







Python中的multiprocess提供了Process类,实现进程相关的功能。但是它基于fork机制,因此不被windows平台支持。想要在windows中运行,必须使用if __name__ == '__main__':的方式,显然这只能用于调试和学习,不能用于实际环境。
import os
import multiprocessing
def foo(i):
# 同样的参数传递方法
print("这里是 ", multiprocessing.current_process().name)
print('模块名称:', __name__)
print('父进程 id:', os.getppid()) # 获取父进程id
print('当前子进程 id:', os.getpid()) # 获取自己的进程id
print('------------------------')
if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=foo, args=(i,))
p.start()1. 进程间的数据共享
在Linux中,每个子进程的数据都是由父进程提供的,每启动一个子进程就从父进程克隆一份数据。
创建一个进程需要非常大的开销,每个进程都有自己独立的数据空间,不同进程之间通常是不能共享数据的,要想共享数据,一般通过中间件来实现。
想要在进程之间进行数据共享可以使用Queues、Array和Manager这三个multiprocess模块提供的类。
1.1 使用Array共享数据
Array类在实例化的时候必须指定数组的数据类型和数组的大小,类似temp = Array('i', 5)。括号内的“i”表示它内部的元素全部是int类型,而不是指字符“i”,数组内的元素可以预先指定,也可以只指定数组的长度。
'c': ctypes.c_char, 'u': ctypes.c_wchar,
'b': ctypes.c_byte, 'B': ctypes.c_ubyte,
'h': ctypes.c_short, 'H': ctypes.c_ushort,
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_doublefrom multiprocessing import Process
from multiprocessing import Array
def func(i,temp):
temp[0] += 100
print("进程%s " % i, ' 修改数组第一个元素后----->', temp[0])
if __name__ == '__main__':
temp = Array('i', [1, 2, 3, 4])
for i in range(10):
p = Process(target=func, args=(i, temp))
p.start()1.2 使用Manager共享数据
Manager()返回的manager对象提供一个服务进程,使得其他进程可以通过代理的方式操作Python对象。manager对象支持 list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore,
Condition, Event, Barrier, Queue, Value ,Array等多种格式。
from multiprocessing import Process
from multiprocessing import Manager
def func(i, dic):
dic["num"] = 100+i
print(dic.items())
if __name__ == '__main__':
dic = Manager().dict()
for i in range(10):
p = Process(target=func, args=(i, dic))
p.start()
p.join()1.3 使用queues的Queue类共享数据
multiprocessing是一个包,它内部又一个queues模块,提供了一个Queue队列类,可以实现进程间的数据共享,如下例所示:
import multiprocessing
from multiprocessing import Process
from multiprocessing import queues
def func(i, q):
ret = q.get()
print("进程%s从队列里获取了一个%s,然后又向队列里放入了一个%s" % (i, ret, i))
q.put(i)
if __name__ == "__main__":
lis = queues.Queue(20, ctx=multiprocessing)
lis.put(0)
for i in range(10):
p = Process(target=func, args=(i, lis,))
p.start()1.4 使用Pipe()类共享数据
multiprocessing.Pipe()即管道模式,调用Pipe()返回管道的两端的Connection。Pipe仅仅适用于只有两个进程一读一写的单双工情况,也就是说信息是只向一个方向流动。例如电视、广播,看电视的人只能看,电视台是能播送电视节目。
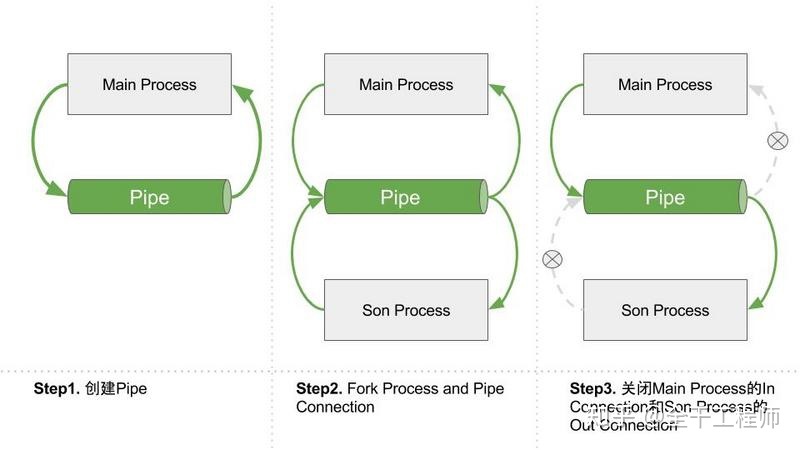
三种通信方式对比
-
共享内存
数据操作最快,因为是直接在内存层面操作,省去中间的拷贝工作。但是共享内存只能在单机上运行,且只能操作基础数据格式,无法直接共享复杂对象。 -
管道和队列传递数据没有共享内存快,且每次传递的数据大小受限。
但是使用队列可以在多个进程间传递,可以在不同主机上的进程间共享,以实现分布式。
匿名管道则只能在父子进程间共享,命名管道可在同一台计算机的不同进程之间或在跨越一个网络的不同计算机的进程间共享。
2. 进程锁
为了防止和多线程一样的出现数据抢夺和脏数据的问题,同样需要设置进程锁。与threading类似,在multiprocessing里也有同名的锁类RLock,Lock,Event,Condition和 Semaphore,连用法都是一样样的,这一点非常友好!
from multiprocessing import Process
from multiprocessing import Array
from multiprocessing import RLock, Lock, Event, Condition, Semaphore
import time
def func(i,lis,lc):
lc.acquire()
lis[0] = lis[0] - 1
time.sleep(1)
print('say hi', lis[0])
lc.release()
if __name__ == "__main__":
array = Array('i', 1)
array[0] = 10
lock = RLock()
for i in range(10):
p = Process(target=func, args=(i, array, lock))
p.start()3. 进程池Pool类
进程启动的开销比较大,过多的创建新进程会消耗大量的内存空间。仿照线程池的做法,我们可以使用进程池控制内存开销。
比较幸运的是,Python给我们内置了一个进程池,不需要像线程池那样要自己写,你只需要简单的from multiprocessing import Pool导入就行。进程池内部维护了一个进程序列,需要时就去进程池中拿取一个进程,如果进程池序列中没有可供使用的进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池中常用的方法:
- apply() 同步执行(串行)
- apply_async() 异步执行(并行)
- terminate() 立刻关闭进程池
- join() 主进程等待所有子进程执行完毕。必须在close或terminate()之后。
- close() 等待所有进程结束后,才关闭进程池。
from multiprocessing import Pool
import time
def func(args):
time.sleep(1)
print("正在执行进程 ", args)
if __name__ == '__main__':
p = Pool(5) # 创建一个包含5个进程的进程池
for i in range(30):
p.apply_async(func=func, args=(i,))
p.close() # 等子进程执行完毕后关闭进程池
# time.sleep(2)
# p.terminate() # 立刻关闭进程池
p.join()参考地址:python 多进程multiprocess - 刘江的python教程
Python实现多进程间通信的方法总结_tyhj_sf的博客-CSDN博客_python 进程之间如何进行通信















 168
168











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









