






一.Kibana使用
1 Kibana
1.1Kibana 安装与配置
Kibana: 数据可视化平台工具
特点:
灵活的分析和可视化平台
实时总结流量和数据的图表
为不同的用户显示直观的界面
即时分享和嵌入的仪表盘
Kibana安装:
Kibana的安装非常简单,我们使用rpm方式安装,Kibana默认安装在/opt/kibana下面,配置文件在/opt/kibana/config/kibana.yml,配置完成后启动服务,访问web页面5601端口:http://192.168.1.56:5601/
[root@kibana ~]# yum -y install kibana
[root@kibana ~]# vim /opt/kibana/config/kibana.yml
2 server.port: 5601 //监听端口
5 server.host: "0.0.0.0" //监听地址,0.0.0.0 代表所有
15 elasticsearch.url: "http://es1:9200" //要先配置/etc/hosts文件
23 kibana.index: ".kibana" //库:存放用户信息
26 kibana.defaultAppId: "discover" //默认首页
53 elasticsearch.pingTimeout: 1500
57 elasticsearch.requestTimeout: 30000 //请求超时
64 elasticsearch.startupTimeout: 5000 //启动超时
[root@kibana ~]# systemctl enable kibana
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /usr/lib/systemd/system/kibana.service.
[root@kibana ~]# systemctl start kibana
[root@kibana ~]# netstat -tunlp | grep 5601
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:5601 0.0.0.0:*
1.2 Kibana页面
1.浏览器访问kibana,如图所示
[root@room9pc01 ~]$ firefox 192.168.1.56:5601

2.点击status,查看是否安装成功

3.用head插件访问会有.Kibana的索引信息:
[root@room9pc01 ~]$ firefox http://192.168.1.55:9200/_plugin/head

1.3 使用Kibana查看数据是否导入成功
1.数据导入后查看logs是否导入成功,如图:
[root@room9pc01 ~]$ firefox http://192.168.1.55:9200/_plugin/head

2.kibana导入数据
[root@room9pc01 ~]$ firefox http://192.168.1.56:5601

3.成功创建会有logstash-*:

4.导入成功后选择Discover:
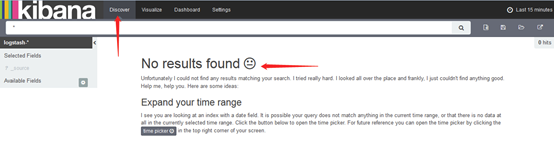
这里没有数据是因为导入日志的时间端不对,默认配置是最近15分钟,在右上角可以修改时间来显示
5.kibana修改时间

6.选择Absolute
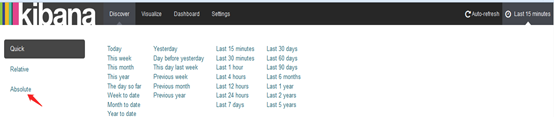
7选择时间:例如2015-5-15到2015-5-22:

8.查看结果:
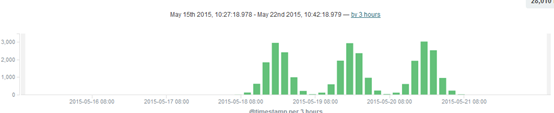
注:这里可以在图表中通过鼠标左键点击拖拽选择具体要显示的数据,可以将空白的过滤掉

9.除了柱状图,Kibana还支持多种展示方式

10.做一个饼图,选择Pie chart

11.选择from a new serach:

12,选择Spilt Slices

13.选择Trems,Memary

14 结果如图

15.保存后可以在Dashboard查看

二.Logstash配置扩展插件
1.Logstash是什么
是一个数据采集,加工处理以及传输的工具
特点:
所有类型的数据集中化处理
不同模式和格式数据的正常化
自定义日志格式的迅速扩展
为自定义数据源轻松添加插件
2.Logstash安装
2.1Logstash安装
Logstash安装依赖java环境,需要安装java-1.8.0-openjdk
Logstash没有配置文件,需要自己手动配置
Logstash安装在/opt/logstash目录下
# yum -y install logstash
2.2 Logstash工作结构:
{数据源}==>
input{ } ==>
filter{ } ==>
output{ } ==>
{ES}
2.3 Logstash类型及条件判断:
| 类型 | 实例 |
|---|---|
| 布尔值类型 | ssl_enable => true |
| 字节类型 | bytes => “1Mib” |
| 字符串类型 | name => “xkops” |
| 数值类型 | port => 22 |
| 数组 | match => [“datetime”,“UNIX”] |
| 哈希 | options => {k = “v”,k2 => “v”} |
| 编码解码 | codec => “json” |
| 路径 | file_path => “/tmp/filename” |
| 注释 | # |
Logstash条件判断:
| 条件 | 符号 |
|---|---|
| 等于 | == |
| 不等于 | != |
| 小于 | < |
| 大于 | > |
| 小于等于 | <= |
| 大于等于 | >= |
| 匹配正则 | =~ |
| 不匹配正则 | !~ |
| 包含 | in |
| 不包含 | not in |
| 与 | and |
| 或 | or |
| 非与 | nand |
| 非或 | xor |
| 复合表达式 | () |
| 取反符合 | !() |
2.4 Logstash的第一个配置文件
/etc/logstash/logstash.conf
[root@logstash ~]# cd /etc/logstash/
[root@logstash logstash]# touch logstash.conf
[root@logstash logstash]# vim logstash.conf
input{ //标准输入
stdin{}
}
filter{ //过滤器为空
}
output{ //标准输出
stdout{}
}
//启动并验证
[root@logstash logstash]# /opt/logstash/bin/logstash -f /etc/logstash/logstash.conf
Settings: Default pipeline workers: 2
Pipeline main started
Hello World
2018-10-16T03:03:10.808Z Hello World
2.5 插件
1.Logstash插件,上述配置文件使用了logstash-input-stdin和logstash-output-stdout两个插件,Logstash还有filter和codec类插件,查看插件的方式是:
[root@logstash ~]# /opt/logstash/bin/logstash-plugin list
logstash-codec-collectd
logstash-codec-dots
logstash-codec-edn
logstash-codec-edn_lines
logstash-codec-es_bulk
logstash-codec-fluent
logstash-codec-graphite
logstash-codec-json
......
Logstash插件及文档地址
https://github.com/logstash-plugins
https://www.elastic.co/guide/en/logstash/current/index.html
例如.Logstash配置从标准输入读取输入源,然后将结果输出到屏幕:
[root@logstash ~]# vim /etc/logstash/logs.conf
input{
stdin{} //标准输入
}
filter{ }
output{
stdout{} //标准输出
}
[root@logstash logstash]# /opt/logstash/bin/logstash -f /etc/logstash/logs.conf //启动
Settings: Default pipeline workers: 2
Pipeline main started
test //用键盘输入"test"
2019-10-17T11:47:20.264Z logstash test //屏幕显示"test"
2.codec类插件
常用的插件:plain,json,json_lines,rubydebug,multiline等
使用上述例子,这次输入json数据,然后设置输入源的codec是json,在输出的时候选择rubydebug,输入普通数据和json数据对比.
[root@logstash ~]# vim /etc/logstash/logs.conf
input{
stdin{ codec => "json"} //json输入
}
filter{ }
output{
stdout{ codec => "rubydebug"} //rubydebug输出
}
[root@logstash logstash]# /opt/logstash/bin/logstash -f /etc/logstash/logs.conf
Settings: Default pipeline workers: 2
Pipeline main started
abcde //输入普通数据
{
"message" => "abcde",
"tags" => [
[0] "_jsonparsefailure"
],
"@version" => "1",
"@timestamp" => "2019-10-17T11:52:28.201Z",
"host" => "logstash"
}
{"a":1,"c":3,"b":2} //输入json数据
{
"a" => 1,
"c" => 3,
"b" => 2,
"@version" => "1",
"@timestamp" => "2019-10-17T11:54:43.571Z",
"host" => "logstash"
}
3.input file插件
input{
file {
path => ["/tmp/a.log","/var/tmp/b.log"] //输入文件路径,必写
}
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
[root@logstash logstash]# touch /tmp/a.log /var/tmp/b.log
[root@logstash logstash]# echo aaa >> /tmp/a.log
[root@logstash logstash]# echo bbbb >> /var/tmp/b.log
[root@logstash logstash]# logstash -f logstash.conf
Settings: Default pipeline workers: 2
Pipeline main started
{
"message" => "aaa",
"@version" => "1",
"@timestamp" => "2019-10-16T06:20:42.492Z",
"path" => "/tmp/a.log",
"host" => "logstash"
}
{
"message" => "bbbb",
"@version" => "1",
"@timestamp" => "2019-10-16T06:20:42.550Z",
"path" => "/var/tmp/b.log",
"host" => "logstash"
}
input{
file {
path => ["/tmp/a.log","/var/tmp/b.log"]
sincedb_path => "/var/lib/logstash/sincedb" //记录读取文件的位置
start_position => "beginning" //配置第一次读取文件从什么地方开始,只有"beginning"和"end"
}
}
filter{
}
output{
stdout{ codec => "rubydebug" }
}
4.filter grok 插件
解析各种非结构化的日志数据插件;
grok 使用正则表达式把非结构化的数据结构化;
在分组匹配,正则表达式需要根据具体数据结构编写;
虽然编写困难,但使用性极广;
几乎合一应用于各类数据
grok{
match => ["message",(?<key>reg),"%{IP:clientip}"]
}
grok正则分组匹配
匹配ip时间戳和请求方法:
match => { "message" => "(?<ip>[0-9.]+)(?<ident>[0-9a-z\-]+)(?<auth>[0-9a-z\-]+)\[(?<time>.+)\]\"(?<verb>[A-Z)+(?<url>)\S+(?<proto>[A-Z]+)\/(?<ver>[0-9.]+)\"(?<rc>\d+)(?<size>\d+)\"(?<ref>\S)\"\"(?<agent>[^\"]+) \""}
使用正则宏:
match => { "message" => "%{IP:client } %{WORK:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
最终版本
match => { "message" => "%{COMBINEDAPACHELOG}" }
output ES 插件
if [type] == "apache_log"{
elasticsearch {
hosts => ["192.168.1.51:9200","192.168.1.52:9200","192.168.1.53:9200"]
index => "filelog"
flush_size => 2000 //刷新流量大小
idle_flush_time => 10 //刷新时间
}
}
调试成功后,把数据写入ES集群
input filebeats插件:
beats {
port => 5044
}
这个插件主要用来接受beats类软件发送过来的数据,由于Logstash依赖java环境,而且占用资源非常大,因此会使用更轻量的filebeat替代.
filebeat安装与配置:
使用rpm安装filebeat
#yum -y install filebeat
修改配置文件/etc/filebeat/filebeat.yml
设置开机运行:
#systemctl enable filebeat
开启服务:
#systemctl start filebeat
修改配置文件/etc/filebeat/filebeat.yml
paths:
- /root/logs.json
document_type: weblog
......
paths:
- /root/accounts.json
document_type: account
output:
logstash:
hosts:["192.168.1.57:5044"]
[root@web filebeat]# cd /etc/filebeat
[root@web filebeat]# grep -Pv "^(\s*#|$)" filebeat.yml
filebeat:
prospectors:
-
paths: #以paths为单位可以写多组
- /var/log/httpd/access log
input_type: log
document_type: apache_log
-
paths:
- /root/accounts.json log
input_type: log
document_type: json_log
registry_file: /var/lib/filebeat/registry
output:
logstash:
hosts:["192.168.1.57:5044"]
shipper:
logging:
files:
rotateeverybytes: 10485760 # = 10MB
















 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









