







再次整理一波文本检测论文,前面写过的就不写了。
这是一个目录
TextBPN
论文全名:Adaptive Boundary Proposal Network for Arbitrary Shape Text Detection。发表在ICCV 2021。
Motivation
任意形状的文本检测是很具有挑战性的,作者提出了一个自适应的边界候选网络(adaptive boundary proposal network),可以不需要任意后处理操作而直接产生准确的任意形状的文本检测结果。
Pipeline
模型包含一个boundary proposal model和一个innovative adaptive boundary deformation model。前者使用多层的空洞卷积产生先验信息,其中先验信息包括cls map,distance field,direction field。后者使用一个编码解码网络,编码包含一个GCN和一个RNN,结合先验信息迭代地进行boundary deformation。

cls map:对应的ground truth是一个binary pixel classification map,预测得到的是soft mask,表明文本区域是文本的概率。
direction field:每个像素点预测一个向量,指向它离得最近得的boundary 的像素点。
distance field:每个像素预测一个值,是这个direction field对应的向量的值的归一化后的。
得到这些maps后,需要进行处理得到proposals,具体操作是:
- 针对distance field使用某个阈值 t h d th_d thd进行过滤,产生一系列候选的boundary proposals,然后结合cls map,计算每个proposals内部的平均confidence,去除掉其中confidence很低的proposals。
- 在每个boundary proposal上,均匀采样
N
N
N个控制点。每个proposal得到这N个点相关的feature vectors,对这些特征进行GCN、RNN和Conv的操作,最后聚合在一起,用3个1×1卷积和一个ReLU进行解码,预测得到每个点的offsets。
前面得到proposals的过程是Boundary proposal model,后面的编码解码是Adaptive deformation model。
损失函数
损失函数由两个子模块的损失值组成。Boundary proposal model是针对它预测得到的多个maps进行像素级的损失计算,Adaptive deformation model是对每个控制点的坐标进行损失计算。
RSCA
论文全名:RSCA: Real-time Segmentation-based Context-Aware Scene Text Detection。发表在CVPR 2021。
Motivation
现在基于分割的文本检测方法,一般都无法学习弯曲文本的形状,并且需要复杂的pixel level的标注或者重复的特征融合操作。
Pipeline
本文提出了两个模块,一个是Local context aware upsampling,另一个是Dynamic text spine labeling。前者用于建模局部的空间变换,后者用于简化标注工作。
LCAU:

上图给出了LCAU的基本结构,首先使用conv得到
H
×
W
×
l
2
H\times W\times l^2
H×W×l2,然后upsampling,stride=r,得到
r
H
×
r
W
×
l
2
rH\times rW\times l^2
rH×rW×l2。这里的
l
2
l^2
l2可以看成是在位置
(
x
,
y
)
(x,y)
(x,y)的原始的conv kernel的感受野,相当于对于每个位置,都计算了附近区域的权重,经过softmax后得到每个像素点的局部weight,然后和原来的feature map进行加权。
Dynamic Text Spine Labeling的思路也很简单,在训练过程中,文本区域将会被逐渐扩大,因而在训练中逐渐提高了正样本的比例。
损失函数
就是普通的cross entropy损失函数。
NASK
论文全名:All You Need is a Second Look: Towards Arbitrary-Shaped Text Detection。发表在AAAI 2021。
Motivation
现在主流的关于任意形状的文本检测,都是采用了实例分割的流程,但是由于尺寸的差异很大,任意形状的文本很难在单个分割网络中被检测出来,NASK提出了一个two stage方法。
Pipeline
NASK包含一个Text Instance Segmentation(第一个stage),一个Geometry-aware Text RoI Alignment(GeoAlign),和一个Fiducial point expression(第二个stage)。
Text Instance Segmentation这个部分借鉴了Non-local Neural Network ,但不同的是,Non-local Neural Network计算的是一个channel内的不同的像素点的影响,但这里作者认为不同channel之间也可能会有相互影响,所以这里作者提出了GSCA,将channels进行分组,对同一组的channels关系进行建模。

上图给出了GSCA的介绍,先使用
Θ
\Theta
Θ,
Φ
\Phi
Φ,
Q
\mathcal{Q}
Q(分别代表一个conv和reshape的组合)来处理原始feature map,然后分别对这三个branches中得到feature map进行分组,然后前面两个特征图将会进行矩阵乘,然后再和后面的特征图相乘,还有一个分支
R
\mathcal{R}
R处理了H后得到每个channels的权重,然后得到channel reweighting后的输出特征
M
=
M
+
Y
M=M+Y
M=M+Y。
Geometry-aware Text RoI Alignment(GeoAlign)是设计用来计算非规则的文本区域的特征图的RoI pooling操作,对于位置
(
i
,
j
)
(i,j)
(i,j)进行GeoAlign,将会计算下面这个公式:
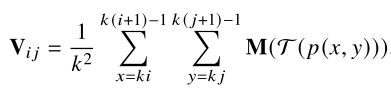
p
(
x
,
y
)
p(x,y)
p(x,y)是对
(
i
,
j
)
(i,j)
(i,j)采样得到的某个邻域中的点的位置信息,
T
\Tau
T操作是一种仿射变换,这个仿射变换需要从
M
M
M学习得到,在pooling时,结合
M
M
M和
T
\Tau
T进行形状相关的信息聚合。
Fiducial point expression是接在Geometry-aware Text RoI Alignment(得到每个proposal的Text Center Line,角度信息,和字符scale信息)后,在中心线上进行均匀采样,得到 n + 2 n+2 n+2个中心点构成center point list。然后作者将文本区域看成 n n n长的序列,序列中的每个元素表示一个字符segment,而每个字符segment由中心点,尺寸,字符的角度,以及中心点的角度。
PCR
论文全名是Progressive Contour Regression for Arbitrary-Shape Scene Text Detection。发表在CVPR 2021。
Motivation
作者认为现在解决文本检测很多都是基于像素级、小组件,因此会对噪声比较敏感,且依赖于复杂的启发式后处理操作。
Pipeline
先产生水平文本候选框:参考CenterNet,用heatmap预测文本框的中心点和尺寸;
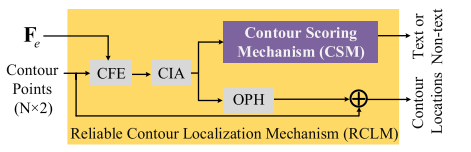
在上一步产生的水平框上,均匀地选择 N o N_o No个点,然后将这些点的位置信息和语义信息聚合在一起,作为CIA的输入(Contour information aggregation),产生一个表达力更强的边框特征 F c i a ∈ P N o × D F_{cia}\in P^{N_o\times D} Fcia∈PNo×D。这个特征将会产生这些边框点的坐标位移预测,也就得到了这些点的新的坐标。
在上一步产生的旋转的文本边框上,均匀的选择 N a N_a Na个点,然后再使用K个CLMs来逐渐地回归文本边框边界到任意的形状。考虑到也许边框会从一些错误的预测演化而来,所以作者提出使用RCLM来增加检测得到的边框更加可靠。
下图说明了上述文本提到的几个组件:CIA,CLM和RCLM。
CIA:

CLM:

RCLM:
STKM
论文全名:Self-attention based Text Knowledge Mining for Text Detection。发表在CVPR 2021。
Motivation
作者提到现在很多方法都忽视了自然图片和场景文字图片的差距,直接用ImageNet来预训练,为了解决这个问题,一些人首先直接使用一个很大的合成数据来预训练模型,然后在目标数据集上进行微调。本文致力于提供一个泛化的预训练的模型用于文本检测,作者提出了一个Self attention based text knowledge Mining(STKM),包含一个CNN编码器和一个self attention解码器,从合成的文本数据集来为文本检测学习到泛化的先验知识。给定图片级别的标注信息,解码器直接从CNN编码器提供的特征解码,而不需要检测,这引导着CNN去学习语义表达。
Pipeline

a和b分别代表预训练和真实的训练。
a:使用CNN encoder得到feature map
F
e
∈
R
H
×
W
×
C
F_e\in R^{H\times W\times C}
Fe∈RH×W×C,然后flatten这个feature map,为了不是去spatial information,作者这里引入一个ASPM,输入是位置矩阵
M
∈
R
H
×
W
×
2
M\in R^{H\times W\times 2}
M∈RH×W×2,
M
(
i
,
j
,
0
)
=
j
/
H
M(i,j,0)=j/H
M(i,j,0)=j/H,
M
(
i
,
j
,
1
)
=
i
/
W
M(i,j,1)=i/W
M(i,j,1)=i/W。ASPM模块将
M
M
M编码产生空间位置编码
S
S
S,最终我们将
S
S
S加到
F
e
F_e
Fe,得到
F
F
F。
接下来,到了解码阶段,解码阶段是一个step by step的过程,具体和transformer很类似。该解码阶段以flatten后的feature map
I
I
I为输入,然后输出
S
o
u
t
∈
R
L
×
C
S_{out}\in R^{L\times C}
Sout∈RL×C。也就对应着长度为
L
L
L的字符序列。
b:使用预训练后的模型参数,直接作为backbone配合检测器来进行文本检测。
SPCNet
论文全名:Scene Text Detection with Supervised Pyramid Context Network。论文发表在AAAI 2020。
Motivation
由于自然图片的差异大且很复杂,以前的检测方法很有可能会产生很多的false positives。为了解决这个问题,作者基于Mask RCNN提出了一个文本检测模型。
Pipeline

上面的图片很清楚地介绍了模型的pipeline。FPN捕捉不同感受野的特征map,TCM融合不同尺度的特征图,得到feature map后,使用c的mask rcnn 的head得到instance segmentation结果,而d则展示了TCM的细节,最终会产生整个图片的分类结果。
而本文我个人认为的一个创新点在于后面提到的re-score mechanism,这个机制是对Mask RCNN的NMS机制进行了改进。
原来的NMS的score是每个bounding box的分类置信度,而作者认为,这种方法将会使得有些低scores值的TP样本被过滤了,因为如果一个水平矩形完整地包围了一个文本区域,其中仍然有很多背景区域,所以作者这里提出,对scores值进行重新计算,
PAN
论文全名:Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network。发表在ICCV 2019。
Motivation
场景文本检测主要存在两个问题:
- 速度和准确率的平衡;
- 任意形状的文本检测。
现在很多方法都提出了解决任意形状的文本检测办法,但是很少考虑整个pipeline的速度,而这在现实的应用中往往会无法满足速度的要求。
Pipeline
本文提出了一个Pixel aggregation network,具有一个低计算量的segmentation head,和一个可学习的后处理。其中segmentation head包含一个Feature Pyramid Enhancement Module (FPEM)和Feature Fusion Module (FFM)。其中FPEM是一个U shaped的模块,FFM是用于聚合FPEMs产生的feature maps得到最终的特征图,用于后续的分割任意。而作者提到的可学习的后处理是通过聚合像素来实现的,通过学习像素的向量表示,聚合相似的像素构成文本区域。

backbone是一个轻量级的卷积网络,这里作者只使用了ResNet 18,产生的feature map会输入FPEM,每个FPEM产生的feature map会由FFM融合后,得到最终的
F
f
F_f
Ff,
F
f
F_f
Ff最终产生三个不同的输出。
关于Pixel aggregation:
作者借鉴了聚类的思想,kernel是文本实例的中心,计算像素到不同的kernel的距离,属于同一个实例的像素的距离应该被拉近,不属于不同一个实例的kernel的距离应该拉远。这里的距离并不一定是空间距离,可以用similarity vector之间的差异来表述。
TextField
论文全名:TextField: Learning A Deep Direction Field for Irregular Scene Text Detection。发表在TIP 2019。
Motivation
场景文本检测的挑战在于不同的尺寸和aspect ratios,任意的方向以及形状。虽然目前很多检测器在多方向文本上的效果很好,但是对于弯曲文本效果并不好,所以作者提出了TextField。
个人认为,这篇文章的创新点在于引入了一种新的语义信息——direction field,这种信息按作者的话来说,同时编码了二进制的文本mask和方向信息(方向信息可以用来分割邻居文本实例)。
Pipeline

这图很清楚的给出了预测的过程,关于后处理,看起来较为复杂,暂时略过。















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









