






B站UP主“我是土堆”视频内容
Transforms主要是对数据进行特定的变化

Transforms的结构及其用法
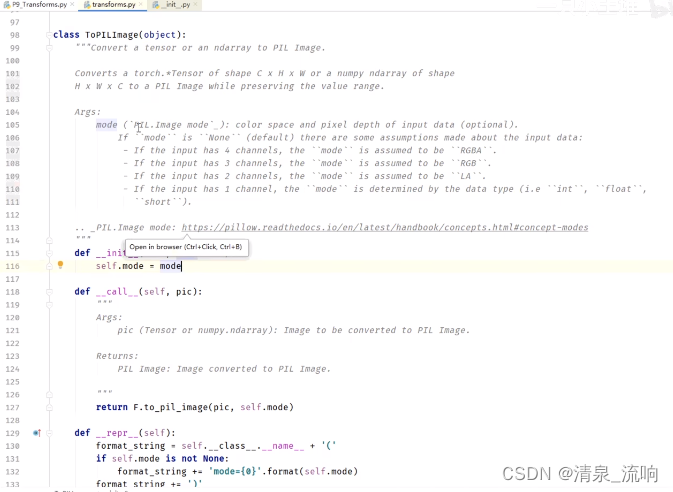
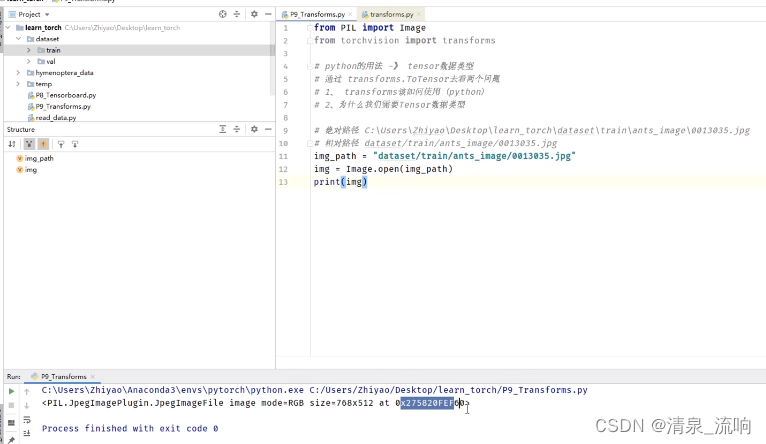
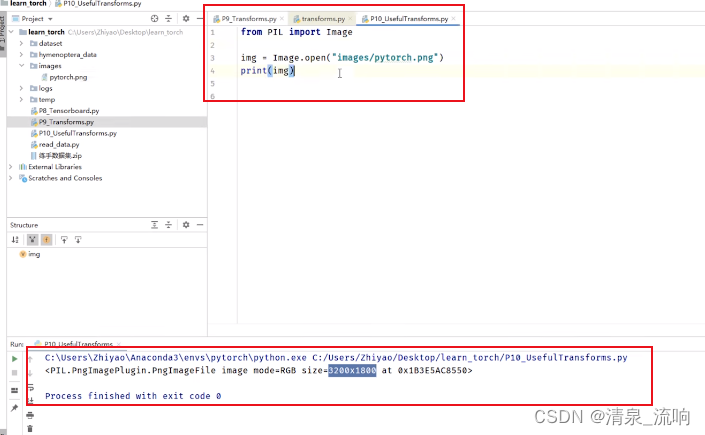
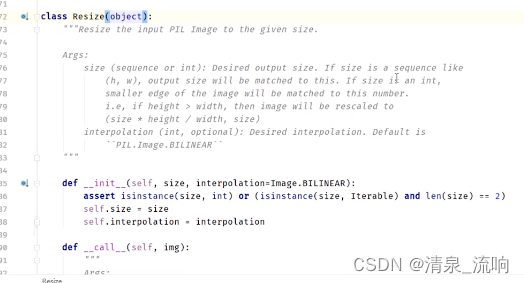
在pycharm输入from torchvision import transforms,按住ctrl然后鼠标点击transforms,可以查看transforms的源代码,如下图所示
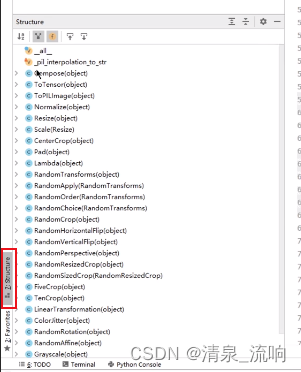
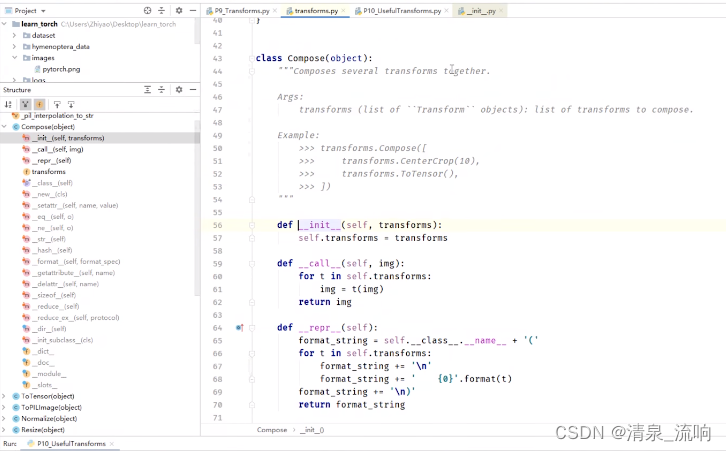
点击structure 得到下图
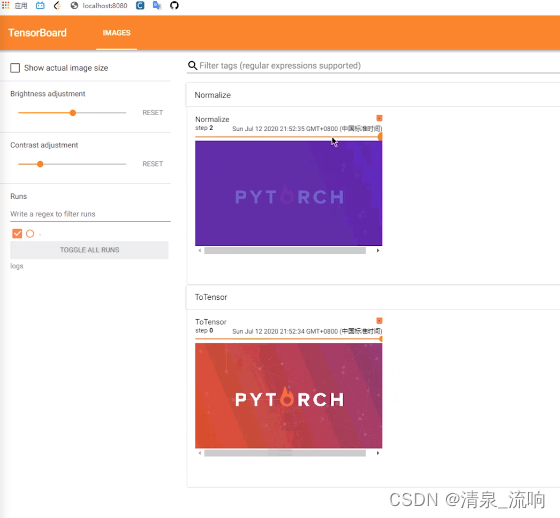
ToTensor是把一个图片或者numpy.ndarray转换成tensor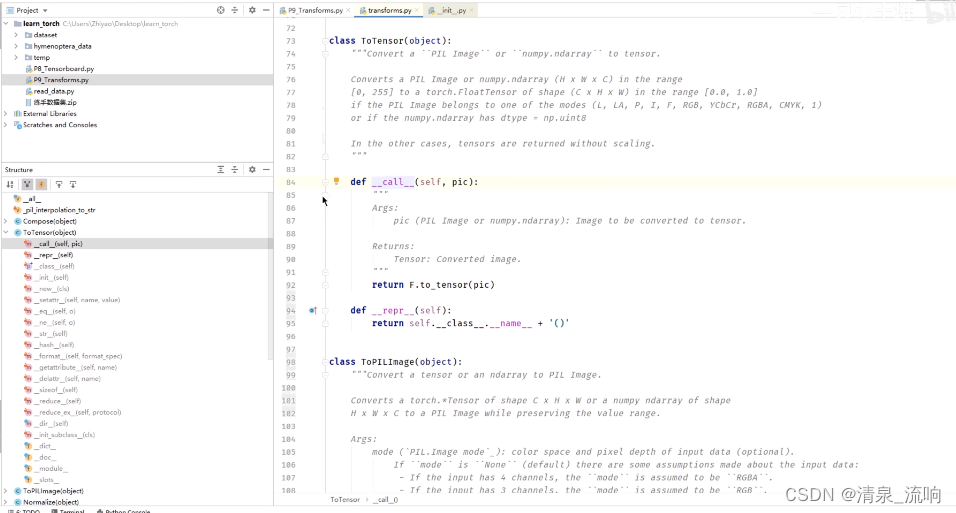
实战练习一:
#python的用法-》tensor数据类型
#通过 transforms.ToTensor去看两个问题
#1、transforms该如何使用(python)
#2、为什么我们需要Tensor数据类型
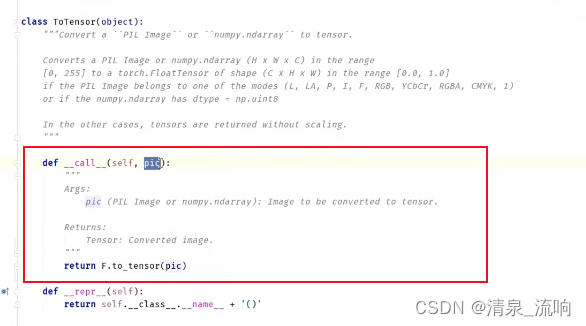
ToTensor里面的__call__(self,pic)含义,输入参数pic表示当要使用时传入一个图片(PIL Image)或者numpy.ndarray,然后它会返回一个tensor类型的数据
ctrl+P可以查看需要传入的参数是什么,如下图所示

tensor数据类型可以理解为包装了我们神经网络所需要的一些参数,方便神经网络的训练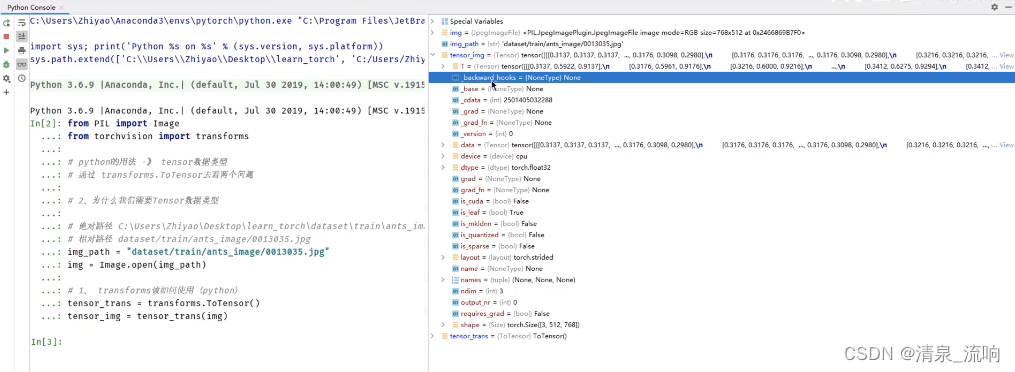
tensor数据类型可以理解为包装了我们神经网络所需要的一些参数
代码如下:
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from PIL import Image
# 绝对路径:C:\Users\23620\Desktop\TD_torch\data\train\ants_image\0013035.jpg
# 相对路径:data/train/ants_image/0013035.jpg
img_path = "data/train/ants_image/0013035.jpg"
img = Image.open(img_path)
writer = SummaryWriter("logs")
tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img)
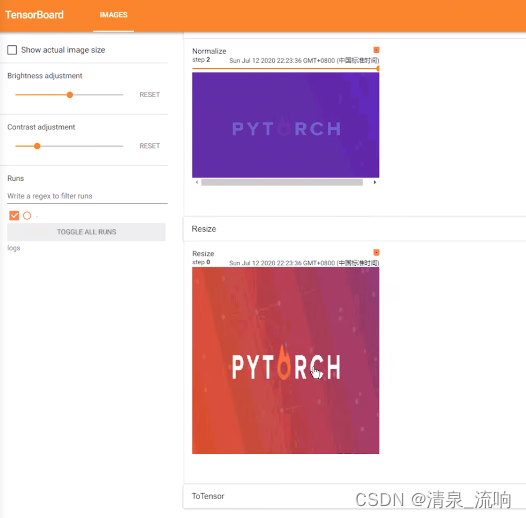
writer.add_image("Tensor_img",tensor_img)
writer.close()
实战练习二:
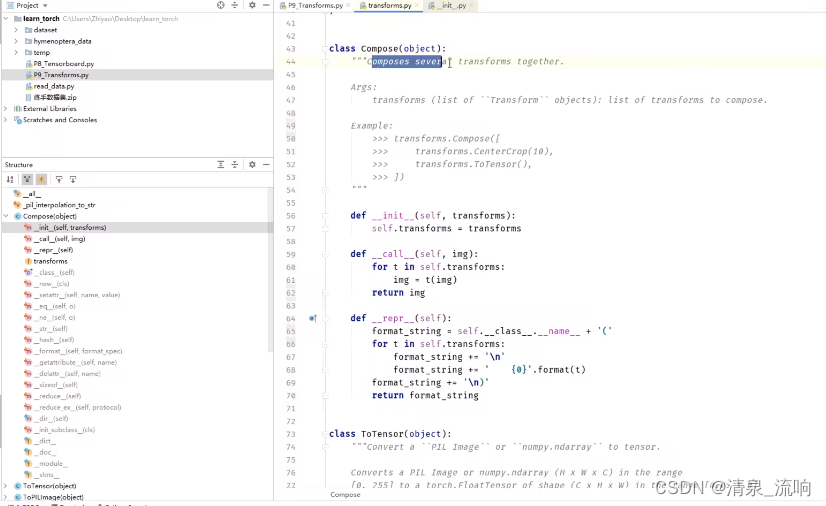
compose是把几种不同的transforms组合在一起,下面例子表示输入一张图片,先经过中心裁剪,然后把裁剪后的数据转换成tensor数据类型
Example:
>>> transforms.Compose([
>>> transforms.CenterCrop(10),
>>> transforms.ToTensor(),
>>> ])

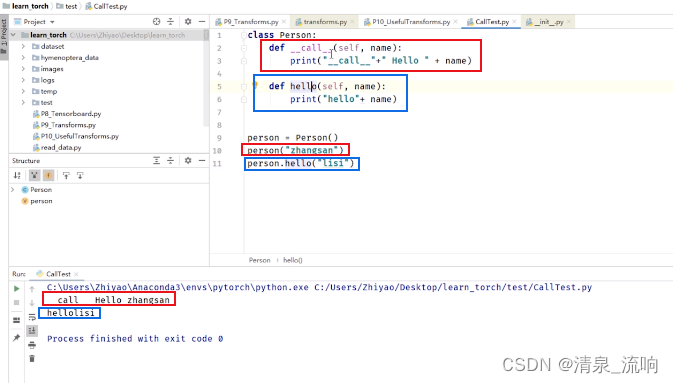
如果一个类定义了内置__call__的话,直接一个对象给输入参数便可


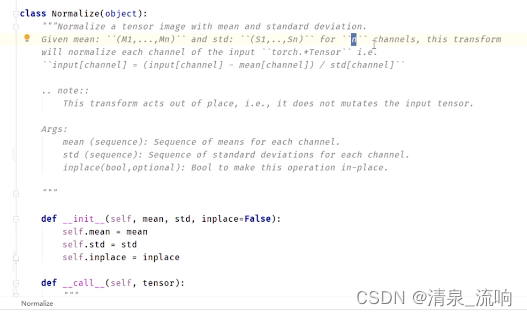
normalize是归一化处理,需要输入每一个通道的均值和标准差,例如,输入的图片是RGB三个通道,则均值和标准差应该为[mean,mean,mean],[std,std,std]

resize可以修改图片的尺寸大小


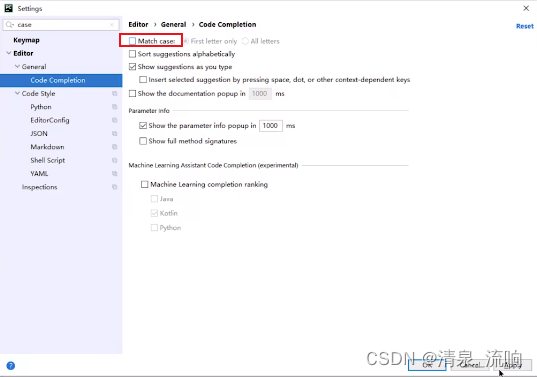
设置大小写字母都能有提示的方法:file->setting


compose是把几种不同的transforms组合在一起,

程序如下:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("images/24335309_c5ea483bb8.jpg")
print(img)
#ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor",img_tensor)
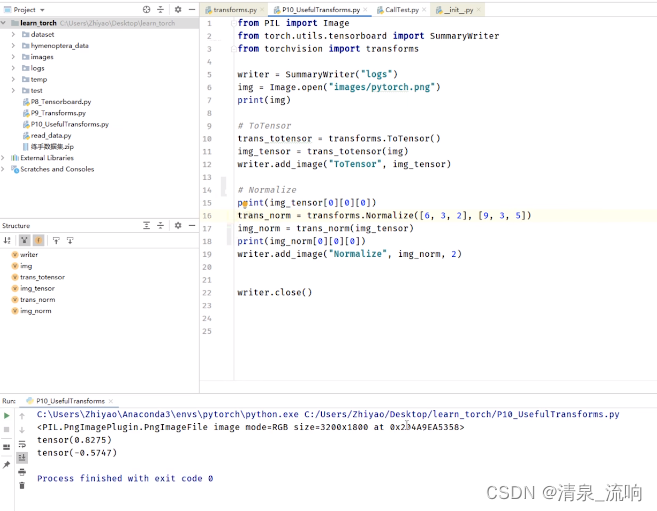
#Normalize
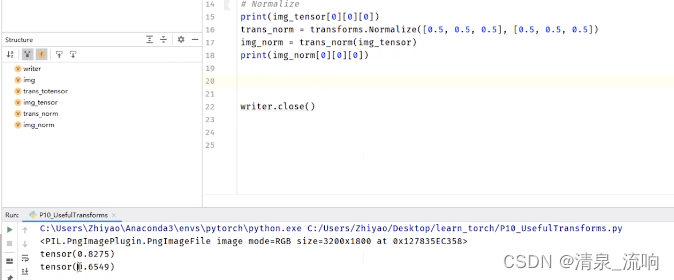
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([1,3,5],[3,2,1])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,1)
#resize
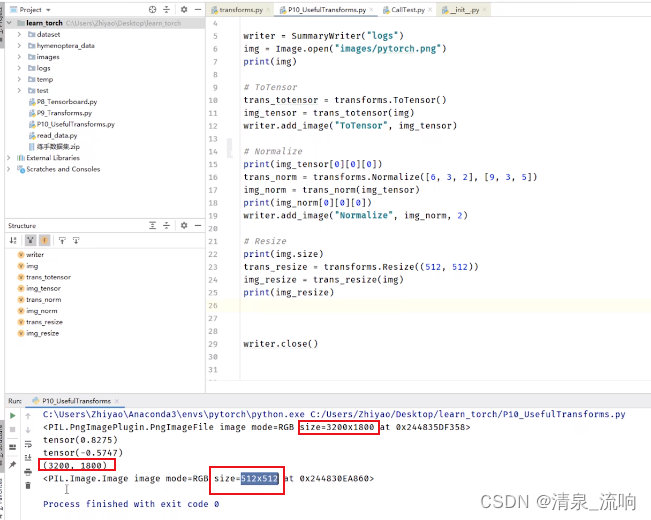
print(img.size)
trans_resize = transforms.Resize((512,512))
#img PIL->resize->img_resize PIL
img_resize = trans_resize(img)
#img_resize PIL->totensor->img_reszie tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize",img_resize,0)
print(img_resize)
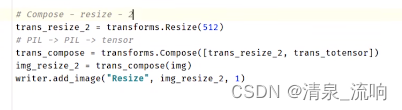
#Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize",img_resize_2,1)
writer.close()














 1591
1591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









