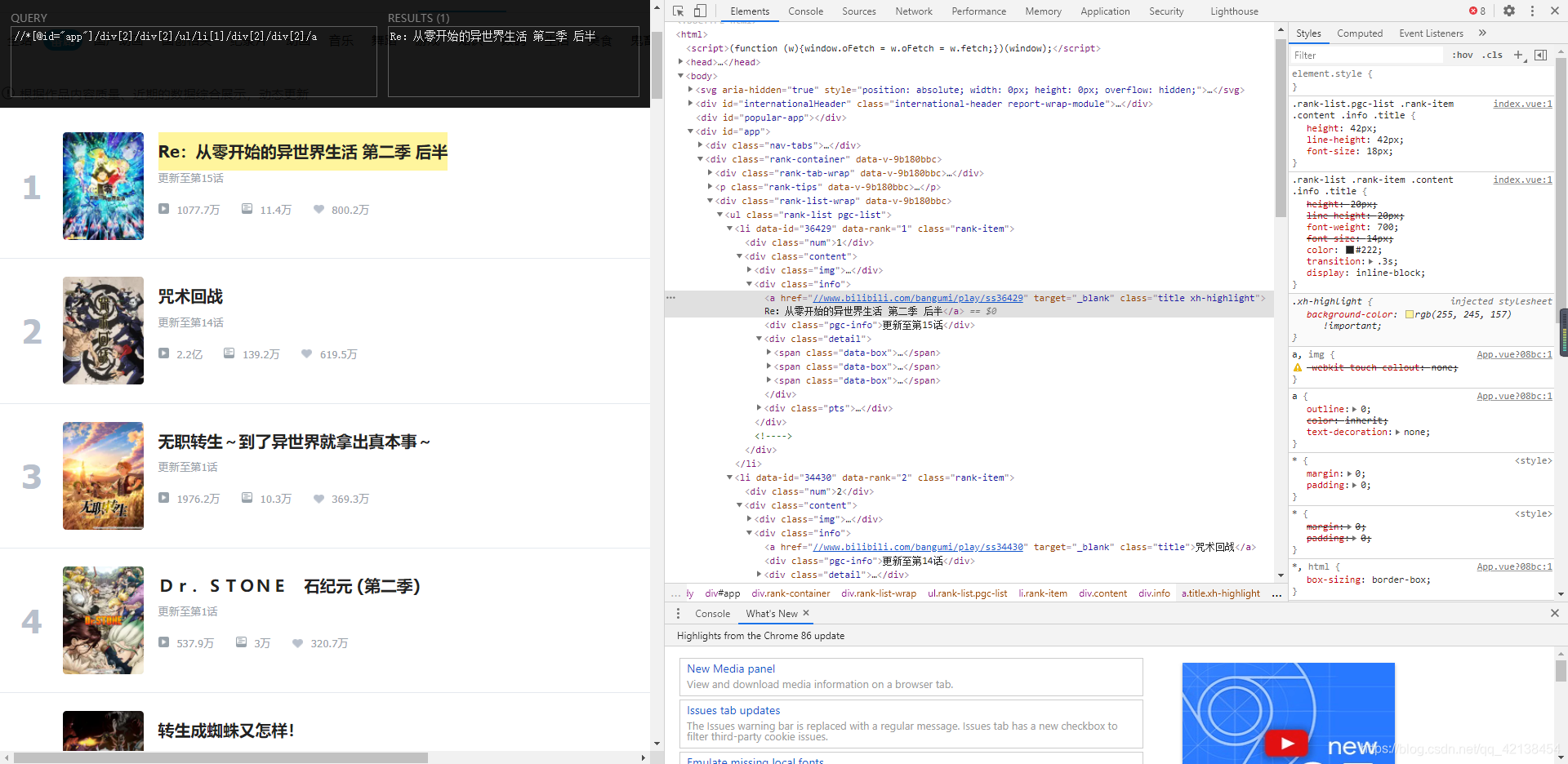
观察两部新番标题的Xpath,分别为
//*[@id="app"]/div[2]/div[2]/ul/li[1]/div[2]/div[2]/a
//*[@id="app"]/div[2]/div[2]/ul/li[2]/div[2]/div[2]/a
可以发现,差别仅在于标签li后面的系数。经过进一步验证,发现网站的其他内容也有类似的格式
因此分析结果如下,index代表不同新番的系数,从1开始取值
- 标题格式
//*[@id="app"]/div[2]/div[2]/ul/li[index]/div[2]/div[2]/a - 播放量
//*[@id="app"]/div[2]/div[2]/ul/li[index]/div[2]/div[2]/div[2]/span[1] - 弹幕量
//*[@id="app"]/div[2]/div[2]/ul/li[index]/div[2]/div[2]/div[2]/span[2] - 追番人数
//*[@id="app"]/div[2]/div[2]/ul/li[index]/div[2]/div[2]/div[2]/span[3] - 排序
//*[@id="app"]/div[2]/div[2]/ul/li[index]/div[1]
4.爬虫编写
输入命令,引号中内容为爬虫网站的主域名
scrapy genspider animeRankSpider "bilibili.com"
在animeRankSpider/spiders文件夹下创建了一个py结尾的新爬虫文件,输入如下代码
import scrapy
from animeRankSpider.items import AnimerankspiderItem
class BilibiliSpider(scrapy.Spider):
name = 'animeRankSpider'
allowed_domains = ['bilibili.com']
start_urls = ['https://www.bilibili.com/v/popular/rank/bangumi']
def parse(self, response):
# filename = 'rank.html'
# open(filename, 'wb').write(response.body)
items = []
rootPath = '//*[@id="app"]/div[2]/div[2]/ul'
for index in range(49):
item = AnimerankspiderItem()
namePath = rootPath + '/li[{}]/div[2]/div[2]/a/text()'.format(index)
viewPath = rootPath + '/li[{}]/div[2]/div[2]/div[2]/span[1]/text()'.format(index)
rankPath = rootPath + '/li[{}]/div[1]/text()'.format(index)
bulletPath = rootPath + '/li[{}]/div[2]/div[2]/div[2]/span[2]/text()'.format(index)
likePath = rootPath + '/li[{}]/div[2]/div[2]/div[2]/span[3]/text()'.format(index)
name = response.xpath(namePath).extract()
view = response.xpath(viewPath).extract()
rank = response.xpath(rankPath).extract()
bullet = response.xpath(bulletPath).extract()
like = response.xpath(likePath).extract()
item['name'] = name
item['view'] = view
item['rank'] = rank
item['bullet'] = bullet
item['like'] = like
items.append(item)
return items
5. 运行爬虫
终端中输入命令
scrapy crawl animeRankSpider -o out.csv
等待片刻,生成的out.csv即为爬虫所得,可以用记事本或者excel打开
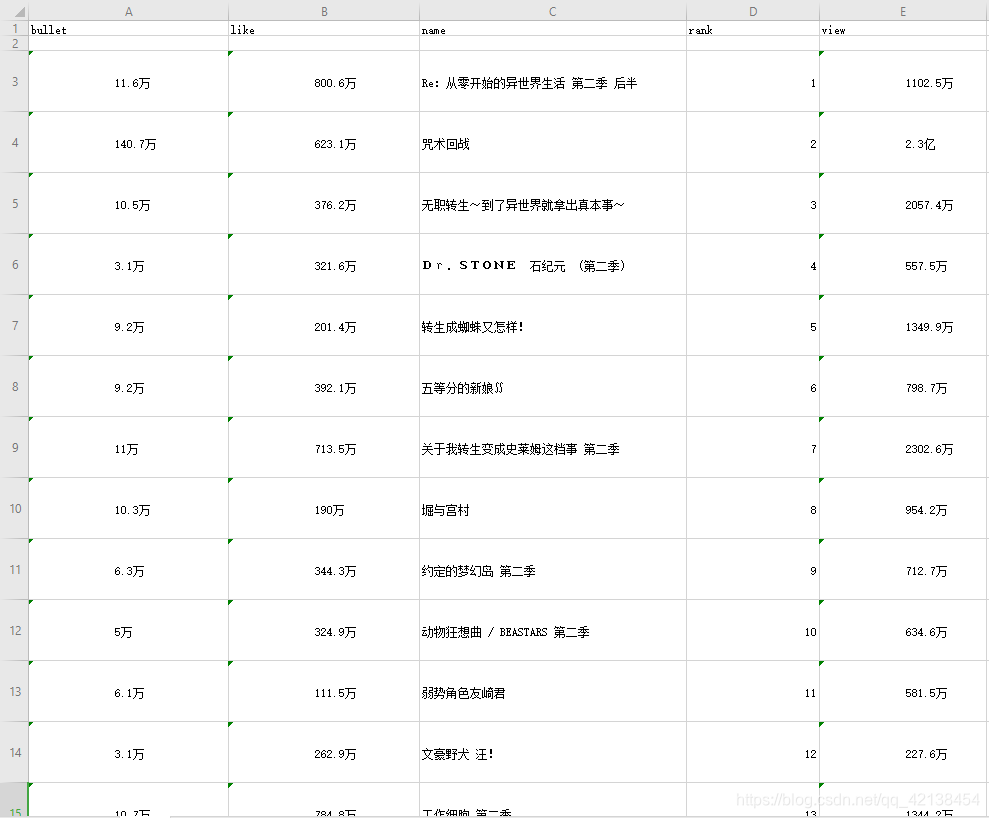
代码上传到了百度网盘,链接如下
链接:https://pan.baidu.com/s/1HzjZdmUQ-u7FeapgyAH8vA
提取码:lhvh















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









