







Visualizing and Understanding Convolutional Networks
会议:ECCV
时间:2014年
本文是CNN领域可视化理解的开山之作,这篇文献告诉我们CNN的每一层到底学习到了什么特征,然后作者通过可视化进行调整网络,提高了精度。本文主要提出了一种新的可视化技术,该技术可以深入了解不同中间特征层(卷积核)的功能和分类器的操作,而通过了解这些功能或对神经网络模型进行诊断,能够辅助人们对网络模型进行优化。本文通过上述可视化方法对AlexNet进行改进,提出ZFNet。
1.Introduction
近年来,神经网络在许多领域取得了令人瞩目的成果,例如手写数字识别和人类检测。本文认为,神经网络能够取得较好结果的主要原因有:1.大规模数据集的出现。2.高性能硬件(GPU)的发展,使训练大模型成为可能。3.更好的模型正则化策略,如Dropout的出现等。
然而,尽管能够取得较好结果,但对于这些复杂模型的内部操作和行为,或者它们如何实现如此良好的性能,人们仍然知之甚少。为解决此问题,本文提出一种可视化技术:多层反卷积网络(multi-layered Deconvolutional Network,deconvnet)将特征激活映射回输入的像素空间,以揭示原图中哪些部分对当前特征图产生激活刺激。此外,本文还通过遮挡输入图像的部分来对分类器输出进行灵敏度分析,揭示场景的哪些部分对分类是重要的。
通过使用上述方法,本文对AlexNet[1]模型结构进行改进,在ImageNet数据集上取得了更优的结果。
1.1 Related Work
传统特征可视化方法往往仅局限于第一层,即仅在第一层对像素空间进行投影可视化(由于浅层网络比较容易识别到),但其缺少了对高层图像语义的关注。2009年,Erhan等人[2]通过在图像空间中执行梯度下降来找到每个单元的最优刺激,从而最大化单元的激活,也就是找到使这个单元激活最大的原始图像。但此方法需要谨慎的初始化,并且不提供任何关于单元不变形的信息(这里单元不变性不太理解,看视频解释说是:网络能从不同的图中提取到同样的特征和信息,捕捉到不同东西里的相同之处)。2010年Le[3]等人延伸了Berkes&Wiskott等人的想法,用Hessian矩阵的数值解表示一个最优的响应。但难点在于,对于网络的更高的层不变性是非常复杂的,所以很难用简单的二阶近似(quadratic approximation)来捕获。相比之下,我们的方法提供了不变性的非参数视图,能够表明每个中间层的feature map对训练集中哪种特征哪种模式感兴趣,即训练集中的哪些模式能够激活特定的特征图。在2013年,Donahue等人[4]在论文中展示的可视化方法能识别出数据集中对模型高层产生强烈激活作用的Patch。而本文提出的方法则无需对原始输入图像进行切割,而是从后向前的(top-down)投影,揭示每个Patch中能刺激特定特征图的结构。
2.Approach
本文使用与LeNet5和AlexNet相同的结构,并根据可视化结果对后者进行一定改进。网络使用2D彩色输入图像
x
i
x_i
xi,通过一系列网络层得到表示
C
C
C个不同类别的概率向量
y
^
i
\hat{y}_i
y^i。每个网络层包括以下几个部分:卷积层,激活函数(ReLU),max pooling和归一化层。最后使用一个全连接层和softmax构成分类器。下图为ZFNet的整体结构:
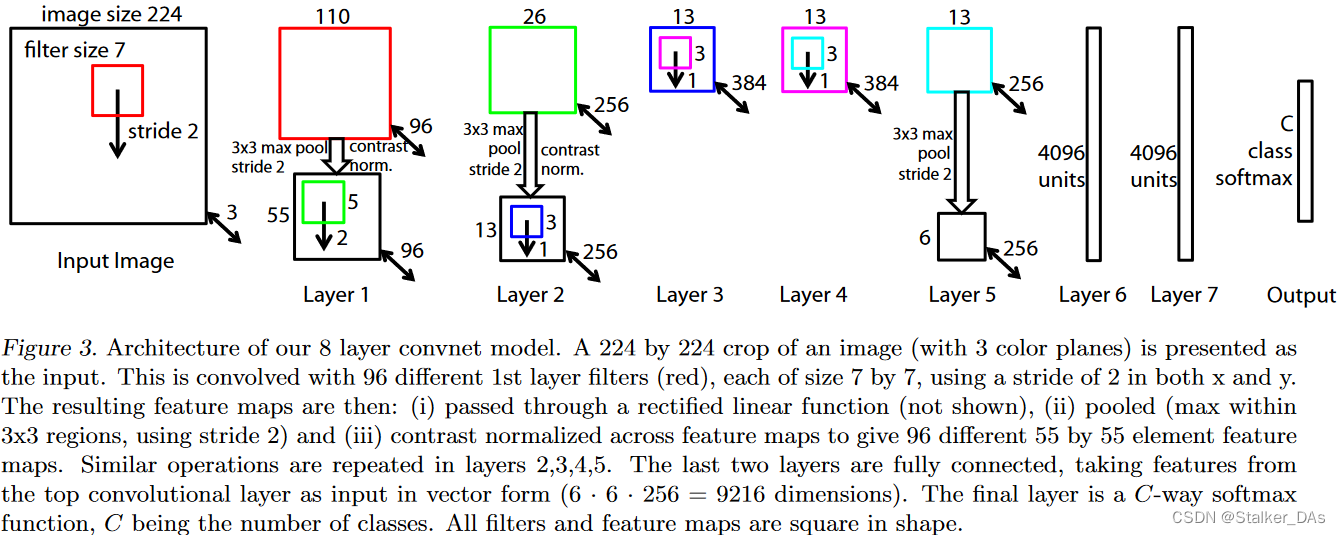
本文使用N张图像和标签构成的集合{x,y},其中
y
i
y_i
yi为离散型(估计为one-hot类型),交叉熵作为loss,通过SGD进行优化。
2.1 Visualization with a Deconvnet
理解卷积神经网络的操作首先需要对网络中间层特征的激活进行解释,本文的一大创新点就是找到一个能够将这些激活后的特征图映射至原始像素空间,以显示最初是什么输入模式导致了特征图的激活。这里特征图的激活通常指经过一个卷积核生成的feature map的总和值最大。
本文使用反卷积网络(deconvolution Network, deconvnet)来完成这个映射。通常反卷积网络用于无监督学习,而本文没有将其用于任何网络的学习,仅仅是用来探索已训练好的网络的能力。
本算法反卷积的整体流程如下图上半部所示:
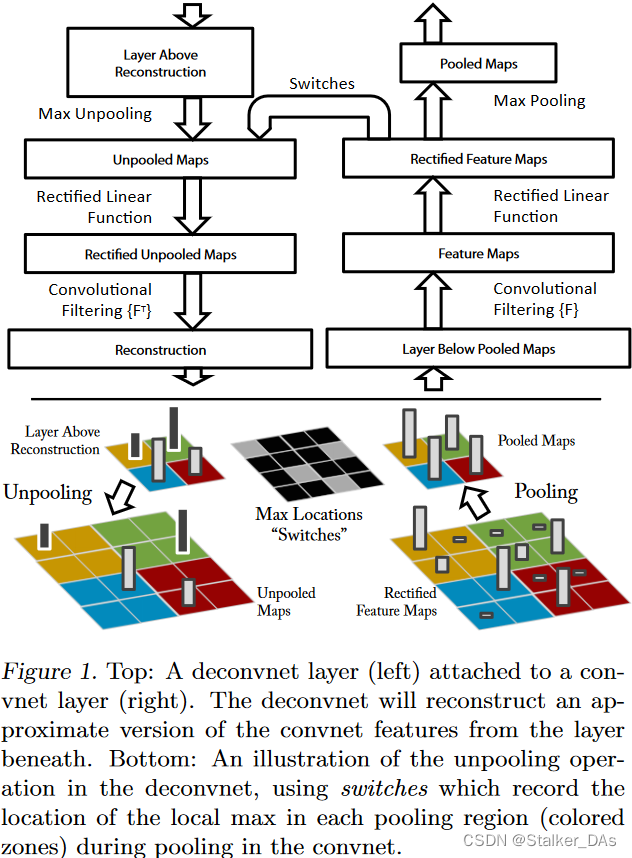
首先,将输入图像送入卷积网络并通过其他网络层计算特征,为了检查给定的卷积核的激活,我们将层中的所有其他激活设置为零(可以认为是其他卷积核的输出),并将特征映射作为输入传递给附加的反卷积网络层,之后执行(1).unpool (2).rectify (3).filter以重建该feature map在下一层中的激活。持续执行上述操作直到达到最初输入像素空间。下面将对上述三操作分别进行介绍。
Unpooling:max pooling操作往往是不可逆的(也就是每次只能记录一个感受野中的最大值,其他位置的信息会丢失),但可以通过记录每次pooling最大值位置的方式尽可能保留原始图像中的激活信息,此位置信息被保存至一组开关变量switch中,具体操作如图1下半部分。(然而此方法同样不可避免会丢失一些非极大像素值的信息)
Rectification:卷积网络使用ReLU非线性激活函数确保特征图中的元素保持正值,为了得到每层有效特征重构(有效的特征往往为正值),这里同样对重构的图像进行ReLU操作。这里为什么要用ReLU对非正值进行过滤,以下是我的想法:
1.增加整个网络的非线性能力,因为单纯的CNN网络是线性的,通过引入非线性激活函数可使还原出的图像更准确。
2.这点是GPT回答的:对于图像数据而言,通常情况下,像素值应该是非负的。在计算机视觉任务中,图像像素表示的是图像中的颜色强度或灰度值。通常,像素值的范围是从0到255(8位图像)或从0到1(归一化后的图像)。在卷积神经网络(CNN)的反卷积过程中,我们希望通过上采样和卷积操作来还原输入图像的特征表示。这些特征表示应该与原始图像具有类似的性质,包括非负像素值。
如果在反卷积过程中出现了负值,那么在还原的特征图中可能出现不合理的图像细节,比如出现虚假的边缘或结构。这是因为负值可能会导致颜色强度或灰度值的不合理变化,与实际图像内容不符。
为了避免产生不合理的负值,Deconvnet引入了Rectification阶段,使用ReLU激活函数将特征图中的负值设置为0。这样做可以确保还原的特征图保持非负,更符合实际图像的像素表示。同时,ReLU激活函数还提供了非线性修正,使得还原的特征能够更好地捕捉原始图像中的细节和特征。
Filtering:为了还原卷积后的特征图,deconvnet将原始卷积核进行转置(这里的转置是水平和垂直同时翻转),并应用于重构的图像上。
从较高层向下投影时,会使用向上投影时由网络中最大池化产生的switch设置。由于这些switch设置是给定输入图像所特有的,因此从单个激活中获得的重建结果类似于原始输入图像的一小部分,其结构权重取决于它们对特征激活的贡献。同时由于模型是经过辨别训练的,因此它们隐含地显示了输入图像中具有辨别能力的部分,也就是和CAM,Grad-CAM一样带有一部分定位的功能。
整体流程为:输入图像->卷积操作->激活函数->最大池化->得到feature map->反池化->Relu->反卷积->得到结果
3.Training Details
此部分主要介绍网络的训练细节,包括模型设置,参数等。
4.Convnet Visualization
Feature Visualization:
这里首先对不同层卷积核的输出结果进行了可视化,如下图所示。(这里右侧的图片应该是通过截图获得的当前feature map在原图最相似的部分)

这里对每个卷积核激活最大的9张图像和其生成的图像进行了可视化,可以观察到以下几个特点:(1)浅层网络更注重学习一些低语义信息的特征,如简单的边缘、颜色等,随着网络的加深,中层网络开始学习一些物体的形状如layer3中所示。而高层网络的特征则更加复杂和特化,更注重学习物体本身,或一些更高语义(或更抽象,人更难理解)的特征,比如Layer5最右上的图是学习草地的特征。(2)随着网络的加深,网络对输入图像的不变性逐渐增强,即越到高层,网络越能从不同的物体中提取相同的语义特征。
Feature Evolution during Training:
此实验是对训练过程中的特征演化进行可视化。如下图所示,可以看到模型在最开始几个epoch的收敛过程,其中图像的忽然变化往往是由最激活的图像发生变化所引起的。此外还可以发现,高层卷积层在40-50之后才开始产生变化,这表明模型需要一个训练过程直至完全收敛。

Feature Invariance:
下图展示了5张图像不同程度上平移、旋转和缩放后的特征相对于原始特征的变化程度,结果如下图所示:
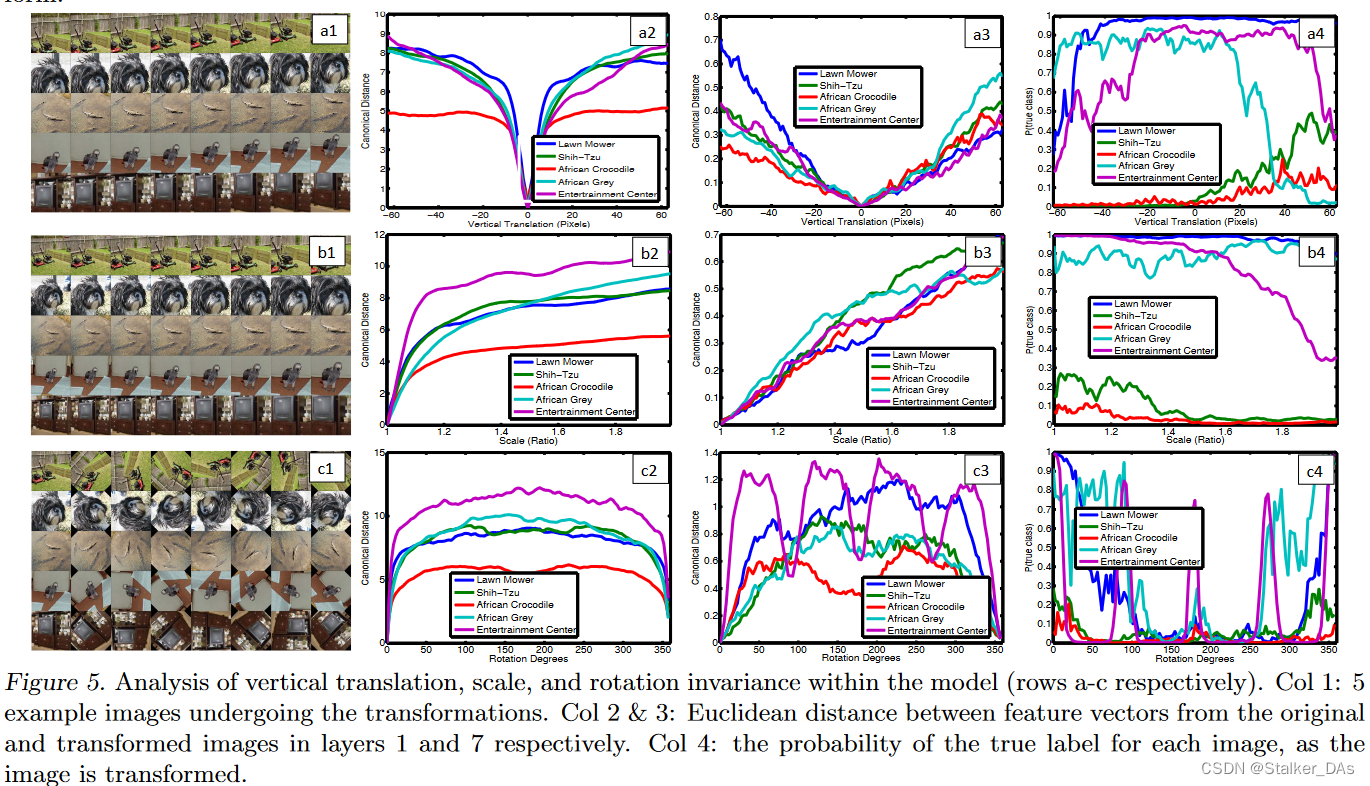
可以看到一些微小的变化会对模型第一层有显著的效果,但是对更深层的影响较小。在深层网络中,对于平移和缩放来说是拟线性的。
4.1 Architecture Selection
这节主要讨论如何通过可视化方法对网络模块进行优化,这里我觉得比较重要,也算是可解释性的一个重要应用。通过可视化AlexNet的第一层和第二层的结果(下图b和d)可以看到存在许多问题。例如,第一层卷积核存在大量特别高和特别低的高频信息,却对中频信号覆盖范围很小,因此这些卷积核往往为无效的卷积核(也就是图中灰色的卷积核)。此外,第二层可视化显示了由第一层卷积中使用的大步长stride为4引起的混叠伪影。
因此本文对以下部分进行了修改:(1)将第一层卷积核的大小从11x11调整为7x7(至于为什么这么修改,我的理解是通过可视化发现很多卷积和是无效的,也就是没有学到东西,通过把卷积核调小可以让模型捕获更多细节信息,这些细节信息只能通过小卷积核获取,而一些全局大的结构是可以通过堆叠加深网络学习到的)(2)将卷积核的步长从4调整到2。这种新架构在第一层和第二层特征中保留了更多的信息,如图c和e所示,并且提升了分类任务的准确率。

4.2 Occlusion Sensitivity
本实验对局部遮挡的敏感性进行分析。这里主要探究网络在识别一张图片时的注意力在哪个地方,我觉得这里实验更类似于CAM和Grad-CAM。
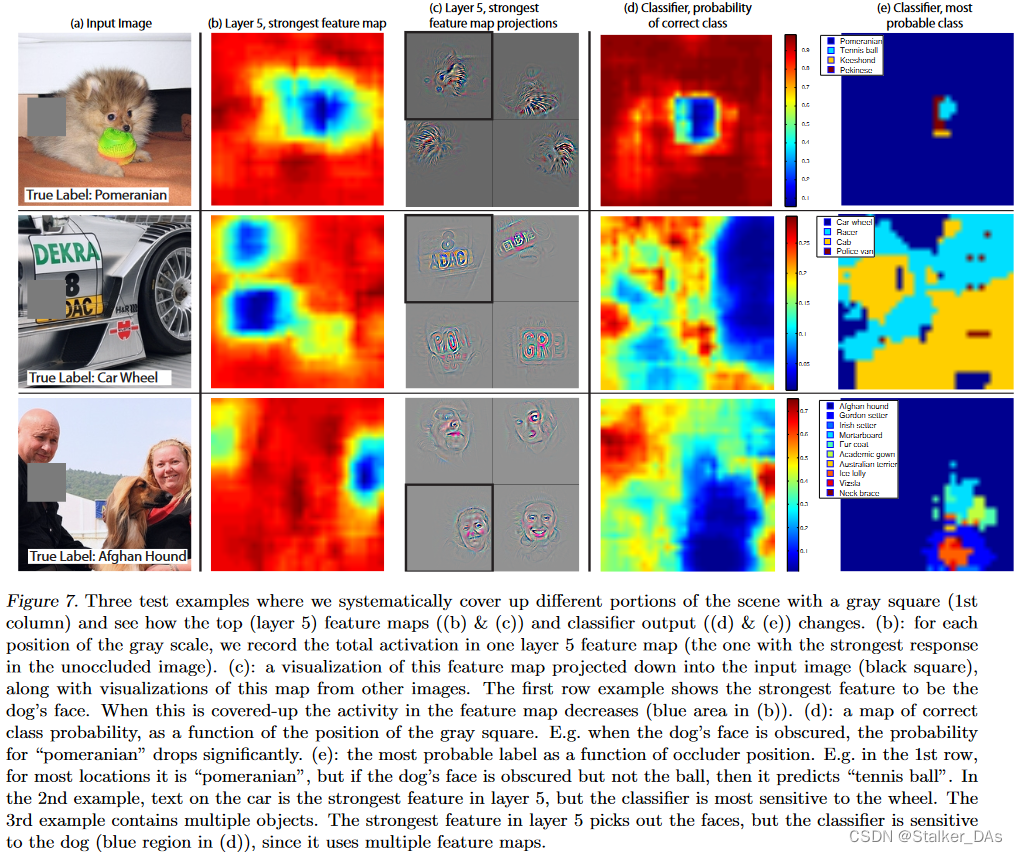
实验通过一个滑块对原始输入图像进行遮挡,其中(d)列表示在遮挡不同部位时,网络识别出正确类别的概率。(e)列表示当滑块遮挡不同类别时,网络识别的不同类别,例如d列的第三行,当滑块将人脸遮挡的时候,网络能更准确地或更确信这张图片识别出的是阿富汗猎犬。而(c)列(黑框中的图片)表示将未经任何遮挡的原图加入至网络中,并从第5层中找出被激活最大的feature map,将其用反卷积的方法投影重构会原始像素空间,并可视化出来。而另外的三张图则是从原始数据集中找到能使相同卷积核激活最大的图像,并重构,可以看到第一个卷积核主要提取毛绒绒的特征,第二个注重提取文字特征,而第三个注重提取人脸特征。(b)列表示通过滑块进行不断遮挡,将(c)列对应的卷积核输出的feature map的激活值进行相加得到的结果,也就是通过可视化看出该卷积核更注重的部分。比如第三行的卷积核更注重提取人类的信息,这时候挡住人脸的部分,从(b)中就可以看到,得到的结果大幅度降低。
这些上述样例可以清楚地表明,模型能够定位场景中的物体,物体被遮挡时,正确分类的概率显著下降。
PS:此实验也能证明某个神经元的激活值是表示该神经元对输入图像的关注程度。大的激活值表示该神经元对于输入模式(图像)的匹配和相应更加敏感。
4.3 Correspondence Analysis
该实验探索模型对同一类别不同图像的相同位置的预测是否有相关性。深度模型与许多现有的识别方法不同,它没有明确的机制来建立不同图像中特定物体部分之间的对应关系(例如,人脸的眼睛和鼻子有特定的空间构造),但本文认为,深度模型可能在通过隐式的方式计算他们之间的关系。

这里对五张正面的狗的图像相同位置进行遮挡,以证明上述结果。对于任意一张图像
i
i
i,计算
ϵ
i
l
=
x
i
l
−
x
~
i
l
\epsilon_i^l=x_i^l-\tilde{x}_i^l
ϵil=xil−x~il,其中
x
i
l
x_i^l
xil和
x
~
i
l
\tilde{x}_i^l
x~il分别表示第l层的原始图像和遮挡后的图像的特征向量。之后,测量所有相关图像对
(
i
,
j
)
(i,j)
(i,j)差异向量的一致性consistency,公式如下:
Δ
l
=
∑
i
,
j
=
1
,
i
≠
j
5
H
(
sign
(
ϵ
i
l
)
,
sign
(
ϵ
j
l
)
)
\Delta_l=\sum_{i,j=1,i\neq j}^5\mathcal{H}(\operatorname{sign}(\epsilon_i^l),\operatorname{sign}(\epsilon_j^l))
Δl=∑i,j=1,i=j5H(sign(ϵil),sign(ϵjl)),其中
H
\mathcal{H}
H为Hamming距离。更低的
Δ
\Delta
Δ表示更高的一致性即遮挡左眼会以一致的方式改变特征表征。实验结果如下表:
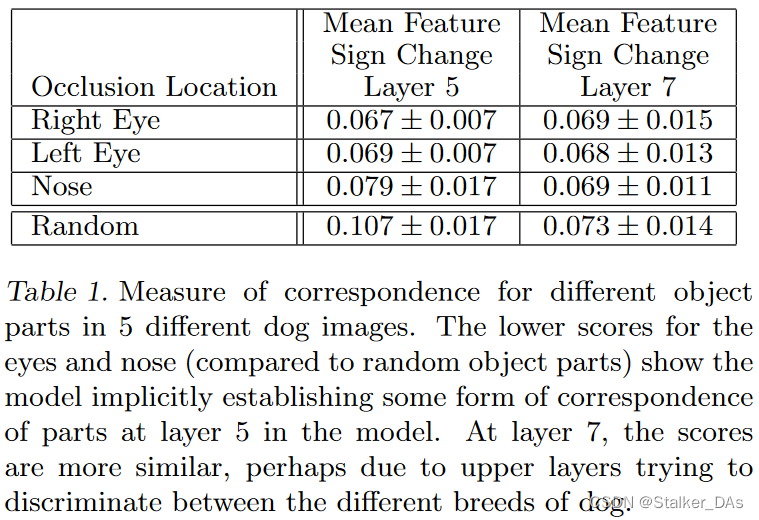
从表中可以证明,模型确实建立了一定程度的对应关系。
5.Experiments
这里的实验主要证明改进后的网络的有效性,时间关系这里就不过多做笔记了。
6.补充知识
"反卷积"如何操作的?
"Hamming距离"如何计算?
参考文献
[1]. Krizhevsky, A., Sutskever, I., and Hinton, G.E. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
[2]. Erhan, D., Bengio, Y., Courville, A., and Vincent, P. Visualizing higher-layer features of a deep network. In Technical report, University of Montreal, 2009.
[3]. Le, Q. V., Ngiam, J., Chen, Z., Chia, D., Koh, P., and Ng, A. Y. Tiled convolutional neural networks. In NIPS, 2010.
[4]. Donahue, J., Jia, Y., Vinyals, O., Hoffman, J., Zhang, N., Tzeng, E., and Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. In arXiv:1310.1531, 2013.
[5]. https://blog.csdn.net/hjimce/article/details/50544370















 3398
3398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









