







数据清洗 缺失值处理 删除法(占比极少) 插补法(均值插补,回归插补,极大似然估计) 噪声过滤(减少随机误差) 回归法:一个函数拟合数据来使得数据光滑,达到去噪效果。 均值平滑法:对于具有序列特征的变量用邻近的若干数据的均值来替换原始数据的方法。 离群点分析:通过聚类等方法来检测离群点,并将其删除,从而实现去噪的方法。 小波去噪法:本质是一个函数逼近问题,即如何在由小波母函数伸缩和平移所展成的函数空间中,根据提出的衡量准则,寻找对原始信号的最佳逼近,以完成原信号和噪声信号的区分。 数据集成 将若干个分散的数据源中的数据,逻辑地或物理地集成到一个统一的数据集合中。对于数据表集成,主要有内接和外接两种方式。 数据归约 目的是得到能够与原始数据集近似等效,甚至更好但数据量较少的数据集。这样,对于归约后的数据集进行挖掘将更有效,且能够产生相同(或几乎相同)的挖掘效果。 常用策略:属性选择(通过删除不相关或冗余的属性来减少数据量),样本选择(数据抽样) 数据变换 数据的标准化 数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。 数据的离散化 把连续型数据切分为若干“段”,也称为bin,是数据分析中常用的手段。
语义转换 通过改变属性值的数据类型的方式,使得属性值含义得到更简洁表示。1:积极,0:中级,-1:消极
1,数据分析方法
1.1,基本数据分析
基本数据分析又称为描述性统计,一般统计某个变量的个数、均值、标准差、最小值、25%分位置、50%分位值、75%分位值,以及最大值。常用的统计分析指标有计数、求和、求均值、方差、标准差等。
import numpy as np import pandas as pd #分析人的使用左右手跟情商(eq)、智商(iq)的关系 df =pd.DataFrame({"HAND":np.random.randint(0,10,size = 200),"sex":np.random.randint(0,2,size = 200),"iq":np.random.randint(0,100,size =200),"eq":np.random.randint(0,100,size = 200)}) print(df.head()) print('iq列描述统计分析',df.iq.describe()) print('iq列个数',df.iq.size) print('iq列的最大值',df.iq.max()) print('iq列的均值',df.iq.mean()) =================================== HAND sex iq eq 0 3 0 24 6 1 9 0 81 9 2 3 1 59 93 3 0 0 29 68 4 5 0 18 36 iq列描述统计分析 count 200.000000 mean 47.765000 std 28.660546 min 0.000000 25% 23.000000 50% 46.000000 75% 74.000000 max 99.000000 Name: iq, dtype: float64 iq列个数 200 iq列的最大值 99 iq列的均值 47.765
1.2,分组分析
分组分析是指根据分组字段,将分析对象划分成不同的部分,以对比分析各组之间差异性的分析方法。
groupby(by=[分组列1, 分组列2, ...]) [统计列1, 统计列2, ...] .agg({统计列别名1:统计函数1, 统计列别名2:统计函数2, ...}) -by:用于分组队列。 -中括号[]:用于统计的列。 -agg:统计别名用于显示统计值的名称,统计函数用于统计数据,常用的统计函数有计数(size)、求和(sum)和均值(mean)。import numpy as np import pandas as pd #分析人的使用左右手跟情商(eq)、智商(iq)的关系 df =pd.DataFrame({"HAND":np.random.randint(0,10,size = 200),"sex":np.random.randint(0,2,size = 200),"iq":np.random.randint(0,100,size =200),"eq":np.random.randint(0,100,size = 200)}) result = df.groupby(by=['iq'])['eq'].agg([ ('数据量',np.size), ('平均值',np.mean), ('最高数据',np.max), ('最低数据',np.min) ]) print(result) ===================================== 数据量 平均值 最高数据 最低数据 iq 0 2 28.000000 36 20 2 3 52.666667 89 10 4 2 56.000000 88 24 5 1 58.000000 58 58 6 1 34.000000 34 34 .. ... ... ... ... 95 2 68.000000 79 57 96 3 14.333333 39 1 97 2 13.500000 18 9 98 3 19.000000 28 3 99 1 10.000000 10 10
1.3,分布分析
分布分析是指根据分析的目的,将定量数据进行等距或不等距的分组,从而研究各组分布规律的一种分析方法。
pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False) -x:进行划分的一维数组。 -bins:取整数值,表示将x划分为多少个等距的区间。取序列值,表示将x划分在指定序列中,若不在该序列中,则是NaN。 -right:分组时是否包含右端点,默认为True(包含)。 -labels:分组时是否用自定义标签来代替返回的bins,可选项,默认为NULL。 -precision:表示精度,默认为3。 -include_lowest:分组时是否包含左端点,默认为False(不包含)。import numpy as np import pandas as pd #分析人的使用左右手跟情商(eq)、智商(iq)的关系 df =pd.DataFrame({"HAND":np.random.randint(0,10,size = 200),"sex":np.random.randint(0,2,size = 200),"iq":np.random.randint(0,100,size =200),"eq":np.random.randint(0,100,size = 200)}) iq_level = [0,20,40,60,80,100] iq_level_label=['0~20','20~40','40~60','60~80','80~100'] df['iq分层']=pd.cut(df.iq, iq_level, labels=iq_level_label) #分组统计人数,平均月薪、最高月薪和最低月薪 result = df.groupby(by=['iq分层'])['eq'].agg({ ('数据量', np.size), ('平均值', np.mean), ('最高数据', np.max), ('最低数据', np.min) }) print(result) ================================== 最高数据 平均值 数据量 最低数据 iq分层 0~20 99 49.568182 44 0 20~40 99 55.658537 41 5 40~60 99 35.926829 41 0 60~80 99 60.243243 37 2 80~100 97 49.833333 36 1
1.4,交叉分析
(1)透视表:交叉分析有数据透视表和交叉表两种,其中,pivot_table()函数返回值是数据透视表的结果,该函数相当于Excel中的数据透视表功能。
pandas.pivot_table(data, values, index, columns, aggfunc, fill_value, margins) 或 dataframe.pivot_table(values, index, columns, aggfunc, fill_value, margin) -data:要应用透视表的数据框。 -values:待聚合的列的名称,默认聚合所有数据列。 -index:用于分组的列名或其他分组键,出现在结果透视表的列。 -columns:用于分组的列名或其他分组键,出现在结构透视表的行。 -aggfunc:聚合函数或函数列表,默认为'mean',可以是任何对groupby有效的函数。 -fill_value:用于替换结果表中的缺失值。 -margins:添加行/列小计和总计,默认为False。import numpy as np import pandas as pd #分析人的使用左右手跟情商(eq)、智商(iq)的关系 df =pd.DataFrame({"HAND":np.random.randint(0,10,size = 200),"sex":np.random.randint(0,2,size = 200),"iq":np.random.randint(0,100,size =200),"eq":np.random.randint(0,100,size = 200)}) iq_level = [0,20,40,60,80,100] iq_level_label=['0~20','20~40','40~60','60~80','80~100'] df['iq分层']=pd.cut(df.iq, iq_level, labels=iq_level_label) #分组统计人数,平均月薪、最高月薪和最低月薪 result = df.pivot_table( values=['eq'], index=['iq分层'], columns=['sex'], aggfunc=[np.size,np.mean] ) print(result) ========================== size mean eq eq sex 0 1 0 1 iq分层 0~20 17 14 41.470588 50.714286 20~40 22 18 47.136364 62.000000 40~60 22 25 57.181818 47.320000 60~80 21 19 42.190476 51.578947 80~100 20 18 50.450000 61.222222
(2)交叉表:交叉表是一种用于计算分组频率的特殊透视表。
pandas.crosstab(index, columns, value=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False) -index:接受array、Series或数组列表,表示要在行中分组的值。 -columns:接收array、Series或数组列表,表示要在列中分组的值。 -values:接array,可选。根据因素聚合的值数组。需要指定“aggfunc”。 -rownames:接收sequence,默认为None。如果传递,则必须匹配传递的行数组。 -colnames:接收sequence,默认为None。如果传递,则必须匹配传递的列数组。 -aggfunc:聚合函数或函数列表。 -margins:添加行/列小计和总计,默认为False。 -margins_name:接收string,默认为'All',表示包含总计的行/列的名称。import numpy as np import pandas as pd #分析人的使用左右手跟情商(eq)、智商(iq)的关系 df =pd.DataFrame({"HAND":np.random.randint(0,10,size = 200),"sex":np.random.randint(0,2,size = 200),"iq":np.random.randint(0,100,size =200),"eq":np.random.randint(0,100,size = 200)}) result = pd.crosstab(df['eq'],df['sex'],margins=True) print(result) ========================================= sex 0 1 All eq 0 1 2 3 1 0 2 2 2 0 1 1 3 1 3 4 4 0 1 1 .. .. ... ... 96 1 0 1 97 0 1 1 98 1 2 3 99 1 0 1 All 87 113 200
1.5,结构分析
结构分析是在分组和交叉的基础上,计算各组成部分所占的比例,进而分析总体的内部特征的一种分析方法。
数据框的外运算函数 数据框的内部运算函数 运算 说明 运算 说明 add 加 sum 求和 sub 减 mean 均值 multiply 乘 var 方差 div 除 sd 标准差 import numpy as np import pandas as pd # 分析人的使用左右手跟情商(eq)、智商(iq)的关系 df = pd.DataFrame({"HAND": np.random.randint(0, 10, size=200), "sex": np.random.randint(0, 2, size=200), "iq": np.random.randint(0, 100, size=200), "eq": np.random.randint(0, 100, size=200)}) iq_level = [0, 20, 40, 60, 80, 100] iq_level_label = ['0~20', '20~40', '40~60', '60~80', '80~100'] df['iq分层'] = pd.cut(df.iq, iq_level, labels=iq_level_label) # 分组统计人数,平均月薪、最高月薪和最低月薪 result = df.pivot_table( values=['eq'], index=['iq分层'], columns=['sex'], aggfunc=[np.size] ) print(result) print(result.sum()) print(result.div(result.sum(axis=0), axis=1)) #div的第一个参数是除法的分母,意思是按行把数据除以该列的总和。 ========================================================= size eq sex 0 1 iq分层 0~20 20 19 20~40 16 18 40~60 21 22 60~80 17 26 80~100 22 17 sex size eq 0 96 1 102 dtype: int64 size eq sex 0 1 iq分层 0~20 0.208333 0.186275 20~40 0.166667 0.176471 40~60 0.218750 0.215686 60~80 0.177083 0.254902 80~100 0.229167 0.166667
1.6,相关分析
相关分析用于研究现象之间是否存在某种依存关系,并探讨具有依存关系的现象的相关方向以及相关程度。
线性相关主要采用皮尔逊相关系数r来度量连续变量之间的线性相关强度;r>0,线性正相关;r<0,线性负相关; r=0,表示两个变量之间不存在线性关系,但并不代表两个变量不存在任何关系。
相关系数|r|取值范围 相关程度 0<=|r|<0.3 低度相关 0.3<=|r|<0.8 中度相关 0.8<=|r|<=1 高度相关 相关分析函数包括DataFrame.corr()和Series.corr(other):
- 如果由数据框调用corr()函数,那么将会计算列与列之间的相似度。
- 如果由序列调用corr()方法,那么只是该序列与传入的序列之间的相关度。
函数返回值:
- DataFrame调用:返回DataFrame。
- Series调用:返回一个数值数据,大小为相关度。
import numpy as np import pandas as pd # 分析人的使用左右手跟情商(eq)、智商(iq)的关系 df = pd.DataFrame({"HAND": np.random.randint(0, 10, size=200), "sex": np.random.randint(0, 2, size=200), "iq": np.random.randint(0, 100, size=200), "eq": np.random.randint(0, 100, size=200)}) print(df.iq.corr(df['eq'])) corrResult = df.loc[:,['sex','iq','eq']].corr() print(corrResult) ================================== 0.06637471744421693 sex iq eq sex 1.000000 -0.048324 0.074535 iq -0.048324 1.000000 0.066375 eq 0.074535 0.066375 1.000000
2,数据清洗
2.1,概述
数据属性
- 属性:数据字段,表示数据对象的一个特征。也可以称为:维,特征,变量。
- 存在形式:结构化数据(数据库),非结构化数据(视频,音频,图像,文本),半结构化数据(邮件,HTML,报表)。
- 抽样方法:简单随机抽样,系统抽样法,分层抽样法,整群抽样法,多阶段抽样法。
数据质量分析:数据几乎没有完美的。事实上,大多数数据都包含属性值错误、缺失或其他类型的不一致现象。所以在建模前通常需要对数据进行全面的质量分析。数据质量分析同时也是准备数据过程中的重要一环,是数据探索的前提。
主要内容:
- 缺失值:缺失数据包括空值或编码为无意义的值(例如 null)。
- 数据错误:数据错误通常是在输入数据时造成的排字错误。
- 度量标准错误:正确输入但因为不正确的度量标准而导致的错误数据。
- 编码不一致:通常包含非标准度量单位或不一致的值,例如同时使用 M 和 male 表示性别。
2.2,重复值的处理
原始数据集往往会存在着许多重复数据。所谓重复数据是指在数据结构中所有列的内容相同,即行重复。
(1)duplicated()函数:duplicated()函数用于标记Series中的值、DataFrame中的记录行是否重复,重复为True,不重复为False。
pandas.DataFrame.duplicated(subset=None, keep='first') 或 pandas.Series.duplicated(keep='first') -subset:接收string或sequence,用于识别重复的列标签或列标签序列,默认为列标签,默认值为None。 -keep:接收特定string,first表示除了第一个出现外,其余相同的重复项标记为True;last表示除了最后一次出现外,其余相同重复项标记为True;False表示将所有重复项标记为True,默认为first。(2)drop_duplicates()函数:drop_duplicates()函数用于删除Series、DataFrame中重复记录,并返回删除重复后的结果。
pandas.DataFrame.drop_dumplicates(subset=None, keep='first', inplace=False) 或 pandas.Series.drop_duplicates(keep='first', inplace=False) -subset:接收string或sequence,仅考虑用于标识重复项的某些列,默认情况下使用所有列,默认值为None。 -keep:接收待定string,first表示删除重复项并保留第一次出现的项;last表示除了最后一项外,删除重复项;默认为first。 -inplace:接收boolean,True表示直接修改原对象,False表示创建一个副本,修改副本,原对象不变,默认为False。# 分析人的使用左右手跟情商(eq)、智商(iq)的关系 df = pd.DataFrame({"sex": np.random.randint(0, 2, size=50),"iq": np.random.randint(0, 2, size=50), "eq": np.random.randint(0, 2, size=50)}) print(df.duplicated()) print(df.drop_duplicates()) ======================================== 0 False 1 False 2 True 3 False 4 True ...... 48 True 49 True dtype: bool sex iq eq 0 1 1 1 1 0 1 1 3 1 0 1 5 1 0 0 8 1 1 0 13 0 0 0 14 0 1 0 19 0 0 1
2.3,缺失值处理
(1)判断缺失值的函数
- isnull()函数:isnull(obj)。其中,参数obj表示接收标量或数组,用于检查空值或缺失值的对象;如果有空值或缺失值则返回True,否则返回False。
- notnull()函数:notnull(obj)。其中,参数obj接收ndarray或对象值,用于检查不为空值或缺失值的对象了如果有空值或缺失值则返回False,否则返回True。
(2)处理缺失值的方法
- 删除含有缺失值的记录:如果数据集的样本很大,并且在删除含有缺失值的记录后,不会影响分析结果的客观性和准确性时,一般使用dropna()函数直接将空值或缺失值的数据删除。
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) -axis:指定删除方向,当axis=0按行删除,axis=1按列删除,默认为0。 -how:取值为“all”表示这一行或列的元素全部缺失(为NaN)才删除这一行或列;取值为“any”表示这一行或这一列只要有缺失值,就删除这一行。 -thresh:一行或一列中至少出现了thresh个才删除。 -subset:在某些列的子集中选择出现了缺失值的列删除,不在子集中的含有缺失值的列或行不会被删除。 -inplace:筛选缺失值后,获得的新数据是存为副本还是直接在原数据上进行修改。import numpy as np import pandas as pd df = pd.DataFrame({'name':['燕双嘤',np.NaN,'陈恭鹏'],'sex':['False',np.NAN,'True'],'age':[np.NAN,np.NaN,19]}) print(df) print(df.dropna(how='all')) #所有值全为缺失值才删除 print(df.dropna(thresh=2, axis=0)) #删除至少出现过两个缺失值的行 print(df.dropna(subset=['age'])) #删除subset中指定的列含有缺失值的行 print(df.dropna(axis=1)) #删除含有缺失值的列 print(df.dropna(how='any', inplace=True)) #只要有缺失值就删除,并且直接在原数据上修改 ======================================== name sex age 0 燕双嘤 False NaN 1 NaN NaN NaN 2 陈恭鹏 True 19.0 name sex age 0 燕双嘤 False NaN 2 陈恭鹏 True 19.0 name sex age 0 燕双嘤 False NaN 2 陈恭鹏 True 19.0 name sex age 2 陈恭鹏 True 19.0 Empty DataFrame Columns: [] Index: [0, 1, 2] None
- 进行数据插补:如果数据集的样本比较少或者由于删除含有缺失值的记录,会影响到数据分析结果的客观性和准确性,就需要根据数据插补的方法来选择填充值,然后再使用fillna()函数对空值或缺失值进行填充。
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs) -value:接收常数、dict、Series或DataFrame,表示填充缺失值。 -method:表示填充缺失值的方法,method取值为{‘pad’,‘ffill’,‘backfill’,‘bfill’,None}。pad/ffill:用前一个非缺失值填充该缺失值。backfill/bfill:用下一个非缺失值去填充该缺失值。None:制定一个值去替换该缺失值。 -limit:表示限制填充的个数,如果limit=2,则只填充两个缺失值。 -downcast:默认为None,如果需要将填充的值向下转换为适当的相等数据类型的数值,如将float64数据类型转换为int64数据类型时,则此参数的值为'infer'。在选取填补缺失值的数据时,除了选择常量0或者通过指定method方法选择填充缺失值的数据外,还可根据数据插补方法来选择填充值:
插补方法 描述 均值/中位数/众数插补
根据属性值的类型,用该属性取值的均值/中无数/众数进行插补。 使用固定值 将缺失值属性使用一个常量值替换。 最近临插补 在记录中找到与缺失样本最接近的样本的该属性值插补。 回归方法 对带有缺失值的变量,根据已有的数据和与其有关的其他变量(因变量)的数据建立拟合模型来预测缺失的属性值。 插值法 插值法是利用已知点建立常用的插值函数f(x),未知值由其对应点x求出的函数值f(x)近似代替。 import numpy as np import pandas as pd df = pd.DataFrame({'name': ['燕双嘤', np.NaN, '陈恭鹏'], 'sex': [1, np.NAN, 1], 'age': [21, np.NaN, 19]}) print(df) print(df.isnull().sum()) print(df.fillna(0)) print(df.fillna({'sex': 1, 'age': 20})) print(df.fillna(method='ffill')) print(df.fillna(method='bfill')) print(df['age'].fillna(df['age'].mean())) print(df['age'].fillna(df['age'].median())) print(df.interpolate()) #线性预测填充 ============================================ name sex age 0 燕双嘤 1.0 21.0 1 NaN NaN NaN 2 陈恭鹏 1.0 19.0 name 1 sex 1 age 1 dtype: int64 name sex age 0 燕双嘤 1.0 21.0 1 0 0.0 0.0 2 陈恭鹏 1.0 19.0 name sex age 0 燕双嘤 1.0 21.0 1 NaN 1.0 20.0 2 陈恭鹏 1.0 19.0 name sex age 0 燕双嘤 1.0 21.0 1 燕双嘤 1.0 21.0 2 陈恭鹏 1.0 19.0 name sex age 0 燕双嘤 1.0 21.0 1 陈恭鹏 1.0 19.0 2 陈恭鹏 1.0 19.0 0 21.0 1 20.0 2 19.0 Name: age, dtype: float64 0 21.0 1 20.0 2 19.0 Name: age, dtype: float64 name sex age 0 燕双嘤 1.0 21.0 1 NaN 1.0 20.0 2 陈恭鹏 1.0 19.0
2.4,异常值处理
(1)判别数据集装那个异常值的方法
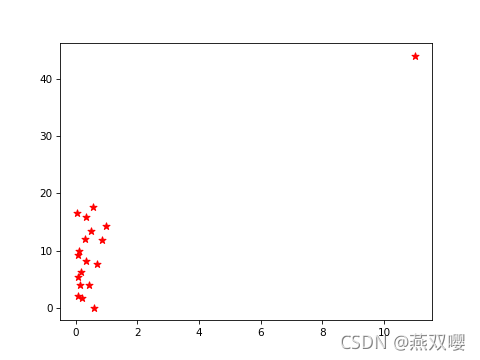
- 散点图分析:通过绘制数据集中某些属性值的散点图,可观察这些属性值中的数据是否存在超出正常范围的离群点,从而发现数据集中的异常值。
- 简单统计分析:对数据集中的属性值进行描述性的统计,从中可发现哪些数据是不合理的。例如,年龄属性值的区间规定为 [0:150],如果数据集样本中的年龄值不在该区间范围内,则表示该样本的年龄属性属于异常值。
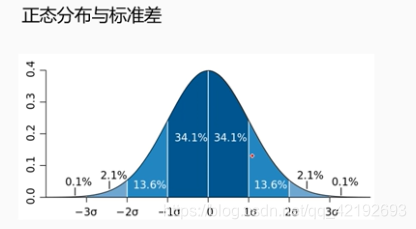
- 3σ 原则:3σ 原则是指当数据服从正态分布时,根据正态分布的定义可知,距离平均值 3σ 之外的概率为 P(|X-μ|>3σ)≤0.003,这属于极小概率事件,在默认情况下,可以认定距离超过平均值 3σ 的样本是不存在的。因此,当样本距离平均值大于 3σ 时,则认定该样本为异常值。
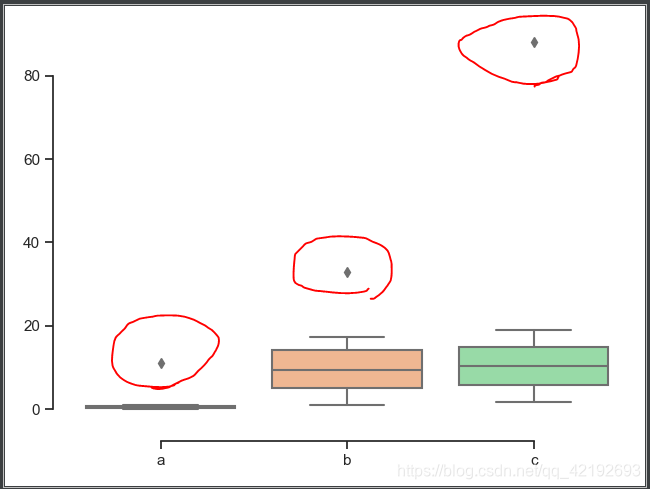
- 箱线图分析:箱线图提供了一个识别异常值的标准,即大于或小于箱线图设定的上下界的数值即为异常值。在箱线图上定义了上四分位和下四分位,上四分位设置为U,表示所有样本中只有 1/4 的数值大于 U;同理,下四分位设置为 L,表示所有样本中只有 1/4 的数值小于 L。同时,设置上四分位与下四分位的插值为 IQR,即 IQR=U-L,那么,上界为 U+1.5IQR,下界为 L-1.5IQR。箱线图在选取异常值方面比较客观,在识别异常值方面有一定的优越性。
(2)异常值的处理方法
- 删除含有异常值的记录。
- 将异常值视为缺失值,按照缺失值的处理方法来处理。
- 用平均值来修正异常值。
- 对异常值不处理。
import numpy as np import pandas as pd import matplotlib.pyplot as plt arr=[[np.random.random(),i+np.random.random()] for i in range(18)] arr.append([11,44]) df=pd.DataFrame(arr,columns=['X','Y']) for i in df.values: plt.scatter(i[0], i[1], s=50, color='red', marker='*') plt.savefig('2d.png', dpi=75)
import seaborn as sns import matplotlib.pyplot as plt import numpy as np import pandas as pd df = pd.DataFrame( [[1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3],[11,44,77] ]) print(df.std()) #求标准差 th1=df.mean()-df.std()*3 #下界 th2=df.mean()+df.std()*3 #上界 #删除没有不在3σ内的元素,然后采用之前处理空值的方法填充元素 df['a']=df[df['a']>th1['a']] #获取大于标准差-3σ的值 df['a']=df[df['a']<th2['a']] #获取小于标准差+3σ的值
import seaborn as sns import matplotlib.pyplot as plt import numpy as np import pandas as pd arr = [[np.random.random(), i + np.random.random(), i + 1 + np.random.random()] for i in range(18)] arr.append([11, 33, 88]) print(arr) df = pd.DataFrame(arr) df.columns = ['a', 'b', 'c'] sns.set(style="ticks", palette="pastel") sns.boxplot(data=df) sns.despine(offset=10, trim=True) plt.show()
3,数据合并
Pandas包的merge、join、concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat方法是对series或dataframe进行行拼接或列拼接。
3.1,按键连接数据
(1)merge()函数:在 pandas 中,通过两个数据集中一个或多个键来合并数据时,可使用 merge() 函数。
pandas.merge(left,right,how='inner',on=None,left_on=None,right_on=None, left_index=False,right_index=False,sort=False,suffixes=('_x','_y'), copy=True, indicator=False) -left:参与合并的左侧 DataFrame; -right:参与合并的右侧 DataFrame; -how:表示连接方式,取值{inner,outer,left,right}: 默认为 inner 内连接,其结果是取两个数据集中键值交集的数据; --outer 外连接,其结果是取两个数据集中键值并集的数据,对不匹配的键所对应的数据用 NaN 填充; --left 左连接,取左侧全部数据,右侧取与左侧相匹配的键所对应的数据,不匹配的键所对应的数据用 NaN 填充; --right 右连接,取右侧全部数据,左侧取与右侧相匹配的键所对应的数据,不匹配的键所对应的数据用 NaN 填充。 --on:表示用于连接的列名,必须同时存在于左右两个 DataFrame 对象中,如果未传递且 left_index 和 right_index 为 False,则 DataFrame 中列的交集将作为连接键; --left_on:表示左侧 DataFarme 中用作连接键的列,可以是列名、索引级名称,也可以是长度等于 DataFrame 长度的数组; --right_on:表示右侧 DataFarme 中用作连接键的列,可以是列名、索引级名称,也可以是长度等于 DataFrame 长度的数组; --left_index:如果为 True,则使用左侧 DataFrame 中的索引(行标签)作为其连接键; --right_index:如果为 True,则使用右侧 DataFrame 中的索引(行标签)作为其连接键; -sort:如果为 True,则将合并的数据进行排序,默认为 False,在大多数情况下设置为 False 可以提高性能; -suffixes:字符串值组成的元组,用于指定当左右 DataFrame 存在相同列名时,在列名后面附加的后缀名称,默认为('_x','_y'),例如,左右两个 DataFrame 对象都有 'data',则结果中就会出现 'data_x' 和 'data_y'; -copy:默认为 True,表示总是将数据复制到数据结构中,大多数情况下设置为 False 可以提高性能; -indicator:默认为 False,如果设置为 True,将显示合并数据中每行来源的信息添加到名为 _merge 的列中输出,例如,只来自左边 (left_only)、两者(both)、只来自右边 (right_only)。import pandas as pd #创建产品信息(info)和产品销售(sale)数据集 info = pd.DataFrame({'产品编号':list('ABCD'),'类型名称':['电视机', '手机','电脑','空调'],'品牌':['格力','康佳', '海信','TCL']},index=range(1001,1005)) info.columns.name='产品信息' info.index.name='编号' print(info) sale = pd.DataFrame({'产品编号':list('ABECDF'),'品牌':['格力', '康佳','海信','TCL','康佳','格力'],'价格' :[3600,1500,4500,2000,2300,3500]},index= range(1001,1007)) sale.columns.name='产品销售' sale.index.name='编号' print(sale) #1.使用默认连接方式连接产品信息和产品销售数据集 print(pd.merge(info,sale)) #2.按照指定"产品编号"列名合并产品信息和产品销售数据集 print(pd.merge(info,sale,on='产品编号')) #3.分别用left、right、outer连接方式连接数据集 print(pd.merge(info,sale,how='left')) print(pd.merge(info,sale,how='right')) print(pd.merge(info,sale,how='outer') ) #4.根据"产品编号"和"品牌"多个键进行连接 print(pd.merge(info,sale,on=['产品编号','品牌'])) #5.对重复的列名进行处理 print(pd.merge(info,sale,on='产品编号',suffixes=('_1','_2'))) #6.将索引作为连接的键 print(pd.merge(info,sale,on=['产品编号','品牌],left_index=True, right_index=True ))
(2)join()函数:除了 merge() 函数外,还可以使用 join() 函数来实现根据特定的列和索引进行合并数据的操作。join() 函数默认是通过 index 进行连接的,也可以通过设置参数“on”来指定连接的列。
left.join(right,on='keys')import numpy as np import pandas as pd left = pd.DataFrame({'one':np.arange(4),'two':list('abcd'), 'key': ['K0', 'K1', 'K0', 'K1']}) right = pd.DataFrame({'three':[4,5],'four': ['e', 'f']}, index=['K0', 'K1']) result = left.join(right, on='key') print(left,'\n',right,'\n',result) ================================== one two key 0 0 a K0 1 1 b K1 2 2 c K0 3 3 d K1 three four K0 4 e K1 5 f one two key three four 0 0 a K0 4 e 1 1 b K1 5 f 2 2 c K0 4 e 3 3 d K1 5 f
3.2,沿轴连接数据
在 pandas 中,利用 concat() 函数可以沿轴对数据进行简单的连接。concat 方法相当于数据库中的全连接 (Union All),可以指定按某个轴进行连接,也可以指定 join 连接的方式(只有 outer、inner 两种)。
与数据库不同的是 concat 方法不能去重,如要实现去重的效果,可以使用 drop_duplicates 方法。轴向连接数据就是单纯地将两个表拼接,这个过程也被称作连接(concatenation)、绑定(binding)或堆叠(stacking)。
pandas.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False, keys=None,levels=None,names=None,verify_integrity=False,copy=Tru,esort= False) -objs:需要连接的对象集合,一般是 Series、DataFrame、list 或 dict; -axis:表示数据合并的轴方向,默认为 0,axis=0 表示纵向,axis=1 表示横向; -join:表示连接方式,取值{outer,inner},默认为 outer 外连接,其结果是取所连接的数据集中键值并集的数据,取值为 inner 内连接,其结果是取所连接的数据集中键值交集的数据; -join_axes:接收列表,表示自定义索引对象的列表; -ignore_index:接收 boolean 值,默认为 False,如果为 True,请不要使用串联轴上的索引值,生成的轴将被标记为 0,…,n-1; -keys:接收序列,默认值为 None,使用传递的键作为最外层构建层次索引,如果为多索引,应使用元组; -levels:接收列表的序列,默认为 None,用于构建 MultiIndex(层次索引)的特定级别; -names:接收列表,默认为 None,表示 MultiIndex(层次索引)的级别的名称; -verify_integrity:接收 boolean 值,默认为 False,检查新连接的轴是否包含重复项; -copy:接收 boolean值,默认为 True,如果为 False,表示不复制数据; -sort:如果为 True,则将合并的数据进行排序,默认为 False,但在横向外连接或者 ignore_index=True 时要设置此参数。concat() 函数具有以下特点:
- 当 concat() 函数作用于 Series 时,如果 axis=0,类似于 union(数据联合);如果 axis=1,则组成一个 DataFrame,索引是 union 后的结果,列是类似 join 后的结果;
- 通过参数 join_axes=[] 指定自定义索引;
- 通过参数 keys=[] 创建层次化索引。利用 keys 参数可以为合并后的数据集增加一个键,通过该键指明合并数据集中不同的数据来源;
- 通过参数 ignore_index=True 可重建索引。利用该参数可以实现将两个不同的列的 DataFrame 合并,其中无效的值用 NaN 表示。
# -*- coding: utf-8 -*- import numpy as np import pandas as pd #定义3个Series s1 = pd.Series([0, 1, 2], index=['a', 'b', 'c']) s2 = pd.Series([3, 4, 5, 6], index=['d', 'e', 'f', 'g']) s3 = pd.Series([7, 8, 9], index=['h', 'i', 'j']) print('将s1,s2,s3纵向外连接') result = pd.concat([s1, s2, s3]) print(result) print('将s1,s2,s3横向外连接') result =pd.concat([s1, s2, s3], axis=1,sort=False) print(result) print('将s1*2,s3纵向外连接') s4 = pd.concat([s1 * 2, s3]) print(s4) print('将s1,s4横向外连接') result = pd.concat([s1, s4], axis=1,sort=False) print(result) print('将s1,s4横向内连接') result = pd.concat([s1, s4], axis=1, join='inner') print(result) print('将s1,s4横向外连接,自定义索引') result = pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']], sort=False) print(result) print('将s1,s2,s3纵向外连接,设置层次索引') result = pd.concat([s1, s1, s3], keys=['one', 'two', 'three']) print(result) print('将s1,s2,s3横向外连接,设置层次索引') result = pd.concat([s1, s2, s3], axis=1, keys=['one', 'two', 'three'], sort=False) print(result) #定义2个DataFrame df1 = pd.DataFrame(np.arange(6).reshape(3, 2), index=['a', 'b', 'c'], columns=['one', 'two']) df2 = pd.DataFrame(5 + np.arange(4).reshape(2, 2), index=['a', 'c'], columns=['three', 'four']) print('将df1,df2横向外连接,设置层次索引') result = pd.concat([df1, df2], axis=1, keys=['level1', 'level2'], sort=False) print(result) print('使用字典设置层次索引,横向外连接') result = pd.concat({'level1': df1, 'level2': df2}, axis=1, sort=False) print(result) print('将df1,df2横向外连接,设置层次索引和设置层次索引的级别名称') result = pd.concat([df1, df2], axis=1, keys=['level1', 'level2'], names=['upper', 'lower'],sort=False) print(result) #将两个不相同的列的数据框合并 df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd']) df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a']) print('df1,df2纵向外连接,忽略原index,重建索引') print(pd.concat([df1, df2], ignore_index=True,sort=Fals
append()函数:append() 函数是 concat() 函数的简略形式,但是 append() 函数只能在 axis=0 上进行数据合并。
left.append(right) 或 left.append(right,ignore_index=True)该函数的功能为:将 left 指定数据集与 right 指定数据集进行纵向合并。其中,DataFrame 与 Series 进行合并时,需要使用参数 ignore_index=True。
import numpy as np import pandas as pd left = pd.DataFrame({'one':np.arange(4),'two':list('abcd')} right = pd.DataFrame({'three':[4,5],'four': ['e', 'f']}) s1 = pd.Series([0, 1, 2], index=['a', 'b', 'c']) result = left.append(right,sort=False) result1 = left.append(s1,ignore_index=True) print('左边数据:','\n',left,'\n','右边数据:','\n', right,'\n','合并数据:','\n',result) print('左边数据:','\n',left,'\n','右边数据:','\n', s1,'\n','合并数据:','\n',result1) ===================================================== 左边数据: one two 0 0 a 1 1 b 2 2 c 3 3 d 右边数据: a 0 b 1 c 2 dtype: int64 合并数据: one two a b c 0 0.0 a NaN NaN NaN 1 1.0 b NaN NaN NaN 2 2.0 c NaN NaN NaN 3 3.0 d NaN NaN NaN 4 NaN NaN 0.0 1.0 2.0


















 5403
5403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











