






文章目录
2025年3月20日,Anthropic 宣布了一项针对旗下大型语言模型 Claude 的重要更新:推出名为“思考(think)”的新工具。这一工具旨在帮助 Claude 在处理复杂问题、长链工具调用以及政策合规性任务时进行结构化的“停顿与反思”,显著提高其推理性能和决策一致性。
什么是「思考工具」?
所谓“思考工具”,顾名思义,就是为 Claude 提供一个专门的空间和步骤,让它在执行复杂任务过程中暂停下来进行更深入的自我思考,而不是急于直接给出行动或答案。具体而言,“思考工具”使 Claude 能够:
- 在长链工具调用中暂停下来,确认是否掌握了继续行动所需的所有信息。
- 处理来自外部工具调用结果的信息,评估接下来的行动策略。
- 在决策失误成本高昂的多步骤任务中,逐步验证行动计划的合规性和有效性。
尽管与此前推出的“扩展思维(extended thinking)”功能有相似之处,但两者的使用场景截然不同。“扩展思维”适用于相对简单的任务,在回答用户之前提前思考并制定行动计划,而“思考工具”则更适用于复杂、动态的环境,强调模型实时评估新信息,修正或加强行动决策。
τ-Bench 评测:实战场景的明显性能提升
Anthropic 团队使用了τ-bench(一个模拟真实客户服务对话场景的标准化评测工具)来验证这一工具的实际表现。在航空和零售两大客户服务领域,Claude 在应用“思考工具”后表现出了显著的进步:
- 在航空领域,经过优化提示的“思考工具”配置,相较于未使用任何新工具的基线表现(pass^1 指标为0.370),大幅提升了54%,达到0.570。
- 零售领域则显示,即使未经优化提示,仅使用“思考工具”,Claude 的表现也从基线的0.783提升至0.812。
τ-Bench 结果摘要(航空领域):
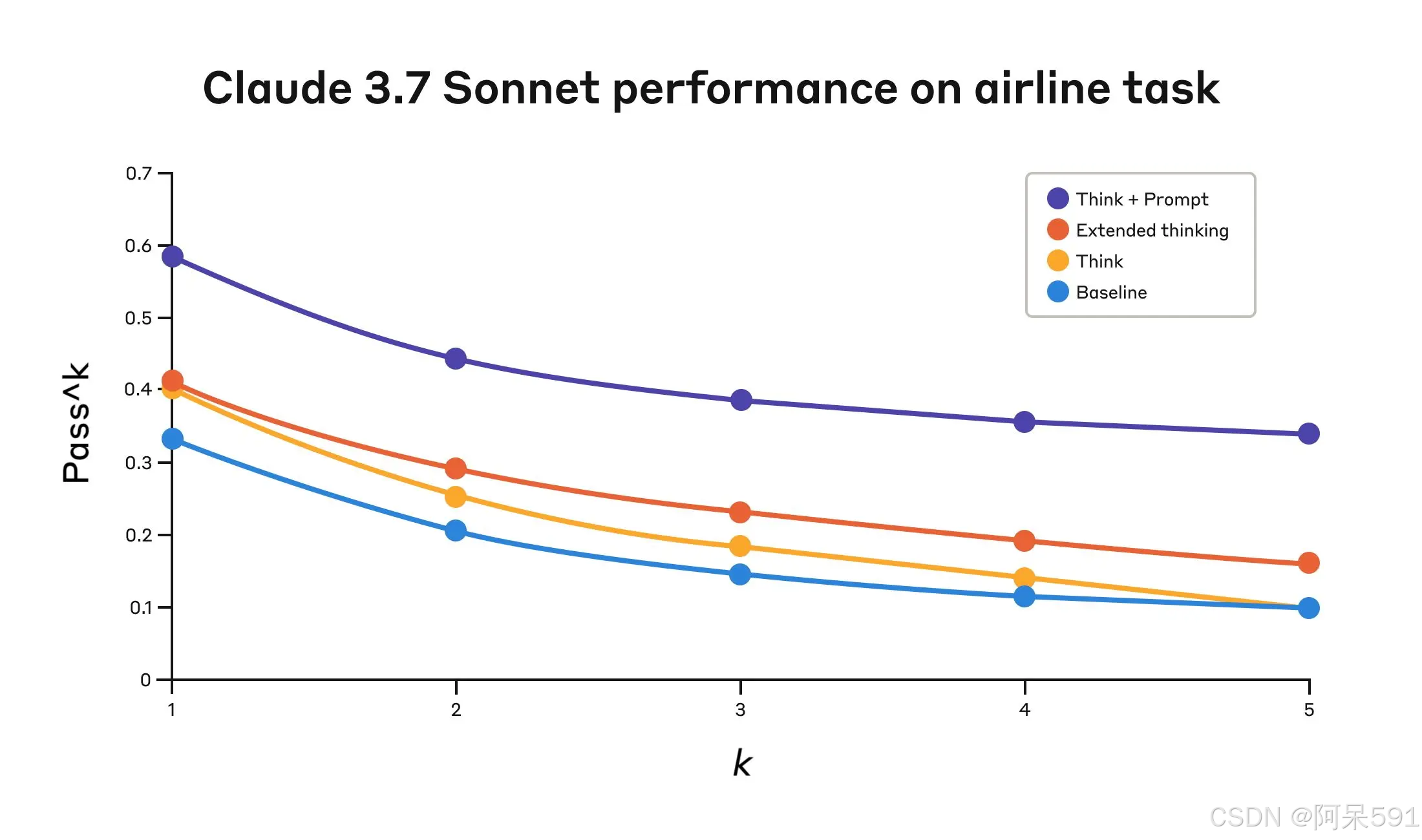
| 配置 | pass^1 | pass^2 | pass^3 | pass^4 | pass^5 |
|---|---|---|---|---|---|
| 思考工具+优化提示 | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| 单独思考工具 | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| 扩展思维 | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| 基线 | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
以上数据表明,在政策复杂、场景严苛的航空领域中,搭配优化提示的“思考工具”性能提升最为显著,这显示模型能够有效地从具体的思考示例中获益。
为什么「思考工具」表现如此突出?
此次发布尤其强调了使用明确、领域特定的提示(prompting)的重要性。Anthropic 在测试中发现:
- 对于航空等政策密集、决策复杂的场景,提供优化后的详细提示能帮助 Claude 更好地使用“思考工具”。
- 在较简单的零售领域,即便不使用额外提示,“思考工具”也能取得明显的效果提升。
这种差异主要源于特定领域政策的复杂性,以及模型对于示例引导的依赖程度。在航空领域这样政策复杂的场景中,Claude 更需要通过明确示例来引导其思维流程。
SWE-bench 软件开发领域也验证有效性
除了客户服务场景,Anthropic 在软件开发基准 SWE-bench 中也验证了“思考工具”的有效性。添加“思考工具”后,Claude 3.7 Sonnet 模型取得了0.623的最佳性能,相比未使用该工具的基线配置,平均性能提升了约1.6%。
这种提升源于模型能够在进行修复代码和测试结果分析时更加细致地思考,提出多个备选方案并谨慎选择最优解法。
如何有效实施「思考工具」?
Anthropic 同时提供了一系列最佳实践指导:
- 战略性领域提示:针对特定领域场景,明确告知 Claude 在何时以及如何使用该工具,详细指导其如何分解复杂任务并验证合规性。
- 复杂提示系统化:建议将长而详细的工具使用指导纳入系统提示(system prompt),有助于 Claude 更自然地整合到整体决策过程中。
但需要注意,“思考工具”并非万能,对以下场景并无显著效果:
- 单次或非连续的简单工具调用场景。
- 指令较简单明确、默认表现已足够好的场景。
Claude 团队的建议
Claude 团队建议开发者:
- 在具挑战性的任务中优先实施该工具,尤其是需要政策合规性和长链工具调用的场景。
- 密切监控 Claude 使用“思考工具”的表现,并持续优化提示,引导其形成有效的决策模式。
值得强调的是,“思考工具”的实现复杂度极低,不会对现有系统造成干扰,且对性能开销也很小,除非模型主动调用该工具,否则不会产生额外负担。
小结:实现更可靠、更透明的AI决策
Anthropic 此次发布的“思考工具”体现了一种新的发展趋势,即不再只是要求模型快速提供答案,而是强调模型在给出回应前进行更深入的自我检查和验证。这种方式有助于提高模型决策的稳健性、透明度和一致性,为构建更加可靠的 AI 系统提供了坚实基础。
随着模型复杂性和实际应用场景的不断拓展,这种“停下来想一想”的新模式无疑会在未来的AI工具开发中扮演越来越重要的角色。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











