







 本文利用Python对链家深圳二手房房源数据进行清洗、分析和可视化,探讨了行政区、户型、朝向、装修等因素对房价的影响,旨在为购房者提供参考。
本文利用Python对链家深圳二手房房源数据进行清洗、分析和可视化,探讨了行政区、户型、朝向、装修等因素对房价的影响,旨在为购房者提供参考。
前言
本项目主要是利用Python对语言链家二手房房源数据进行分析,通过数据可视化了解深圳的二手房源情况,对人们购房做出指导。分析过程主要围绕一下方面展开:项目背景、项目简介、项目流程(数据来源、分析目标、数据理解、数据可视化与分析)、项目总结。
一、项目背景
随着经济的发展,北、上、广、深这四大都市迅速发展,在经济、政治等方面有突出的表现,而且工作机会多,生活质量较高,是大多数人所向往的地方。但是要在这些城市定居是一件不容易的事情,这样来说购买二手房是一个可以选择的方案,说到这我们一定会想了解这些地区的房源大概情况。所以本项目是对深圳链家二手房房源进行的分析,希望可以帮助部分人解决购房问题,从多维度出发分析,帮助买家拿定主意,实现合理的购房!!
二、核心技术
Numpy、pandas、Matplotlib库的使用,数据清洗,数据可视化(也可用Tableau实现)
三、数据来源
数据来源于和鲸社区,附链接:
https://www.kesci.com/home/dataset/5e5e3effb8dfce002d7ed893
四、数据理解
深圳二手房房源信息:
- 数据量级:18906条;
- 数据说明:
area:行政区(如:南山区)
title:房源信息标题
community:小区
position:地段位置(如:万象城)
tax:税率相关(如:房本满五年)
total_price:总价,单位:万元
unit_price:单价,单位:元/平米
hourseType:户型(如:三室一厅)
hourseSize:面积,单位:平米
direction:房间朝向
fitment:装修(如:精装,简装)
五、分析目的
1.了解圳二手房的大体情况,通过对不同行政区、不同户型、不同朝向、不同装修进行分析来了解
2.分析深圳二手房房价的影响因素有哪些?优质房源有哪些?
3.怎么选择合适的房源?
六、数据分析与可视化
(一)数据清洗
- 引入使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定默认字体#读取数据文件,查看数据的大体情况
df = pd.read_csv('./Python案例数据/shenzhen.csv')
df.head()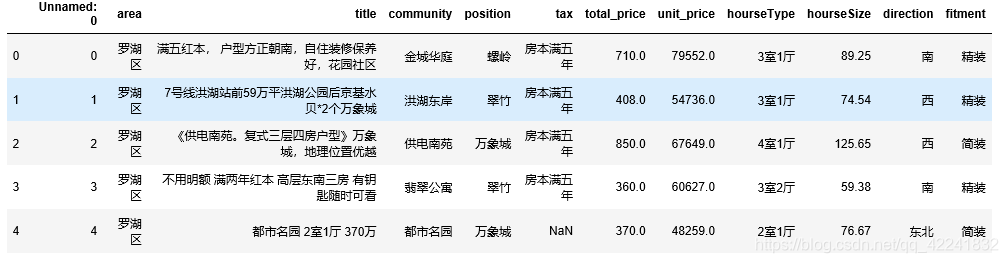
df.describe() # 查看数据列的数据 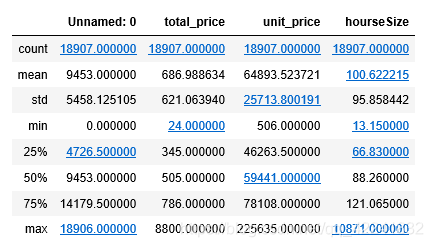
2.房间大小有夸大的部分,经过查询发现房价与房源面积不符合客观事实,进行删除
#房间大小超过10000平米的数据
df[df['hourseSize']>10000]
df.drop(df[df['hourseSize']>1000].index,inplace=True)
df[df['hourseSize']>10000] #确认是否正确删除
3.数据概览:
#查看每列的总数、数据类型
df.info()发现title和tax列存在缺失数据,但这两列不是需要分析的列。其它列数据完整,不需要进行处理。

4. 重复值处理:
# 查看重复值
df[df.duplicated()]
数据清洗完成,开始数据分析。
(二)数据分析
1.了解圳二手房房源的整体情况(总体分析)
主要从四个方面出发利用matplotlib绘制饼图。
不同行政区、户型、朝向、装修与二手房房源数量的对比
数据处理:
# 不同行政区房源数量占比
area_house_count = df.groupby('area')['area'].count()
area_house_count.sort_values(ascending=False,inplace=True) #按照降序排列
# area_house_count
# 不同户型房源数量占比
hourseType_count = df.groupby('hourseType')['hourseType'].count()
hourseType_count.sort_values(ascending=False,inplace=True) #按照降序排列
new_hourseType_count = hourseType_count[hourseType_count>700]
new_hourseType_count['其它'] = hourseType_count[hourseType_count<700].sum()
# new_hourseType_count
# 不同朝向房源数量占比()
direction_count = df.groupby('direction')['direction'].count()
new_direction_count =direction_count[direction_count>800]
new_direction_count['其它'] = direction_count[direction_count<800].sum()
new_direction_count.sort_values(ascending=False)
# 不同装修
fitment_count = df.groupby('fitment')['fitment']</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









