







前言
注意力(Attention)机制[2]由Bengio团队与2014年提出并在近年广泛的应用在深度学习中的各个领域,例如在计算机视觉方向用于捕捉图像上的感受野,或者NLP中用于定位关键token或者特征。谷歌团队近期提出的用于生成词向量的BERT[3]算法在NLP的11项任务中取得了效果的大幅提升,堪称2018年深度学习领域最振奋人心的消息。而BERT算法的最重要的部分便是本文中提出的Transformer的概念。
正如论文的题目所说的,Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
作者采用Attention机制的原因是考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片t的计算依赖 t−1时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
Transformer的提出解决了上面两个问题,首先它使用了Attention机制,将序列中的任意两个位置之间的距离是缩小为一个常量;其次它不是类似RNN的顺序结构,因此具有更好的并行性,符合现有的GPU框架。论文中给出Transformer的定义是:Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。
遗憾的是,作者的论文比较难懂,尤其是Transformer的结构细节和实现方式并没有解释清楚。尤其是论文中的
Q,V,K究竟代表什么意思作者并没有说明。通过查阅资料,发现了一篇非常优秀的讲解Transformer的技术博客。本文中的大量插图也会从该博客中截取。首先感谢Jay Alammer详细的讲解,其次推荐大家去阅读原汁原味的文章。
1. Transformer 详解
1.1 高层Transformer
论文中的验证Transformer的实验室基于机器翻译的,下面我们就以机器翻译为例子详细剖析Transformer的结构,在机器翻译中,Transformer可概括为如图1:

Transformer的本质上是一个Encoder-Decoder的结构,那么图1可以表示为图2的结构:

如论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入,如图3所示:

我们继续分析每个encoder的详细结构:在Transformer的encoder中,数据首先会经过一个叫做‘self-attention’的模块得到一个加权之后的特征向量 Z,这个 Z便是论文公式1中的 Attention(Q,K,V):
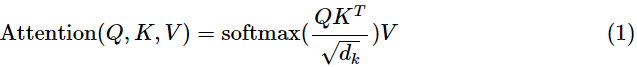
第一次看到这个公式你可能会一头雾水,在后面的文章中我们会揭开这个公式背后的实际含义,在这一段暂时将其叫做 Z。
得到
Z之后,它会被送到encoder的下一个模块,即Feed Forward Neural Network。这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:
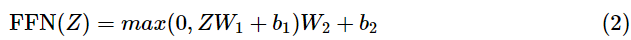
Encoder的结构如图4所示:

Decoder的结构如图5所示,它和encoder的不同之处在于Decoder多了一个Encoder-Decoder Attention,两个Attention分别用于计算输入和输出的权值:
- Self-Attention:当前翻译和已经翻译的前文之间的关系;
- Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。

1.2 输入编码
1.1节介绍的就是Transformer的主要框架,下面我们将介绍它的输入数据。如图6所示,首先通过Word2Vec等词嵌入方法将输入语料转化成特征向量,论文中使用的词嵌入的维度为 dmodel = 512。

在最底层的block中,x将直接作为Transformer的输入,而在其他层中,输入则是上一个block的输出。为了画图更简单,我们使用更简单的例子来表示接下来的过程,如图7所示:

1.3 Self-Attention
Self-Attention是Transformer最核心的内容,然而作者并没有详细讲解,下面我们来补充一下作者遗漏的地方。回想Bahdanau等人提出的用Attention,其核心内容是为输入向量的每个单词学习一个权重,例如在下面的例子中我们判断it代指的内容
The animal didn't cross the street because it was too tired
通过加权之后可以得到类似图8的加权情况,在讲解self-attention的时候我们也会使用图8类似的表示方式

在self-attention中,每个单词有3个不同的向量,它们分别是Query向量(Q),Key向量(K)和Value向量(V),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量 X乘以三个不同的权值矩阵 WQ,WK,WV得到,其中三个矩阵的尺寸也是相同的。均是 512×64 。

那么Query,Key,Value是什么意思呢?它们在Attention的计算中扮演着什么角色呢?我们先看一下Attention的计算方法,整个过程可以分成7步:
- 如上文,将输入单词转化成嵌入向量;
- 根据嵌入向量得到 q,k,v三个向量;
- 为每个向量计算一个score: score=q⋅k;
- 为了梯度的稳定,对score除以 √dk;
- 对除以√dk的score用softmax进行归一化;
- softmax点乘Value值 v,得到加权的每个输入向量的评分 v;
- 相加之后得到最终的输出结果 z: z=∑v。

实际计算过程中是采用基于矩阵的计算方式,那么论文中的 Q, V, K的计算方式如图11:

总的公式矩阵形式:

在self-attention需要强调的最后一点是其采用了残差网络 [5]中的short-cut结构,目的当然是解决深度学习中的退化问题,得到的最终结果如图13。

Query,Key,Value的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是Query,然后搜索引擎根据Query为你匹配Key(例如商品的种类,颜色,描述等),然后根据Query和Key的相似度得到匹配的内容(Value)。
self-attention中的Q,K,V也是起着类似的作用,在矩阵计算中,点积是计算两个矩阵相似度的方法之一,因此式1中使用了 Q*KT(K的转置)进行相似度的计算。接着便是根据相似度进行输出的匹配,这里使用了加权匹配的方式,而权值就是query与key的相似度。
输入部分为embedding、位置嵌入















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









