







文章目录
前言
仅为个人学习笔记,综合了很多笔记和论文,侵权删,仅供学习参考!!!发现错误非常欢迎来argue。
一、Encoder-Decoder Architecture
综合两篇笔记:知乎上的[论文笔记] SegNet: Encoder-Decoder Architecture和CSDN上的Encoder-Decoder综述理解(推荐)。我给出我的理解。
Encoder-Decoder代表了一类框架的统称,中文名叫做编码器-解码器,最早是在 2014 年提出的。它首次出现在一篇名为 “Sequence to Sequence Learning with Neural Networks” 的论文中,这一类框架在自然语言处理和计算机视觉中被广泛运用,在这个框架下可以使用不同的算法来解决不同的任务。首先,编码(encode)由一个编码器将输入序列或者图片转化成一个固定维度的稠密向量,解码(decode)阶段将这个激活状态生成目标序列或者图像。下图展示了encoder-decoder的功能:

其中,从Encoder到向量的这一中间步骤和向量到Decoder的中间步骤是我们需要设计的。
1.SegNet结构
下面是该结构论文的一个例子,展示了一个CV领域中的Encoder-decoder的实例:

该实例是著名的SegNet结构,这里面每一小片代表了一个神经网络算法,这里是我们可以设计的地方。我们可以结合一些别的机制,比如自注意力机制,该结构在很多论文中都有应用。
2.U-net结构
除了SegNet结构,常用的编码器结构还有U-net结构,下面是论文中的图:

U-Net原理分析与代码解读中具体讲解了U-net网络结构。该论文的代码开源在这里
3.DeepLab结构
后面有需要再看
二、self-attention
2.1.attention(注意力机制)
人工智能兴起于大数据,但也会受限于大数据,我们需要在海量数据中,确定我们需要的部分,这一点也模拟了人脑的注意力,我们在阅读文章,看一张图片时,我们并不会对每一处细节都细究,attention就是希望模拟这一特点的机制。下图是一个例子,人的眼睛会重点聚焦在红色区域,这些红色区域,可能会包含更多的信息。

但是对于传统的CNN,LSTM,他们并不能意识到什么重要,什么不重要,因此,对注意力机制的研究从很早就开始了,最早是由 Dzmitry Bahdanau, Kyunghyun Cho 和 Yoshua Bengio 在 2014 年发表的一篇论文 “Neural Machine Translation by Jointly Learning to Align and Translate” 中提出的。注意力机制必定设计到对注意力怎么进行表示?下图介绍了一种注意力机制,该图来源于这里
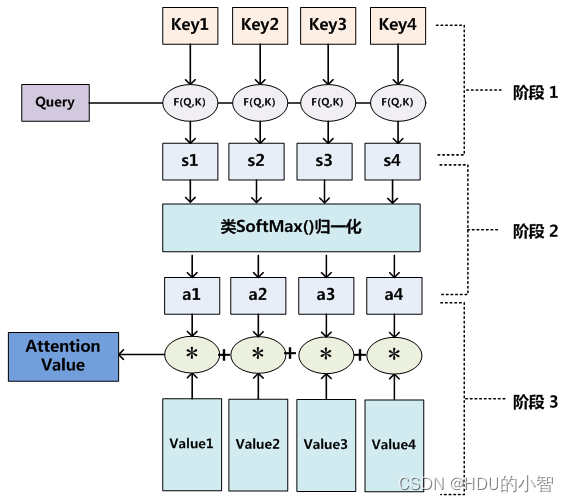
(Query,Q):查询向量表示当前位置或区域的信息,用于与键向量进行匹配以计算权重。在计算机视觉中,查询向量通常由卷积神经网络(CNN)提取的特征图的线性变换得到。
(Key,K):键向量表示输入图像或视频的其他区域的索引或标签信息,用于与查询向量进行匹配。与查询向量类似,键向量也是由特征图的线性变换得到的。
(Value,V):值向量表示输入图像或视频的其他区域的具体信息。在计算权重后,值向量会根据权重进行加权求和,得到输出向量。值向量同样由特征图的线性变换得到。
这三个值组成了一个token。为了更好地理解Q、K和V,可以将它们看作是一种在输入元素之间建立关系的机制。查询向量Q表示我们想要关注的当前元素,键向量K表示输入元素的上下文信息,值向量V则表示输入元素的实际内容。通过计算Q和K之间的相似度也就是图片中的s1,…,s4,我们可以找到与当前元素最相关的信息,并根据这些信息对V进行加权求和,从而得到一个关注到最相关信息的输出向量。
2.2. What is self-attention?
self-attention作为一种注意力机制,由 Vaswani 等人在 2017 年的论文 “Attention is All You Need” 中首次提出的。这篇论文中提出了大名鼎鼎的 Transformer 模型,该模型完全基于自注意力机制和位置编码,摒弃了传统的 RNN 和 CNN 结构。在之后,ViT模型被提出,transformer被引入计算机视觉领域。引用一个B站up主视频中的图片,self-attention的计算过程大体如下:

在自注意力中,Q、K和V都是由输入数据经过不同的线性变换得到的,也就是分别乘以一个权重向量(矩阵) W Q W_Q WQ, W K W_K WK, W V W_V WV。之后,查询向量Q和键向量K进行点积,然后通过Softmax函数计算归一化权重。接着,将归一化权重应用于值向量V,得到加权求和的输出向量。这个过程可以捕获输入序列中不同元素之间的依赖关系,帮助模型更好地理解输入数据。
以上过程可以被总结为一个常用的注意力计算公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention\left( {Q,K,V} \right) = softmax \left( {\frac{{Q{K^T}}}{{\sqrt {{d_k}} }}} \right)V Attention(Q,K,V)=softmax(dkQKT)V
其中,点积可以用来表示相似度,点积值越大,相似度越高。 d k d_k dk表示向量的维度,之所以 Q K T QK^T QKT还要除以一个 d k {\sqrt {{d_k}} } dk,是因为当维度过大时, Q K T QK^T QKT的也容易会过大,softmax的梯度会趋近于0,也就是梯度消失现象。除以一个 d k {\sqrt {{d_k}} } dk可以缓解该问题。这里的细节可以参考transformer的原文。
对于Attention 和 Self-Attention 的关系,可以这么说,也就是自注意力机制(self-attention)是一种注意力机制(attention),在Q、K、V的计算上会有独特性。
2.3. What is multi-head self-attention?
Multi-head self-attention(多头自注意力机制) 是 self-attention 的一个扩展,旨在使模型能够同时关注输入序列的不同表示子空间。在自注意力中,输入数据通过一个单一的注意力模块,生成一个输出向量。然而,在 multi-head self-attention 中,输入数据通过多个注意力模块(称为“头”)进行处理,每个模块关注不同的表示子空间。下图依然是那个视频中的例子。

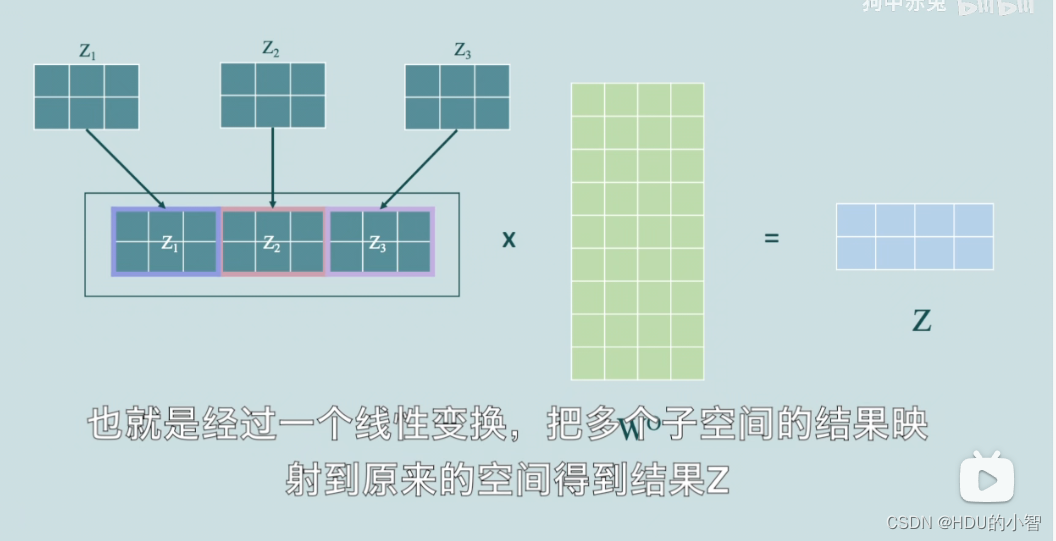
可以发现,multi-head self-attention是通过并行多个self-attention而开展的,将得到的h个矩阵拼接起来后可以得到一个大特征矩阵,和权重矩阵
W
O
W^O
WO相乘,这样就可以把多个子空间的结果映射到原来空间,得到结果Z
狗中赤兔老师把multi-head self-attention类比为假设我们现在在学一门外语,有一个例句,我们找不同的老师去答疑。有的老师告诉了我们每个词的意思,另一个老师告诉了我们哪个指代的是哪个词,还有一个老师给我们讲解了一下这句话的语法,我们将这几个老师的回答进行一下总结,就可以比较全面地理解这个句子。当然不是问越多的人越好,多头注意力机制也不是头越多越好。
使用 multi-head self-attention 而非单一的 self-attention 的优势在于,模型可以同时关注输入序列的多个方面。例如,在自然语言处理任务中,multi-head self-attention 可以帮助模型同时捕获词语的语法、语义和其他相关信息;在计算机视觉任务中,multi-head self-attention 可以帮助模型同时关注图像的不同空间区域、颜色、纹理等。这有助于提高模型的性能和泛化能力。
2.4. Else attention
事实上,self-attention并不一定不是最好的注意力机制,清华大学在2021年发布过一篇关于注意力机制的综述,里面引用近200篇论文,对计算机视觉领域中的各种注意力机制进行了全面回顾。
该论文链接
他们整理的资源汇总
这或许是真正的,Attention is all you need.
三、Transformer
Transformer模型可以被理解为是Encoder-Decoder架构和Self-Attention机制的结合。Transformer模型由Vaswani等人在2017年的论文《“Attention is All You Need”》中提出,其核心思想是使用自注意力(Self-Attention)机制来捕捉输入序列中的长距离依赖关系,从而摒弃了传统的RNN和CNN结构。
Transformer模型的整体结构分为两部分:Encoder部分和Decoder部分。Encoder负责对输入序列进行编码,而Decoder负责根据编码的表示来生成输出序列。在Transformer模型中,Encoder和Decoder都是由多层堆叠而成,每一层都包含了Self-Attention机制和前馈神经网络。Self-Attention机制允许模型在不同位置的输入序列中关注不同的信息,使得模型能够更好地捕捉长距离依赖关系。

狗中赤兔老师给了一个transformer模型的demo,而每个子层后,又多了一个Add&Norm层,Add表示层输入与层输出相加,这一个操作借鉴了残差网络,目的是防止退化,而Norm表示layer normalization,是对向量进行标准化操作来加速收敛。而在decoder部分还多了一个mask操作,这一操作有两种,对于超过期望序列长度的序列输入,我们只保留期望长度内的内容。对于未达到期望序列长度的序列输入,我们用负无穷来填充。因为填充值无任何意义,而在计算注意力的时候,softmax(-无穷)的值会为0,比较符合实际,这一操作也叫padding mask。
对于图像处理任务,Transformer模型同样可以发挥很好的效果。最近几年,图像处理领域的Transformer模型变得越来越流行,如ViT(Vision Transformer)和DeiT(Data-efficient Image Transformer)等。
总结
以上为我个人综合各种各样的笔记,我希望能够帮助大家理解,如果有错误,非常非常欢迎大家来argue我。我认为基于transformer框架的模型,可以排列组合各种机制来试出最好的搭配,现在的encoder-decoder和attention已经有非常多的创新和架构了,大部分也都是开源的,我打算照这个思路去实现我的问题。














 1942
1942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









