









[ECIR 2022] Improving BERT-based Query-by-Document Retrieval with Multi-Task Optimization
Keywords: Document Retrieval, Multi-task optimization
Motivation
Query-by-document检索是使用一个document作为query来检索相关的document。基于BERT等PLMs的排序模型会面临最大输入长度的限制,然而近来的工作也证明了许多用于处理长文本的transformer-based models 在被应用到长文本检索任务时,也不够有效。基于此,本文研究在有限输入长度的限制下提升基于BERT的排序模型的检索性能。
Approach
BERT-based Ranking
给定q和d,相关性分数s如下计算:
s
(
q
,
d
)
=
B
E
R
T
(
[
C
L
S
]
q
[
S
E
P
]
d
[
S
E
P
]
)
[
C
L
S
]
∗
W
p
s(q,d) = BERT([CLS] \ q\ [SEP] \ d\ [SEP])_{[CLS]}*W_p
s(q,d)=BERT([CLS] q [SEP] d [SEP])[CLS]∗Wp
BERT-based Representation Learning
给定d,其表示
r
d
r_d
rd计算如下所示:
r
d
=
B
E
R
T
(
[
C
L
S
]
d
[
S
E
P
]
)
[
C
L
S
]
r_d = BERT([CLS]\ d\ [SEP])_{[CLS]}
rd=BERT([CLS] d [SEP])[CLS]
Pairwise Ranking Loss
l
r
a
n
k
=
−
l
o
g
e
s
c
o
r
e
(
q
,
d
+
)
e
s
c
o
r
e
(
q
,
d
+
)
+
e
s
c
o
r
e
(
q
,
d
−
)
l_{rank} = -log \frac{e^{score(q,d^+)}}{e^{score(q,d^+)}+e^{score(q,d^-)}}
lrank=−logescore(q,d+)+escore(q,d−)escore(q,d+)
推理时,模型只被用作point-wise的预测。
Triplet Representation Learning Loss
为了使q与相关文档的距离比q与不相关文档更近,引入下面loss:
l
r
e
p
r
e
s
e
n
t
a
i
o
n
=
m
a
x
{
(
f
(
r
q
,
r
d
+
)
−
f
(
r
q
,
r
d
−
)
+
m
a
r
g
i
n
)
,
0
}
l_{representaion} = max\{(f(r_q,r_{d^+})-f(r_q,r_{d^-})+margin),0\}
lrepresentaion=max{(f(rq,rd+)−f(rq,rd−)+margin),0}
其中,f是距离指标 (实验中使用L2-norm),margin确保
d
+
d^+
d+与q的距离至少比
d
−
d^-
d−与q的距离大 margin (实验中设为1)。
Multi-task fine-tuning of the BERT re-ranker
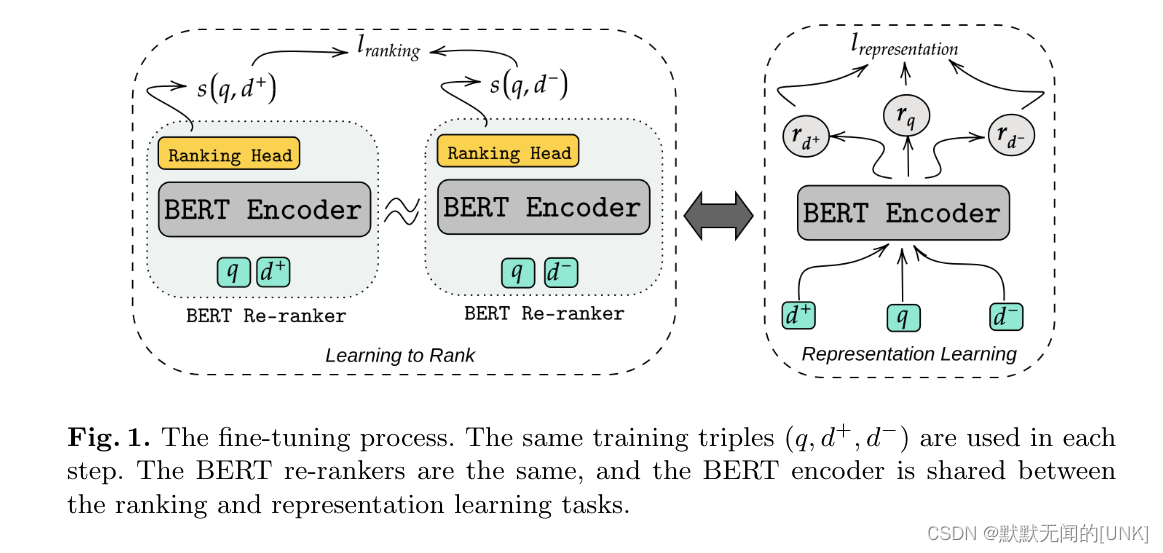
我们首先将q和
d
+
d^+
d+,q和
d
−
d^-
d−拼接到一起分别输入到模型中,来计算pairwise loss
l
r
a
n
k
l_{rank}
lrank。然后,我们将q,
d
+
d^+
d+,
d
−
d^-
d−分别输入到模型中来计算
l
r
e
p
r
e
s
e
n
t
a
t
i
o
n
l_{representation}
lrepresentation。共享的encoder通过下面的损失来fine-tune:
l
a
g
g
r
e
g
a
t
e
d
=
l
r
a
n
k
+
λ
l
r
e
p
r
e
s
e
n
t
a
t
i
o
n
l_{aggregated} = l_{rank}+\lambda l_{representation}
laggregated=lrank+λlrepresentation
推理时,只使用re-ranker的ranking head,见图1。
Experiment
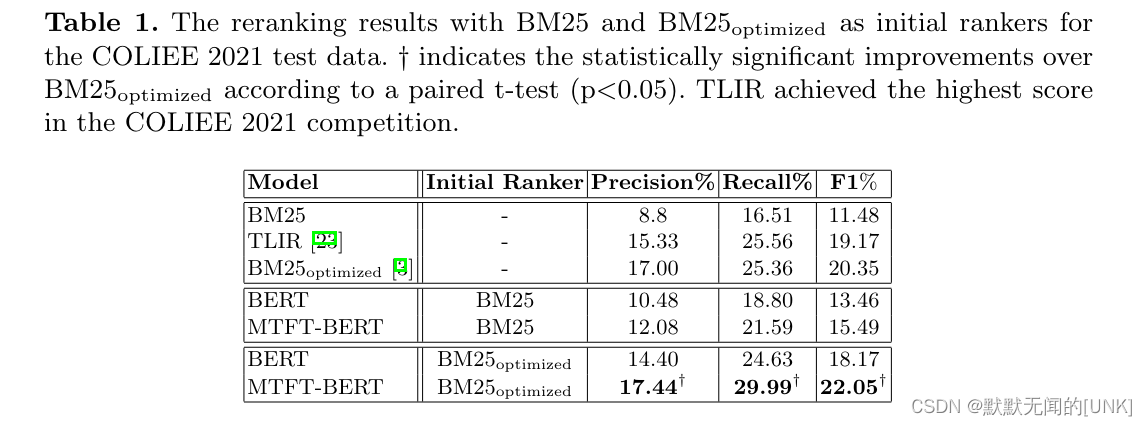
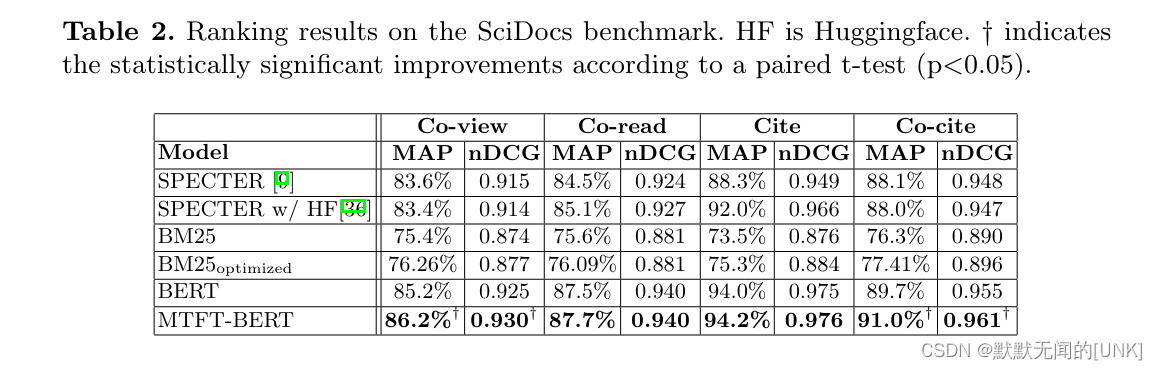
Robustness to varying
λ
\lambda
λ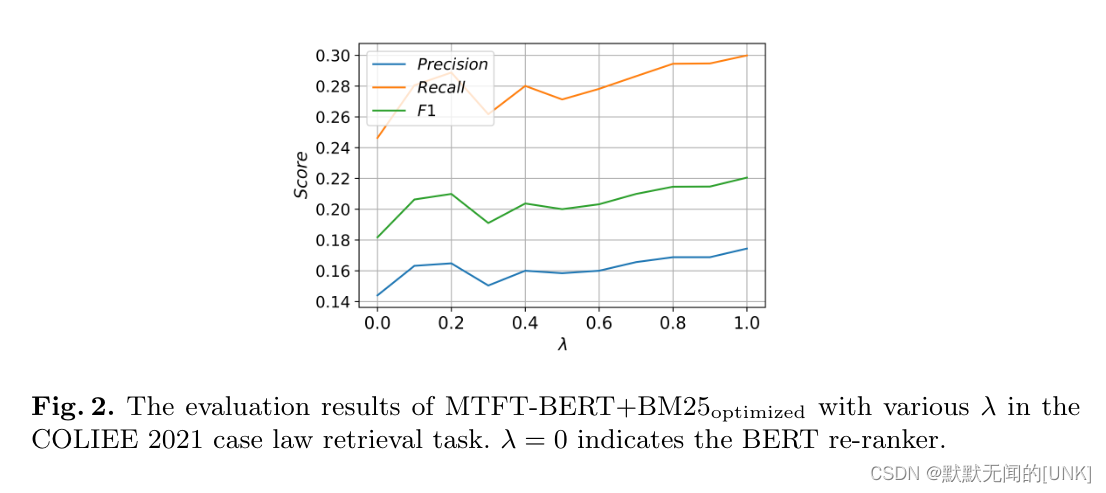
这里也可以看作对表示损失的消融实验, λ = 0 \lambda = 0 λ=0时即没有加入表示损失。证明了加入表示损失的有效性。
Conclusion
这个想法很novel,BERT作为re-ranker的时候,需要将两个文本拼接到一起输入,本文提出同时将这些文本单独输入BERT,并使用triplet loss来优化模型对文本的表示。















 3347
3347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









