







 本文通过Deconvnet技术可视化Alex-net,揭示卷积网络的工作原理,指出其不足并提出改进策略。实验表明,调整网络结构后,分类性能提升1.7%。此外,探讨了CNN的特征不变性、位置敏感性和推广能力。
本文通过Deconvnet技术可视化Alex-net,揭示卷积网络的工作原理,指出其不足并提出改进策略。实验表明,调整网络结构后,分类性能提升1.7%。此外,探讨了CNN的特征不变性、位置敏感性和推广能力。
Visualizing and understandingConvolutional Networks
本文是Matthew D.Zeiler 和Rob Fergus于(纽约大学)13年撰写的论文,主要通过Deconvnet(反卷积)来可视化卷积网络,来理解卷积网络,并调整卷积网络;本文通过Deconvnet技术,可视化Alex-net,并指出了Alex-net的一些不足,最后修改网络结构,使得分类结果提升。
摘要:
CNN已经获得很好的结果,但是并没有明确的理解为什么CNN会表现的这么好,或者CNN应该怎样修改来提升效果。同构本文的可视化技术,可以很好地“理解”中间的特征层和最后的分类器层。通过类似诊断(可视化+“消除”研究ablation study)的方式,这种可视化技术帮助我们找到了超越Alex-net的结构,本文还通过在ImageNet上训练,然后在其他数据集上finetuning获得了很好的结果。
一,介绍
多项技术帮助CNN复兴(最早是98年,LeCun提出的):1,大的标定数据集;2,Gpu使得大规模计算成为可能;3,很好的模型泛化技术
本文的可视化方法是一种非参数化的可视化技术。
二,方法
首先通过监督的方式利用SGD来训练网络,要了解卷积,需要解释中间层的特征激活值;我们利用Deconvnet来映射特这激活值返回到初始的像素层。
2.1利用Deconvnet
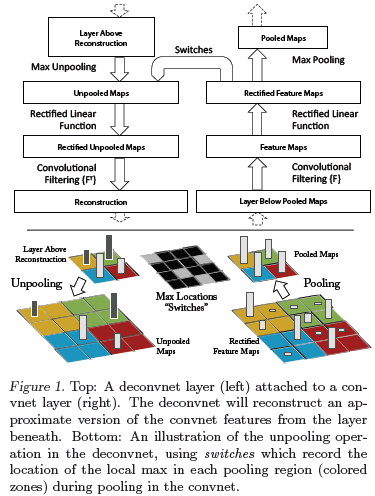
1正常卷积过程convnet:
如图右侧黑框流程图部分,上一层pooled的特征图,通过本层的filter卷积后,形成本层的卷积特征,然后经过ReLU函数进行非线性变换的到Recitifed特征图,再经过本层的max-pooling操作,完成本层的卷积池化操作;之后传入下一层。本层需要记录在执行max-pooling操作时,每个pooing局域内最大值的位置
2选择激活值:
为了理解某一个给定的pooling特征激活值,先把特征中其他的激活值设置为0;然后利用deconvnet把这个给定的激活值映射到初始像素层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









