







原文链接:https://arxiv.org/abs/2107.12664
源码链接:https://github.com/GXYM/TextBPN
前言
对于自然场景图像中任意形状的文本检测,在基于分割的方法中,仍然存在两个问题:一个问题是相邻文本实例无法有效分离,需要复杂的后处理;另一个问题是基于分割的方法依赖于轮廓检测的准确性,检测出的轮廓存在很多缺陷和噪声。因此,该论文提出了一种用于任意形状文本检测的自适应候选边界网络:作者提出先得到文本实例的粗边框(会略小于真实文本区域)以解决文本实例粘连的问题,同时设计边界自适应调整网络,使得粗边框调整进行迭代细化,最终接近真实边框。
一、方法设计
1.网络结构
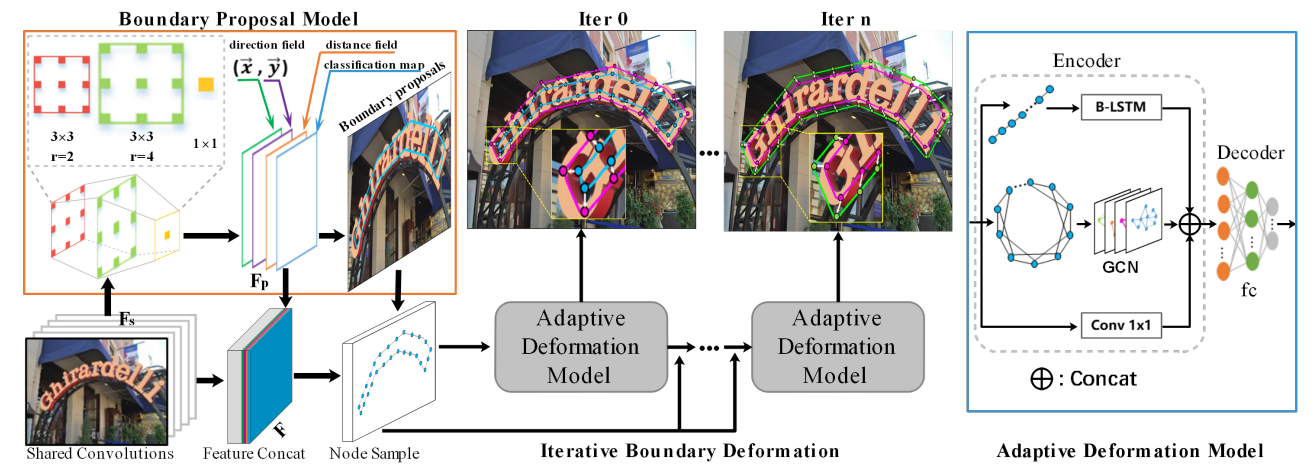 图1 TextBPN网络结构图
图1 TextBPN网络结构图
该网络结构包括以ResNet-50为骨干网络形成的类似特征金字塔结构生成Fs(图1中未画出该结构)、边界建议网络和自适应边界形变网络三个部分:
1)多层特征融合策略:将骨干网络的多层卷积通过上采样和拼接进行特征融合成Fs;
2)边框建议模块:有多层空洞卷积组成,包括两个不同空洞率的3 x 3卷积层和一个1 x 1卷积层,将多层融合的特征生成分类图、距离场图和方向场图,即先验信息Fp部分;
3)自适应边界形变网络:通过GCN和RNN对边界拓扑结构和序列上下文进行学习,通过迭代完成粗边框的细化。
(1)多层特征融合策略
将深层的特征通过上采样和上一层特征一样的尺寸进行cat操作,该模块具体网络结构如图2所示:

图2 类似FPN网络结构图
(2)边框建议模块
通过多层空洞卷积获得分类图、距离场图和方向场图,具体如图3所示
分类图包含每一个像素(文本/非文本)的分类置信度
方向场图()由一个二维单位向量
组成,如图3(c)所示,表示边界内每个文本像素到边界上最近像素的方向,对于文本实例
中的每个像素
,在文本框
上找到最近的文本边界像素
,然后计算每个像素的单位向量
,文本实例
以外的像素在方向场中设置为
。
距离场图()一个归一化的距离图,即表示文本像素
到 文本框
上找到最近的文本边界像素
的归一化距离
, 文本实例
以外的像素在距离场中设置
。 其中
表示像素
所在文本实例
的尺度。
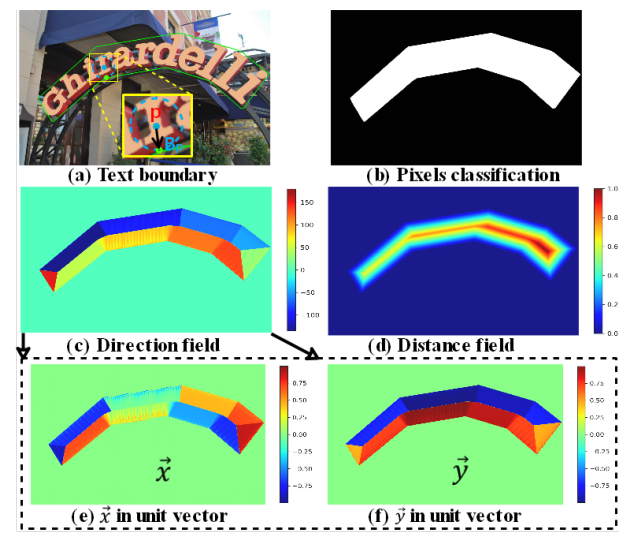
图3 先验信息特征图展示
在边框建议模块中,有了距离场图(),可以通过设定一个固定的阈值
来生成候选边框建议,在图4中,原图(a)通过距离场图得到可能的文本框,但是存在错误的检测,如图(b)所示,再根据分类图来计算每个候选边框的平均置信度,当得到的Proposal score低于设定的置信度阈值
就进行舍弃,最终得到所有的建议文本框。

图4 建议文本框的生成示意流程图
(3)自适应边界形变模块
本模块主要的功能是通过文本框中的拓扑结构和序列上下文进行学习,对于获得的粗边框进行迭代细化调整,以得到真正的文本框实例(个人理解类似完成了后处理的功能),这部分结构主要是在编码器部分引入了GCN和RNN,同时有一个分支使用一个1 x 1的卷积层形成了类似ResNet的残差结构,如图5所示,最后在译码器部分使用带有ReLU的三层1 x 1的卷积组成。为了对候选框进行细化,论文通过迭代处理(源码中将该模块代码进行循环拼接了3次)。
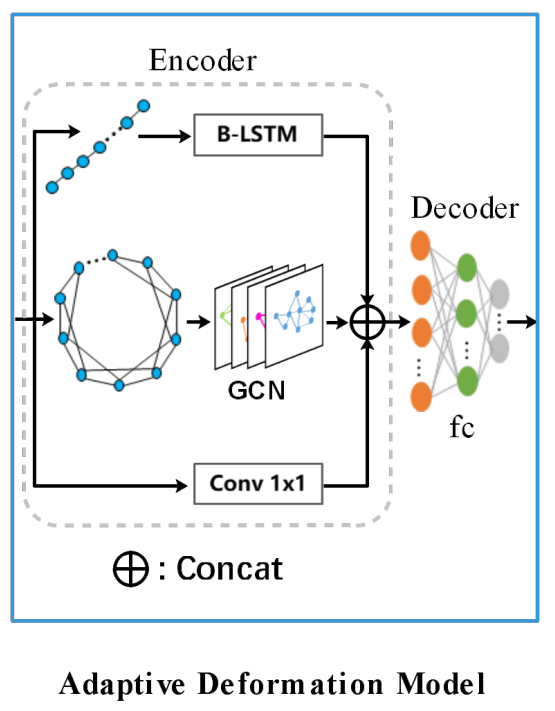
图5 自适应形变模块结构图
在得到建议候选框之后,需要得到坐标点,本论文中通过对建议候选框使用候选框进行边界选择,并按照周长划分为20个等长部分,分别取得20个坐标点,作为候选框坐标点。(在源码的训练中,是通过标注文本框生成的建议候选框20个坐标点来进行迭代训练)
而如图6所示,通过坐标点需要生成Node feature matrix来作为自适应形变模块的输入,具体操作如下:在图2中,可以看到,由CNN骨干网络获得的32-D共享特征Fs和通过多层空洞卷积得到的4-D先验特征进行concat一起组成cnn_feature,即F。同时结合20个坐标点在F中对应的位置提取每一个控制点(坐标点)的特征,最终得到了候选边界特征矩阵X(size:N x C)。
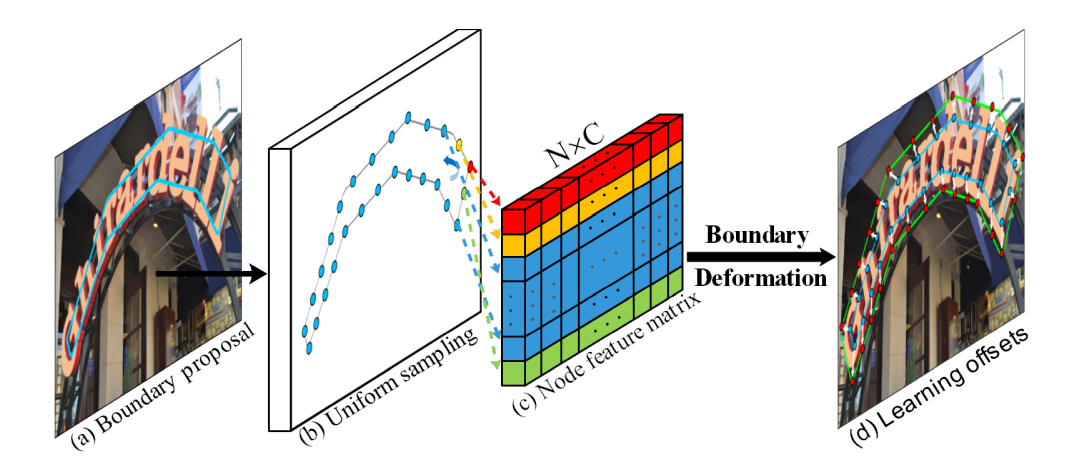
图6 整个自适应候选框形变网络流程示意图
2.损失函数
网络的损失函数定义为
其中为边框建议损失,
为自适应边界形变模型的损失,eps表示训练的最大epoch数,而
设置为0.1。
包含交叉熵分类损失的像素分类损失
,以及回归损失的距离损失
和L2-范式距离和角度距离在方向场构成的损失
,而
=3:
为点匹配损失,主要是计算预测点和真值点之间的损失,每一个文本实例的损失为
,因为在一张图像中有多个文本实例,所以需要计算平均损失:
二、实验结果
1.消融实验
(1)自适应候选框形变模块
在Total-Text和CTW1500上进行实验,采用了四种不同类型的编码器:FC和、RNN、circular convolution、graph convolution(GCN)进行实验,实验结果如表1所示,论文所提出的自适应形变网络渠道最好的效果。

(2)控制点数量
本实验主要是探究在生成建议文本框采用多少个控制点的效果最佳,将控制点数量设置在12~32,间隔为4,同样在Total-Text和CTW1500上进行评估,具体结果如图7所示,在控制点数量为 20左右达到了最佳的效果,因此在论文中设定的数量也为20个控制点。

图7 控制点数量实验结果
(3)迭代次数的影响
为了充分验证迭代次数的影响,作者对不同迭代次数下的模型进行实验,结果如表2所示,当迭代次数增加,其检测效果更好,但是推理速度会下降,同时在迭代2次和迭代3次的时候,效果提升不是很明显,为了均衡速度和性能,最终作者默认迭代次数设置为3。

同时,作者也给出了迭代过程中的预测文本框结果图,其中蓝色文本框为建议文本框(粗文本框),绿色为每次迭代出来的预测文本框,如图8所示。

图8 迭代结果可视化展示
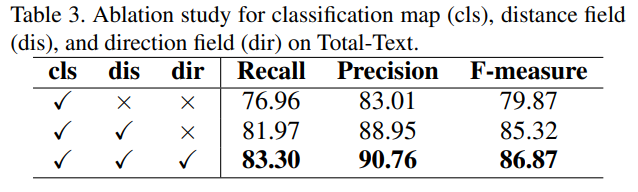
(4)先验信息的影响
在边框建议模块中,生成了分类图、距离场和方向场作为先验信息用于指导自适应候选框形变模块的迭代变换,结果如表3所示,加入的先验信息对于性能的提升具有很大的帮助。
(5)不同FPN分辨率
主要测试了使用FPN-P1(1/1)、FPN-P1(1/2)和FPN-P2(1/4),分别代表采用了FPN中P1特征经过上采样得到和原图尺寸一致的特征,以及P1特征未经过上采样的特征(尺寸为原图的1/2)和P2特征(尺寸为原图的1/4),结果如表4所示。

2.性能比较
Total-Text

CTW-1500

MSRA-TD500

总结
本文提出了一种用于任意形状文本检测的自适应边界建议网络,采用边界建议模型生成粗边界,然后采用结合GCN和RNN的自适应边界形变模型进行迭代边界变形,达到细化粗边框,以获得更准确的文本实例形状。
以上仅为博主本人阅读论文的经验总结,其中一些理解和总结并一定准确,如有错误欢迎批评讨论。
同时,对于源码的阅读和理解也欢迎大家一些讨论学习,互帮互助,共同进步。















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









