






OpenAI发布全新语音模型:让AI更懂你的声音
在过去的几个月中,OpenAI持续在文本智能代理(text-based agents)领域推出了诸如Operator、Deep Research、Computer-Using Agents以及内置工具的Responses API等重要更新,极大提升了AI完成各类任务的能力。然而,要真正实现直观、深入的人机交互,仅靠文本是不够的。今天,OpenAI正式推出了全新的语音转文本(STT)与文本转语音(TTS)模型,通过API即可轻松调用,帮助开发者构建更智能、更强大的语音交互体验。
更精准的语音转文本(STT)技术

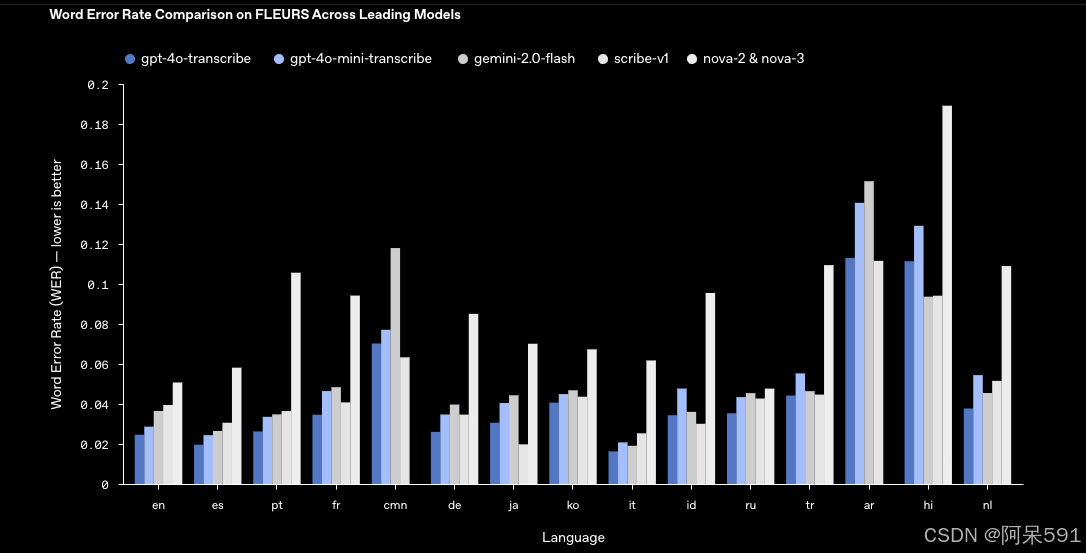
此次更新的两大语音转文本模型为gpt-4o-transcribe和gpt-4o-mini-transcribe。相比之前广受欢迎的Whisper模型,新模型在多个语言的词错误率(Word Error Rate, WER)评测中表现出色,大幅降低了转录错误率,并有效提升了对不同语言、口音、噪音环境和语速变化的适应能力。
具体而言:
- 支持超过100种语言,具备更广泛的语言覆盖。
- 在噪音环境、不同口音及语速下表现显著优于传统技术。
- 特别适用于客户服务电话记录、在线会议笔记、实时字幕生成等场景。
更具表现力的文本转语音(TTS)模型
OpenAI推出的gpt-4o-mini-tts文本转语音模型首次实现了高度定制化的表达能力。开发者不仅可以指定AI要说什么,更可以指定“如何说”,比如让AI以同理心十足的客服语气、专业严肃的语调或充满趣味的讲故事风格进行表达。
这意味着开发者可以轻松打造:
- 更人性化、更具同理心的智能客服语音。
- 创意性强、富有表现力的语音故事与内容。
- 根据场景灵活定制语音互动体验。
实时API支持,开启语音交互新时代
此次发布的Realtime API专门针对实时语音交互进行优化,支持流式音频输入输出,真正实现了“即说即听、实时互动”的语音体验。这项技术的优势在于:
- 更低延迟的响应速度,用户无需等待,即可实时交流。
- 更自然的语音互动体验,支持语音中断与即时调整。
- 广泛适用于虚拟助手、智能客服、语音控制系统等各类实时语音交互场景。
技术创新,领先行业
本次语音模型的技术突破主要源于:
- 使用更加多样化和真实的音频数据集进行预训练。
- 采用先进的模型蒸馏方法,将更大模型的知识高效迁移到更小、更快的模型上。
- 引入强化学习技术,进一步降低了语音识别错误率。
这些技术创新使得新语音模型具备了业内领先的识别精度与表达能力。
应用前景与未来展望
开发者现已能够通过OpenAI的语音模型与Realtime API快速搭建具有个性化、智能化语音互动能力的AI产品,广泛应用于智能客服、在线教育、虚拟助手、娱乐互动等多个领域。
未来,OpenAI还计划持续改进语音模型的智能性、精准性,并探索个性化定制声音的可能性。此外,OpenAI也将扩展到视频等多模态AI领域,进一步提升交互的多样性与沉浸感。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











