







**
文件如下所示:
**
根据第一列第四个数字大小进行排序(请注意“汉字”顺序需要与前面的视频顺序对应)
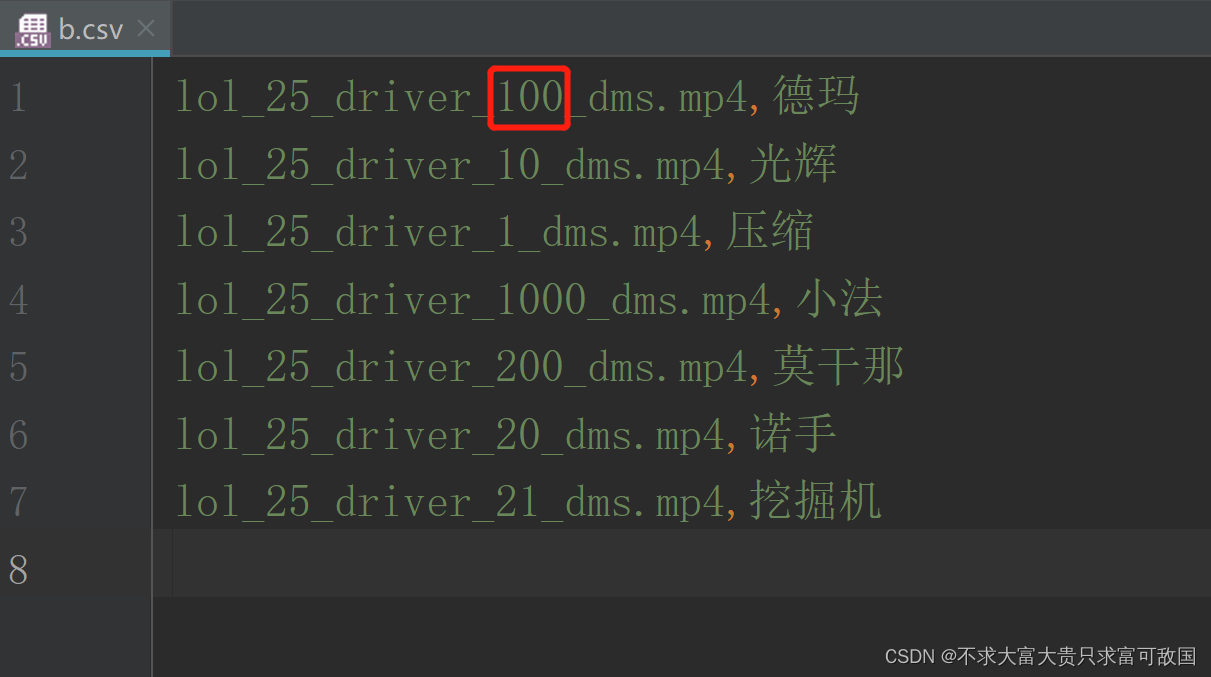
**
解决思路:
**
1、把数据提取出来
2、把第一列split成列表
3、zip组合:拆分后的列表与第二列,由于key是可哈希的且不能是列表,而value是可以修改,所以把第一列当value,第二列当key, dict转换为字典
4、依据value,使用sorted排序
5、通过for:循环排序后的结果,把拆分的数据join组合后,分别追加到两个空列表,再次zip即可(为了把两列的顺序调换回来)(可能有人会有疑问:为什么不采用“键值对”反转的形式,而搞得那么麻烦,在第二步骤也讲了,字典的key不能是列表,所以不能通过反转键值对解决)
**
具体代码如下:
**
import os
import pandas as pd
path=r"C:\Users\jam96\PycharmProjects\all_module\pandas_test\a"
dir_path=os.path.dirname(os.path.abspath(__file__))
result_path=os.path.join(dir_path,"data")
if not os.path.exists(result_path):
os.mkdir(result_path)
files=os.listdir(path)
print(files)
num=1
for i in files:
res=pd.read_csv(filepath_or_buffer=os.path.join(path,i),header=None)
a=res.values[:,0]
b=res.values[:,1]
d=[]
for i in a:
c=i.split("_")
d.append(c)
new=dict(zip(b,d))
#sorted返回的是列表
new1=sorted(new.items(),key=lambda x:int(x[1][3]))
k=[]
j=[]
for i in new1:
k.append(i[0])
j.append("_" .join(i[1]))
result=zip(j,k)
pd1=pd.DataFrame(data=result)
pd1.to_csv(result_path+os.path.sep+"C00"+str(num)+".csv",index=False,header=None)
num+=1
运行结果如下:
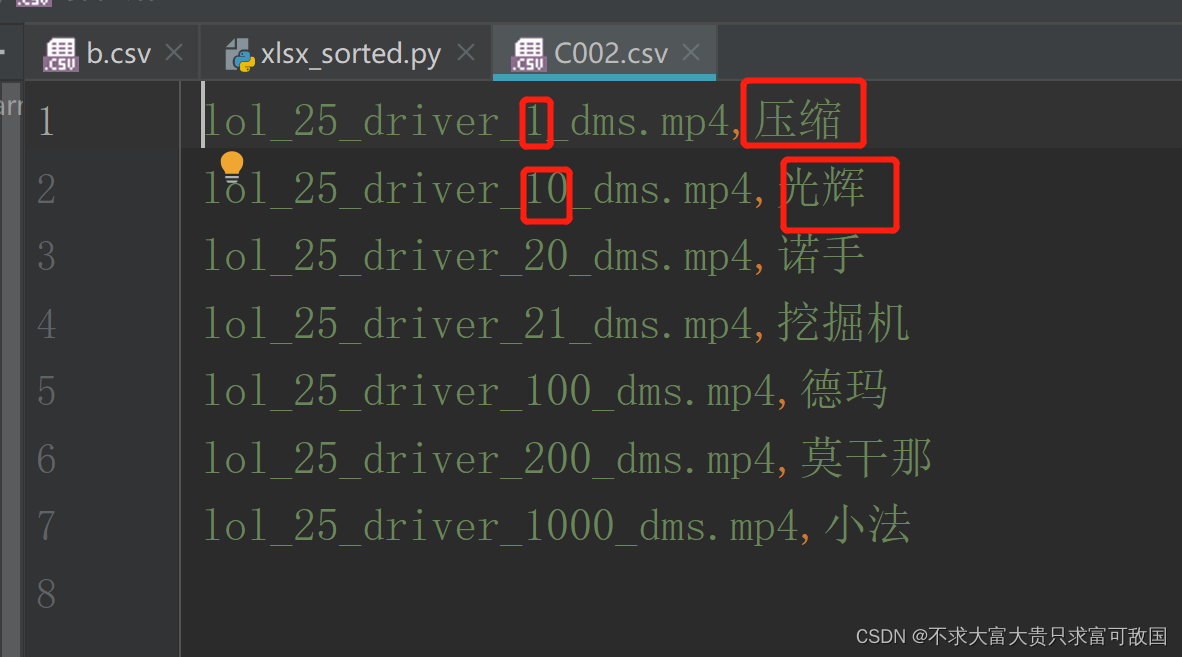
优化代码
后来发现以上代码写的冗余,其实没必要那么复杂,另一方面是由于对字典的掌握熟练度不够,优化后的代码如下:
import pandas as pd
#csv文件路径
path=r"D:\TestSet\csv\dms\abc.csv"
#读csv文件
res=pd.read_csv(path,encoding="gbk",header=None)
#得到第一列与第二列
a=res.values[:,0]
b=res.values[:,1]
#把第一列的数据与第二列结合起来
c=dict(zip(a,b))
#根据key的第四项大小进行排序,请注意使用了“int”对结果进行了强制转换为整型
d=sorted(c.items(),key=lambda x:int(x[0].split("_")[3]))
#把排序后的结果再次写入新的csv
e=pd.DataFrame(data=d)
e.to_csv(path_or_buf=r"C:\Users\xdjiang6\PycharmProjects\日志结果批量修改标注集\data\a.csv",index=False,header=None)















 2671
2671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









