






1 多线程与多进程
Python中比较常见的并发方式主要有两种:多线程和多进程。
1-1 多线程
多线程即在一个进程中启动多个线程执行任务。一般来说使用多线程可以达到并行的目的,但由于Python中使用了全局解释锁GIL的概念,导致Python中的多线程并不是并行执行,而是“交替执行”。类似于下图。
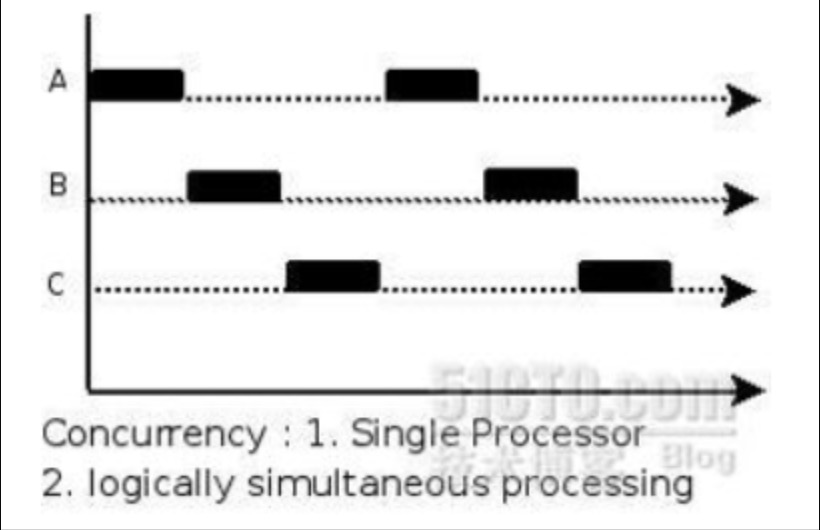
所以Python中的多线程适合IO密集型任务,而不适合计算密集型任务。Python提供两组多线程接口,一是thread模块_thread,提供低等级接口。二是threading模块,提供更容易使用的基于对象的接口,可以继承Thread对象来实现线程,此外其还提供了其它线程相关的对象,例如Timer,Lock等。
1-2 多进程
由于Python中GIL的原因,对于计算密集型任务,Python下比较好的并行方式是使用多进程,这样可以非常有效的使用CPU资源。当然同一时间执行的进程数量取决你电脑的CPU核心数。在支持多任务操作系统中,一个应用程序会被分解成多个独立运行的较小的程序。操作系统会将这些线程分配到多核处理器,以提升系统性能。执行过程如下图。每个进程都拥有自己的地址空间、内存、文件描述符和其他系统资源。多进程的好处在于可以使程序并行执行,从而提高程序的运行效率。

如果每个子进程执行需要消耗的时间非常短(执行+1操作等),这不必使用多进程,因为进程的启动关闭也会耗费资源。当然使用多进程往往是用来处理CPU密集型(科学计算)的需求,如果是IO密集型(文件读取,爬虫等)则可以使用多线程去处理。
2 多进程实现
2-1 multiprocessing
2-1-1 Process
multiprocessing模块提供了一个Process类,可以用来创建和管理进程。下面是一个简单的示例。
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数介绍:
1. group默认为None(目前未使用)
2. target代表调用对象,即子进程执行的任务
3. name为进程名称
4. args调用对象的位置参数元组,args=(value1, value2, ...)
5. kwargs调用对象的字典,kwargs={key1:value1, key2:value2, ...}6. daemon表示进程是否为守护进程,布尔值
方法介绍:1.Process.start() 启动进程,并调用子进程中的run()方法
2. Process.run() 进程启动时运行的方法,在自定义时必须要实现该方法
3.Process.terminate() 强制终止进程,不进行清理操作,如果Process创建了子进程,会导致该进程变成僵尸进程
4.Process.join() 阻塞进程使主进程等待该进程终止
5.Process.kill() 与terminate()相同
6.Process.is_alive() 判断进程是否还存活,如果存活,返回True
7.Process.close() 关闭进程对象,并清理资源,如果进程仍在运行则返回错误
import multiprocessing
def worker(x,y,z):
"""该函数将在子进程中执行"""
print(x,y,z)
if __name__ == '__main__':
# 创建子进程
p = multiprocessing.Process(target=worker,args = (1,2,3))
# 启动子进程
p.start()
# 等待子进程结束
p.join()在上面的代码中,worker函数将在子进程中执行。首先,创建了一个Process对象,指定target参数为worker函数。然后,通过调用start方法启动子进程,最后调用join方法等待子进程结束。
示例:
def get_final_result(chunk):
#以任意一chunk为实例进行处理,其余的chunk均按照此逻辑运行
for index in tqdm((range(len(chunk)))) :
str_data = chunk[index]
test_dict = ast.literal_eval(str_data)
text = test_dict['text'].split('航空公司不会')[0].split('如需')[0].split('若需')[0].split('服务电话')[0].split('服务热线')[0].split('热线')[0].split('客服电话')[0].split('请拨打')[0].split('请打')[0].split('致电')[0].split('联系')[0].split('来电')[0]
text = text.replace('(','').replace(')','').replace('(','').replace(')','')
label = test_dict['label']
result = get_result(text)
write_file(result)
if __name__ == "__main__":
#读入航班信息
file_path = '/home/zhenhengdong/WORk/SMS_Parsing/规则/Data/原始_airports.json'
with open(file_path, 'r', encoding='utf8') as f:
json_filedata = f.readlines()
#启动进程池
pool = multiprocessing.Pool(20)
#划分chunk
chunks = [json_filedata[start:start + 1000] for start in range(0, len(json_filedata), 1000)]
#将所有的chunk统一传进处理函数中
results = pool.map(get_final_result,chunks)2-1-2 Pool
如果需要创建大量的进程,那么使用Process类可能会导致系统资源的浪费。此时,可以使用Pool类来创建进程池。下面是一个简单的示例。
import multiprocessing
def worker(num):
"""该函数将在子进程中执行"""
print('Worker %d' % num)
if __name__ == '__main__':
# 创建进程池
pool = multiprocessing.Pool(4)
# 启动进程池中的进程
pool.map(worker, range(10))
# 关闭进程池
pool.close()
# 等待进程池中的进程结束
pool.join()在上面的代码中,Pool类的构造函数中指定了进程池的大小为4,然后通过调用map方法来启动进程池中的进程。map方法会将worker函数和range(10)序列中的每个元素一一对应,然后将它们作为参数传递给进程池中的进程。最后,调用close方法关闭进程池,并调用join方法等待所有进程结束。
2-2 partial
针对一些特殊需求,需要对map函数传递两个或者多个参数,这时单纯的map函数已经不能满足需求了,就需要借助偏函数来完成。
偏函数是python自带的包,直接导入就能用。偏函数partial的第一个参数就是所承载的原函数,之后原函数的参数再依次传入partial函数。
from functools import partial
#定义
def add_num(x, y):
return x + y
# 承载add_num函数,并传入第一个参数
para = partial(add_num, 3)
# 传递第二个参数,就是把2传给para
result = para(2)
# 输出最后的结果
print(result)2-3 Pool与partial处理数据
import multiprocessing
import functools
def drop_app_index(drop_list, chunk):
for element in tqdm(drop_list):
chunk = chunk.drop(index = chunk[(chunk.pkg_name == element)].index.tolist())
return chunk
pool = multiprocessing.Pool(20)
drop_list = list(data['pkg_name'].value_counts().keys())[600:]
print(len(drop_list))
# 将DataFrame拆分为多个片段
chunks = [data.iloc[start:start + 10000] for start in range(0, len(data), 10000)]
#偏函数
g_with_a = functools.partial(drop_app_index, drop_list)
results = pool.map(g_with_a,chunks)
#results = pool.map(partial(process_chunk,drop_list),chunks)
# 合并所有处理结果
df_result = pd.concat(results)
data = df_result.reset_index(drop=True)













 2416
2416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









