








[AAAI 2020] Improved Knowledge Distillation via Teacher Assistant
Motivation
知识蒸馏目前已被广泛应用,但是我们发现,当student和teacher间的size gap较大时,student的性能会下降。teacher只能有效将其知识蒸馏给一定大小的student,更小的student无法充分学习到teacher的信息。为了缓解这个问题,我们引入了多步知识蒸馏,应用一个中间大小的网络(助教)来弥补teacher和student之间的gap。
Assistant based Knowledge Distillation
The Gap Between Student and Teacher
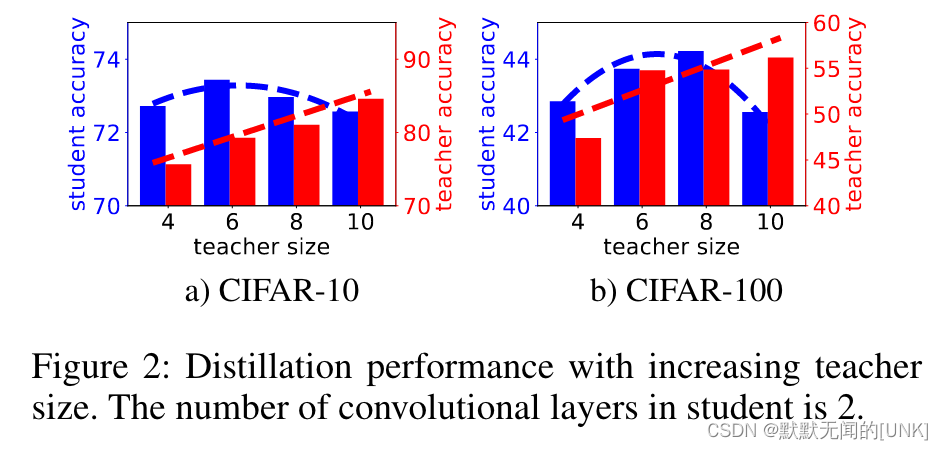
如图二所示,当增加teacher size的时候,它自己的准确率在上升。然而,student的准确率先上升后下降。为了解释这种现象,我们可以列举几个在增大teacher size时相互竞争的因素:
- teacher的表现提高,因此它可以更好地预测来为学生提供更好的监督。
- teacher变得复杂,以至于student没有足够的能力来模仿teacher的行为。
- teacher对数据的确定性增加,从而使其logits变得不那么soft(更加偏向于ground truth的one-hot标签),这削弱了通过匹配soft label完成的知识转移。
因素1是增大teacher size带来的好处,而2、3是相反的。最开始,增大teacher size时,因素1影响更大;而继续增大size,因素2和3更加影响蒸馏表现。
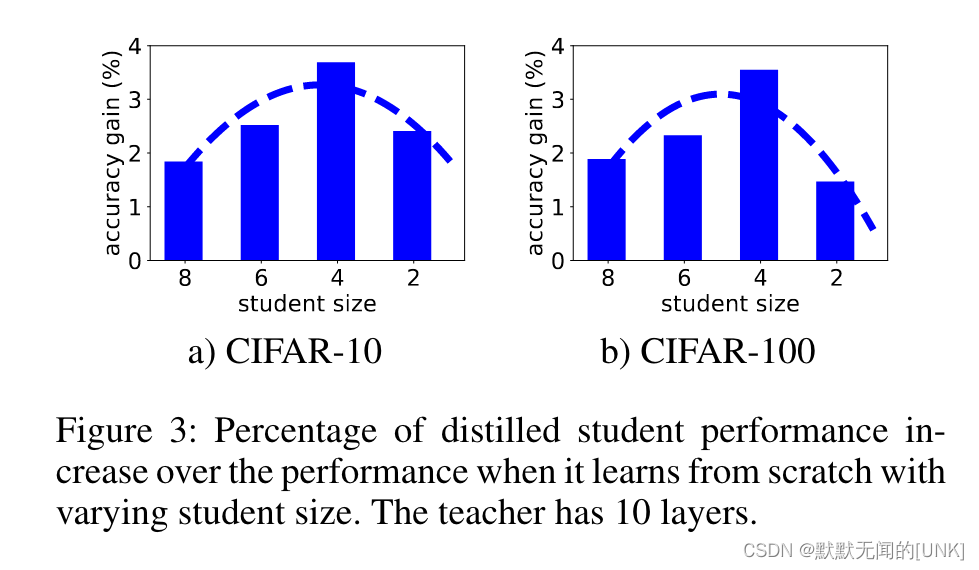
考虑其对偶问题。如图3所示,当固定teacher,减少student的size时,因素 1 会首先增加student的性能,而因素 2 和 3 会逐渐占上风,并使性能提高降低。
Teacher Assistant Knowledge Distillation (TAKD)
考虑teacher和student都固定的现实场景,本文提出使用中间大小的网络(teacher assistant, TA)来填补teacher和student之间的gap。首先,TA网络由teacher蒸馏得到。然后,TA扮演teacher的角色来蒸馏student。这个策略能缓解因素2的影响。因此,student能更有效地学习TA的logit分布。它也能通过使用更加soft、更低置信的目标来缓解因素3的影响。
Experiment
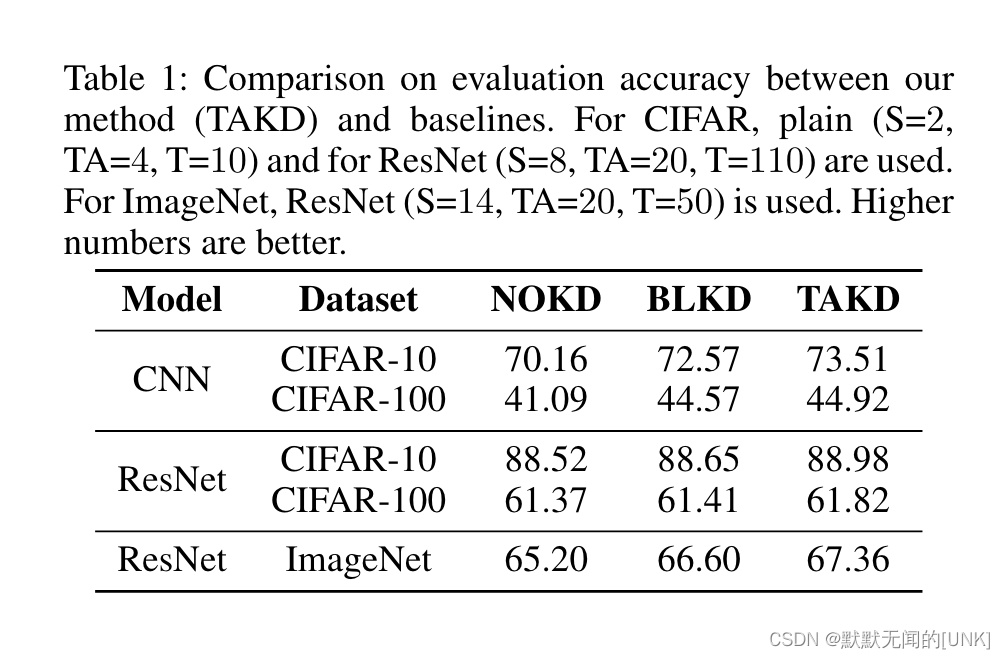
NOKD:不使用蒸馏
BLKD:直接蒸馏的方法
TAKD性能超过了NOKD和BLKD。
What is the Best TA Size?
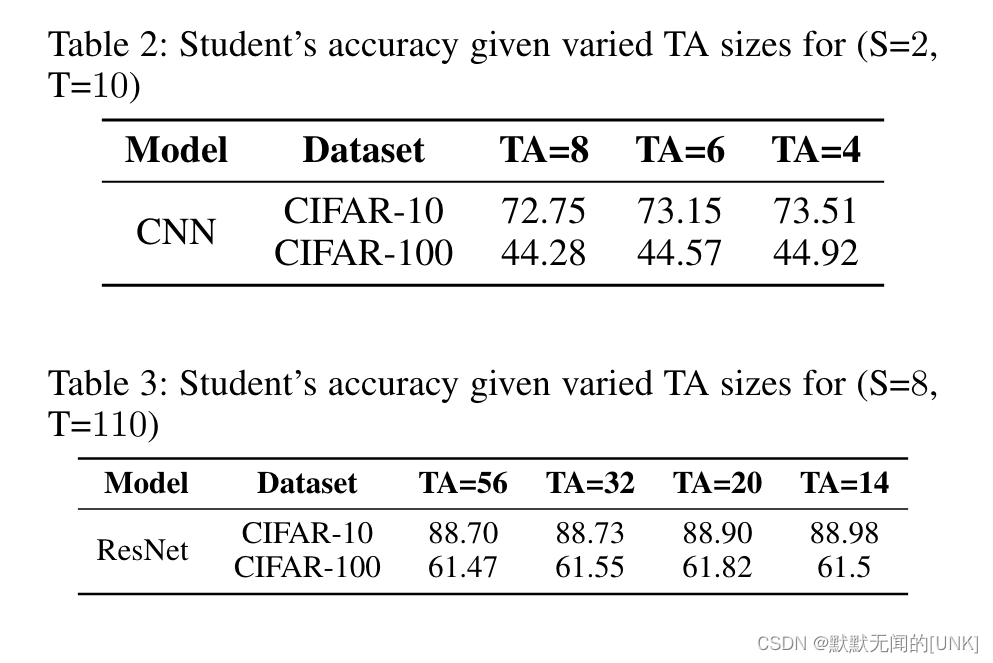
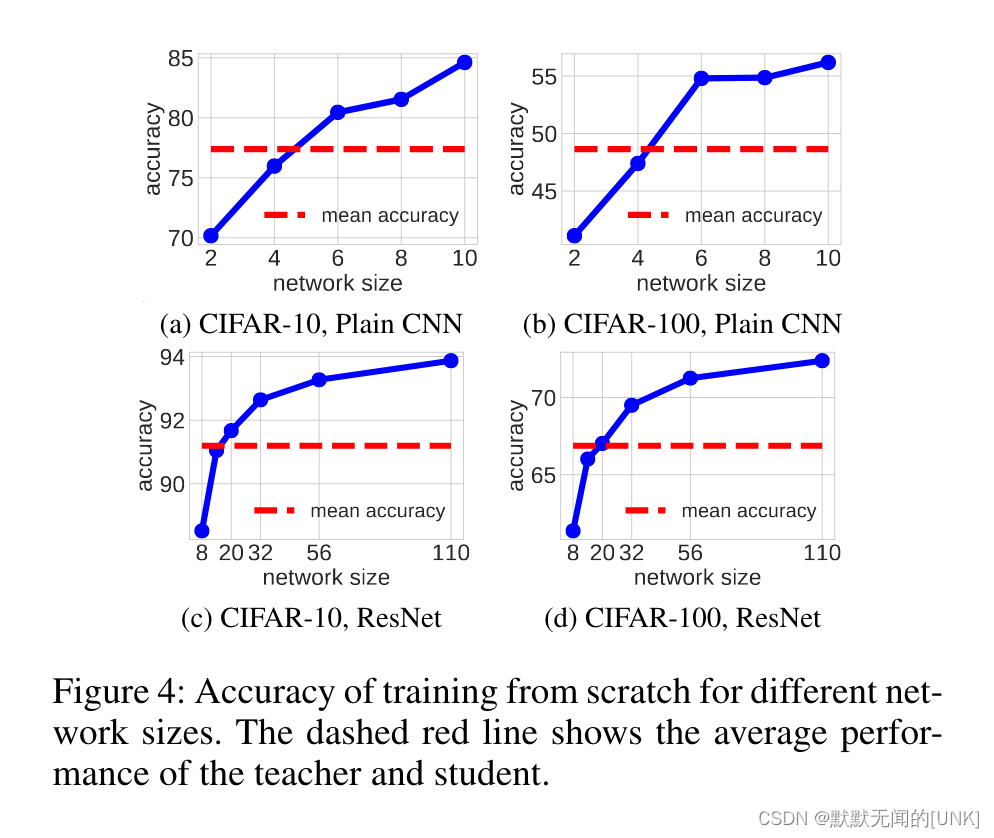
结论:
- 如表2、3所示,使用任意大小的TA都能提升student的性能。
- 如图4所示,TA的性能更接近teacher和student的平均性能(而不是TA的size更接近teacher和student的平均size)时,TAKD的性能更好。
Why Limiting to 1-step TA?
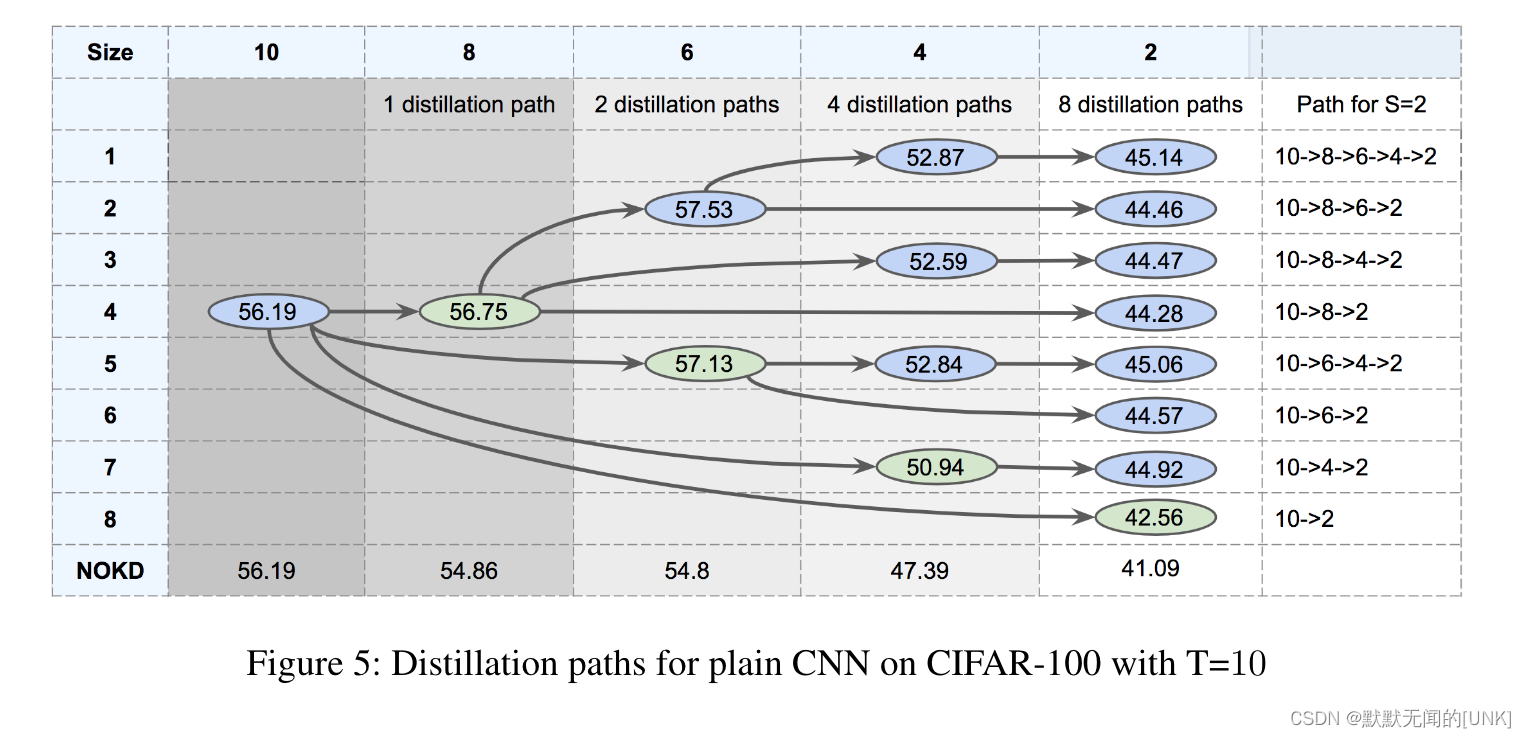
如图5,绿色的是直接蒸馏,最后一行是不使用蒸馏,蓝色的为TAKD。
结论:
- 对于所有的student size,TAKD都比BLKD和NOKD更好。
- 如size=2的列所示,所有的多步TAKD效果都很好,比NOKD和BLKD性能高很多。
- 如size=2、4的列所示,遍历所有可能的中间TA网络效果最好(如10->8->6->4->2优于所有其他路径)。
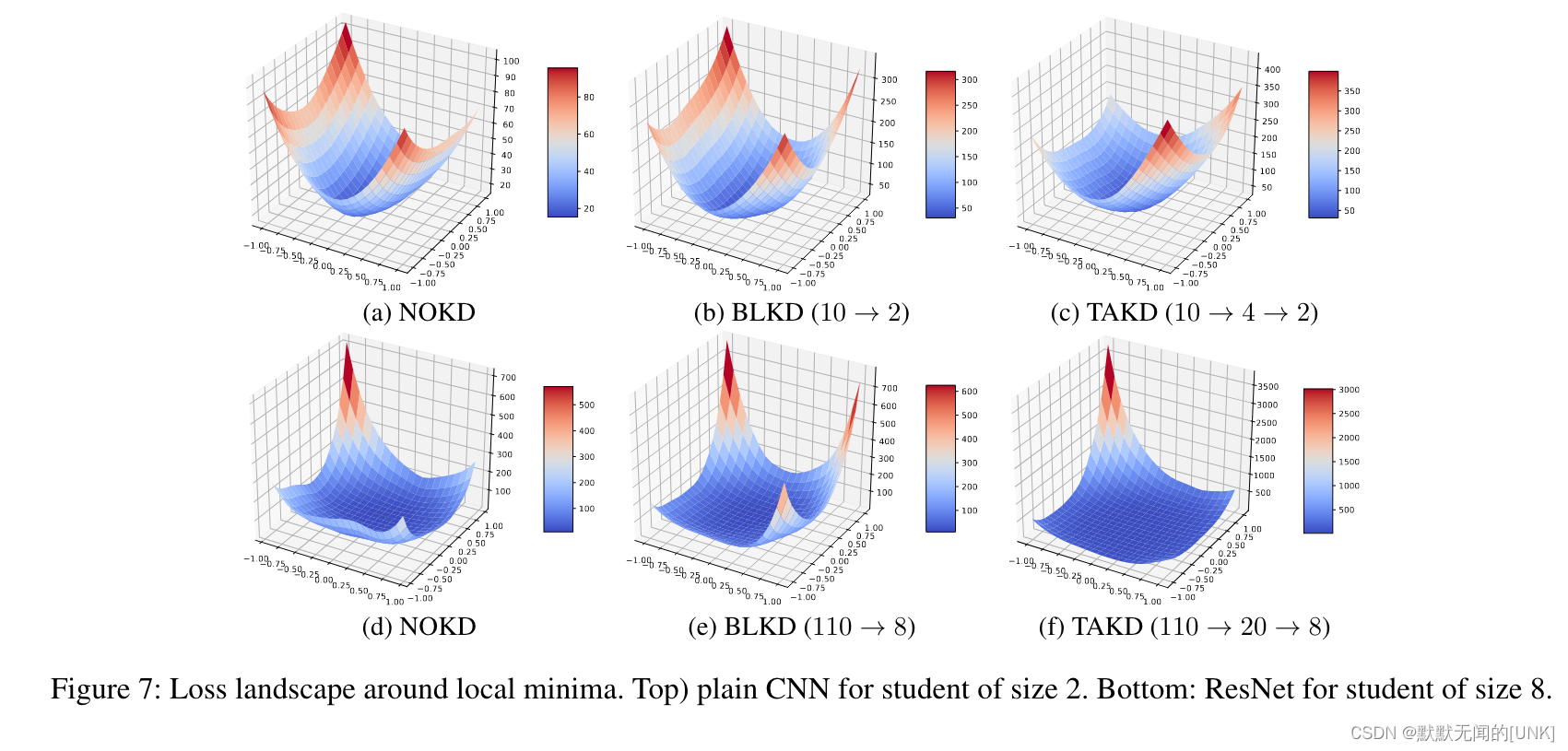
从图7可以看到,TAKD在局部最小值周围有一个更平坦的表面。 这与抗噪声输入的鲁棒性有关,从而导致更好的泛化。
Why Using a Distilled TA?
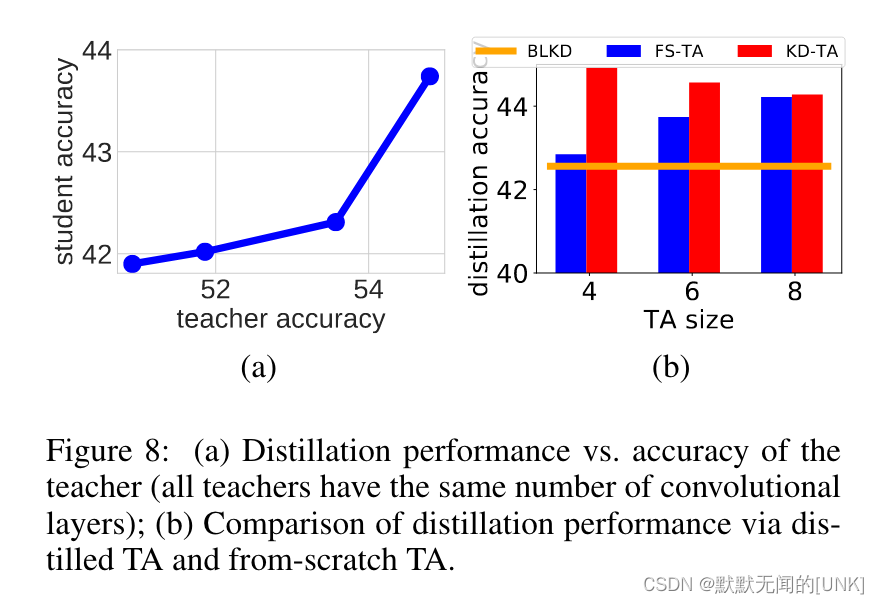
为什么不使用一个finetuned TA,而是蒸馏的TA呢?
原因:蒸馏的TA性能更好,而在teacher架构固定的情况下,teacher的性能越高,student的性能也越高(如图8a)。
Conclusion
当teacher和student之间size gap较大时,使用一个中间大小的TA模型进行助教蒸馏效果更好。具体过程为,teacher蒸馏TA模型,TA模型蒸馏student。实验结果表明,无论使用什么size的中间TA,效果都优于直接蒸馏student模型。一般情况下,TA的性能接近teacher和student的平均性能时,助教蒸馏的效果更好。















 589
589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









