







简单SVD算法
矩阵分解,就是把用户和物品都映射到一个K维空间上(一般K要比用户和物品数量药要小),这个k维空间不是直接看到的,通常称为潜在因子SVD其实是一种机器学习算法,而不是推荐算法
SVD的损失函数是这样定义的,后面的为正则化项
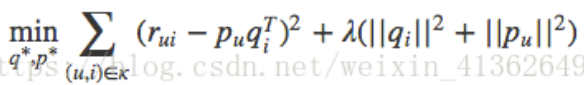
整个SVD的学习过程就是:
1)准备好用户物品的评分矩阵
2)给分解后的U矩阵和V矩阵随机初始化元素值,随机初始
3)用U和V计算预测后的分数
4) 计算预测的分数和实际的分数误差
5)按照梯度下降的方向更行U和V中的元素值(梯度下降法和交替最小二乘法)
6)重复步骤3到5,直到达到停止条件
得到分解后的矩阵之后,实质上就是得到每个用户和每个物品的潜在因子向量(不用太在意每一个潜在因子的含义),根据这两个矩阵就可以计算出打分值,简单来说就是拿着物品和用户两个向量相乘,积就是推荐分数。矩阵分解并不等于SVD,只能说矩阵分解是SVD方法之一。
在某些情况下我们使用加权矩阵分解(WMF weighted matrix factorization)来学习潜在因子向量,他是一种针对于隐性反馈改进的矩阵分解算法
其他方法:1.没评分的都是负反馈2.按正反馈的比例进行负反馈,重点是那些很热门却没有被评分的
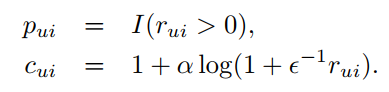 cui=1+arui
cui=1+arui
对每一对用户物品对,定义一个偏好变量pui,定义一个信心变量cui。rui是用户u对歌曲i的播放次数,I(x)是指示函数(指示函数就表示如果满足后面那个条件,就是1,不满足就是0),![]() 是超参数
是超参数
pui表示用户u是否听过歌曲i,如果这个值是1,就假定用户喜欢这首歌。cui衡量我们对这种特定偏好的确定程度。如果用户播放这个音乐次数越多,则c就越高,没播放过则c就很低。
WMF目标函数公式是
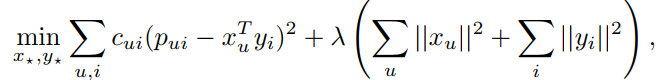
两种方法进行迭代
梯度下降法(不适用于加权)
求导加迭代
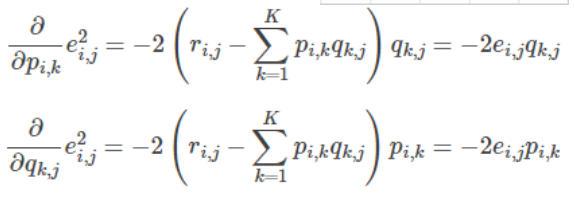
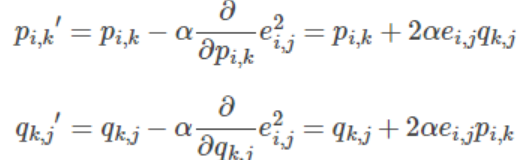
交替最小二乘法
x和y交替进行更新
不加权的算法(也不加正则化项)

加权

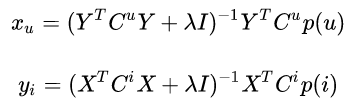
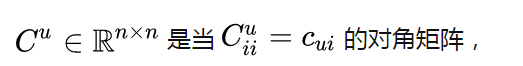
![]()
I是恒矩阵,对角线为1的方阵















 670
670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









