







- 在人工智能的发展越来越火热的今天,其中智能应用也在伴随着我们的生活,其中最具有代表性的便是图像识别,并且其中的应用比比皆是,如:车站的人脸识别系统,交通的智能监控车牌号系统等等。而卷积神经网络作为图像识别的首选算法,其对于图像的特征提取具有很好的效果,而Keras框架作为卷积神经网络的典型框架,可以很好地创建神经网络层,更容易提取图像特征,从而达到区分矿石的目的,从而在生产实践中达到辅助的效果。
首先我们需要准备训练的数据集文件,其中我找的图片都是来自于百度图片,将其保存在./data/train文件夹下,同时在其中建立四个文件夹,分别保存煤炭的图片,花岗岩,石灰岩,砂岩的图片,其中的数据集如下:
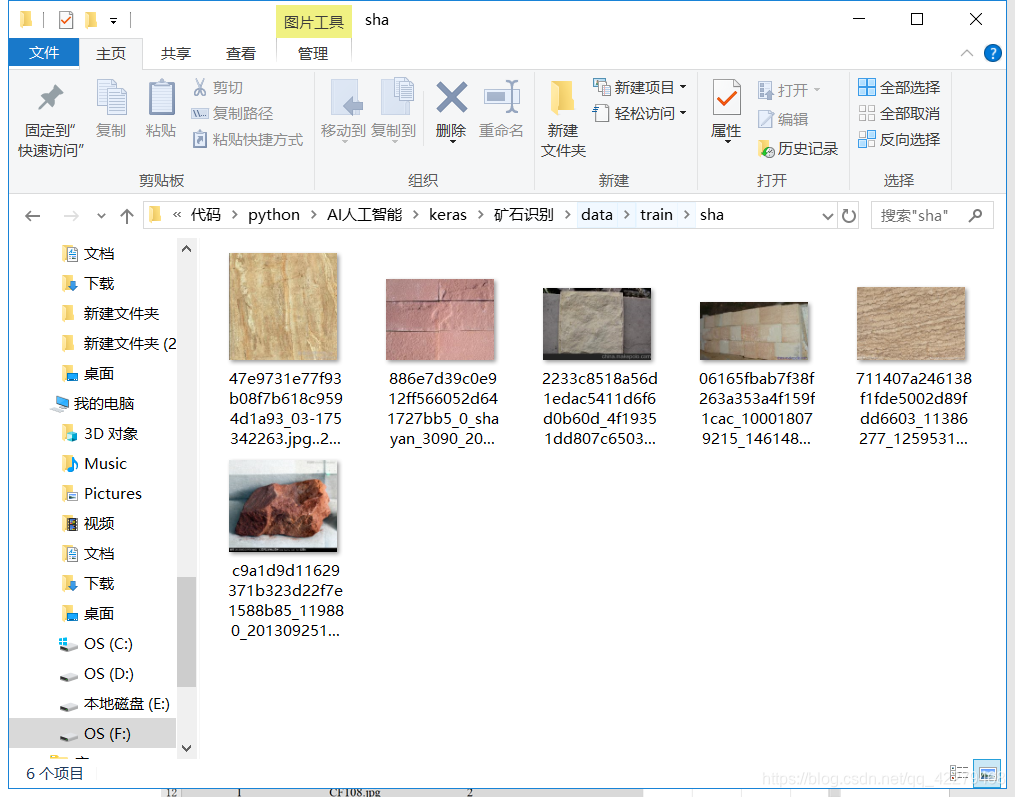
其中需要训练的数据集的标签就是文件夹的名称。
接着新建deep learning.py文件写入代码,代码部分首先要导入需要用到的库:
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Activation,Dropout,Flatten,Dense
from keras.optimizers import Adam
fromkeras.preprocessing.imageimportImageDataGenerator,img_to_array,load_img
from keras.models import load_model
接着为了提高模型的精准度,需要在图片中进行旋转角度,平移等图形变化形成新的图形拿来训练从而提高精准度代码如下:
train_datagen = ImageDataGenerator(
rotation_range = 40, # 随机旋转度数
width_shift_range = 0.2, # 随机水平平移
height_shift_range = 0.2,# 随机竖直平移
rescale = 1/255, # 数据归一化
shear_range = 20, # 随机错切变换
zoom_range = 0.2, # 随机放大
horizontal_flip = True, # 水平翻转
fill_mode = 'nearest', # 填充方式
)
将数据
进行归一化处理:
test_datagen = ImageDataGenerator(
rescale = 1/255, # 数据归一化
)
接着定义一些参数变量,代码及注释如下:
IMG_W = 224 #定义裁剪的图片宽度
IMG_H = 224 #定义裁剪的图片高度
CLASS = 4 #图片的分类数
EPOCHS = 200 #迭代周期
BATCH_SIZE = 64 #批次大小
TRAIN_PATH = 'data/train' #训练集存放路径
TEST_PATH = 'data/test' #测试集存放路径
SAVE_PATH = 'rock_selector' #模型保存路径
LEARNING_RATE = 1e-4 #学习率
DROPOUT_RATE = 0 #抗拟合,不工作的神经网络百分比
接着创建一个神经网络对象,model = Sequential() #创建一个神经网络对象
接着下面是卷积神经网络的算法部分,首先简单说明下这篇文章所用的卷积神经网络的原理和结构:首先创建第一个卷积层,输入的值是三通道图片的像素矩阵矩阵,即为矩阵的行和列对应图片的宽度和高度,由于图片是三通道图片,故有三个像素矩阵,建立32个卷积核用来和三个像素矩阵相乘,其中卷积核的大小是3*3,即为kernel_size=3,padding=“same”表示对于结果矩阵不丢失边缘数值,激活函数使用relu激活函数,代码即为:
#添加一个卷积层,传入固定宽高三通道的图片,以32种不同的卷积核构建32张特征图,
卷积核大小为3*3,构建特征图比例和原图相同,激活函数为relu函数。
model.add(Conv2D(input_shape=(IMG_W,IMG_H,3),filters=32,kernel_size=3,padding='same',activation='relu'))
其中神经网络原理图如下:
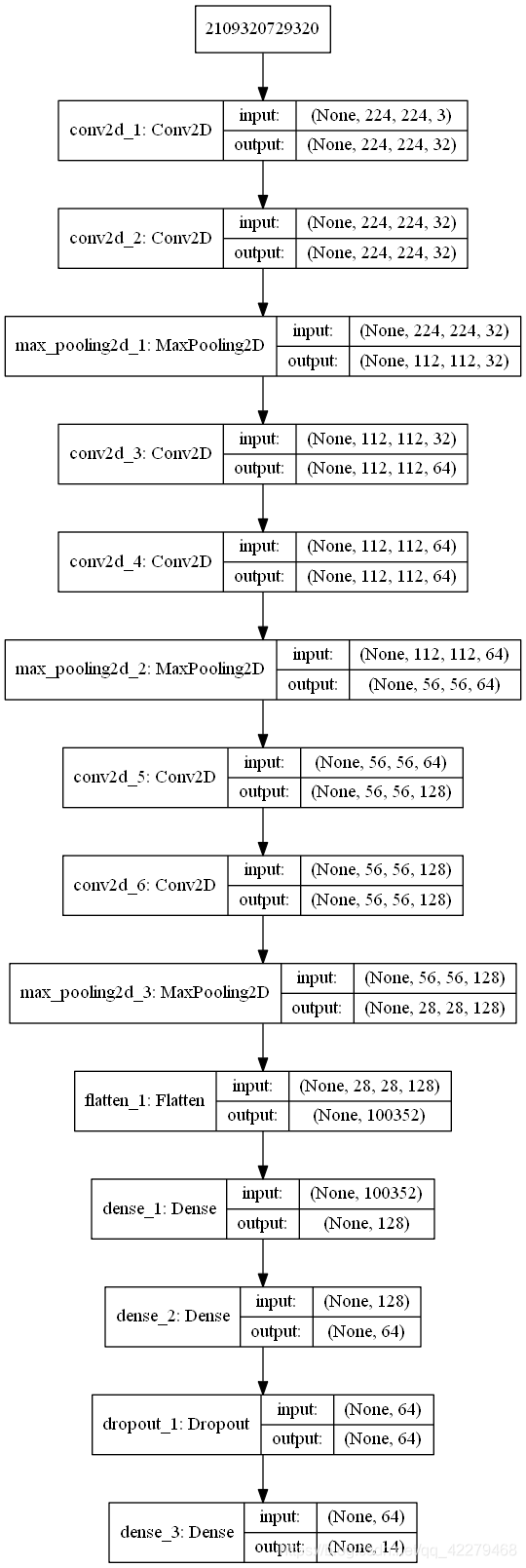
接着创建多个卷积层以及池化层,每一层的输入为上一层的输出,其中池化层类似卷积层,主要目的在于降采样,减少训练的数值,可以防止过拟合,代码如下:
#再次构建一个卷积层
model.add(Conv2D(filters=32,kernel_size=3,padding='same',activation='relu'))
#构建一个池化层,提取特征,池化层的池化窗口为2*2,步长为2。
model.add(MaxPool2D(pool_size=2,strides=2))
#继续构建卷积层和池化层,区别是卷积核数量为64。
model.add(Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'))
model.add(Conv2D(filters=64,kernel_size=3,padding='same',activation='relu'))
model.add(MaxPool2D(pool_size=2,strides=2))
#继续构建卷积层和池化层,区别是卷积核数量为128。
model.add(Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'))
model.add(Conv2D(filters=128,kernel_size=3,padding='same',activation='relu'))
model.add(MaxPool2D(pool_size=2, strides=2))
model.add(Flatten()) #数据扁平化
model.add(Dense(128,activation='relu')) #构建一个具有128个神经元的全连接层
model.add(Dense(64,activation='relu')) #构建一个具有64个神经元的全连接层
model.add(Dropout(DROPOUT_RATE)) #加入dropout,防止过拟合。
model.add(Dense(CLASS,activation='softmax')) #输出层,一共4个神经元,对应4个分类
接着创建一个ADAM优化器,adam = Adam(lr=LEARNING_RATE),然后使用交叉熵代价函数,adam优化器优化模型,并提取准确率
接着开始利用创建好的模型进行训练:
t
rain_generator = train_datagen.flow_from_directory( #设置训练集迭代器
TRAIN_PATH, #训练集存放路径
target_size=(IMG_W,IMG_H), #训练集图片尺寸
batch_size=BATCH_SIZE #训练集批次
)
test_generator = test_datagen.flow_from_directory( #设置测试集迭代器
TEST_PATH, #测试集存放路径
target_size=(IMG_W,IMG_H), #测试集图片尺寸
batch_size=BATCH_SIZE, #测试集批次
)
print(train_generator.class_indices) #打印迭代器分类,各分类代号为{'du': 0, 'gui': 1, 'kang': 2, 'tao': 3}
try:
model = load_model('{}.h5'.format(SAVE_PATH)) #尝试读取训练好的模型,再次训练
print('model upload,start training!')
except:
print('not find model,start training') #如果没有训练过的模型,则从头开始训练
model.fit_generator( #模型拟合
train_generator, #训练集迭代器
steps_per_epoch=len(train_generator), #每个周期需要迭代多少步(图片总量/批次大小=11200/64=175)
epochs=EPOCHS, #迭代周期
validation_data=test_generator, #测试集迭代器
validation_steps=len(test_generator) #测试集迭代多少步
)
model.save('{}.h5'.format(SAVE_PATH)) #保存模型
print('finish {} epochs!'.format(EPOCHS))
最终训练的结果200次模型的精准度96.2%,可行。其中算法部分的结构图为:
接着利用创建好的模型进行试验,建立predict.py文件用来预测图片,将要试验的图片放在./predict文件夹下,首先需要导入库的代码为:
from keras.models import load_model
from keras.preprocessing.image import img_to_array,load_img
import numpy as np
import os
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
接着载入模型,由训练部分的代码可知模型文件为rock_selector.h5
model = load_model('rock_selector.h5')
分类分别为花岗岩,煤,石灰岩,砂岩,建立一个数组用来保存
label = np.array(['花岗岩','煤','砂岩','石灰岩'])
定义函数,用来把图片转成可以识别的矩阵,由于激活函数值在01之间,故需要将其中矩阵值变在01之间,故需要除以255以达到目的
def image_change(image):
image = image.resize((224, 224))
image = img_to_array(image)
image = image / 255
image = np.expand_dims(image, 0)
return image
加载图片,对于predict文件夹下的图片都进行识别,并在图片上加上结果标签
for pic in os.listdir('./predict'):
print('图片真实分类为',pic)
image = load_img('./predict/' + pic)
plt.imshow(image)
image = image_change(image)
myfont = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=15)
plt.title(label[model.predict_classes(image)], fontproperties=myfont)
plt.show()
print('预测结果为',label[model.predict_classes(image)])
print('----------------------------------')
最终拿一张没有参与训练的花岗岩和煤的图片测试,最终得到的实验的结果如下:
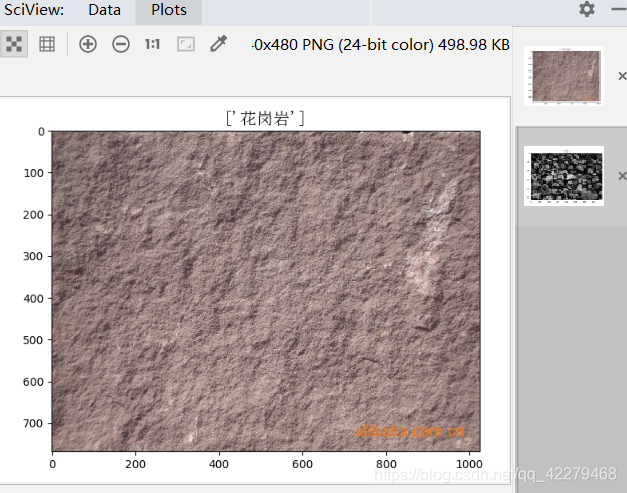
欢迎大家关注我的公众号“人工智能实战之常见代码分享”

















 798
798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











