









前言
下午博主正在工位品着茶,突然听到一声呐喊:“玄学,明明上锁了,怎么锁不住呢?”,隔壁小哥抚摸着为数不多的头发,眉头紧锁。相信很多初学者对“锁”这个概念很陌生,觉得特别深奥,今天就来揭秘一下大厂面试高频面试点:分布式锁。(文章末尾有彩蛋)
一、锁是什么?
锁是什么?什么时候我们需要用到锁。博主第一次接触到锁还是在学并发编程的时候,当时学的迷迷糊糊的,等自己用了几次以后,发现原来如此简单。顾名思义:锁就是要给一个东西上锁,为什么要上锁呢?因为这个东西只能被一个人访问。打个比方,现在有个数代表库存,修改库存的操作是先将这个库存读到,然后减一。咱们假设这个减一的操作耗时需要1分钟,在这1分钟内,又有一个线程来减1,咱们希望他读到的值是上一个线程减一后的,但是由于上一个线程还没执行完,是不是就到这个线程读的值还是未减之前的。如图所示:
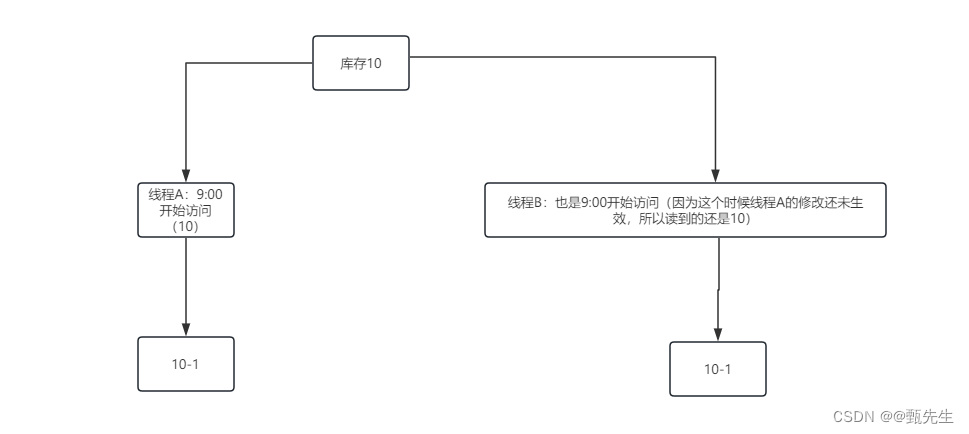
大家看上面这个操作是不是就导致库存就不准确了。那么怎么解决呢?加锁。线程A读取到库存后,给库存上锁,当库存减完以后再释放锁,这个时候当线程B在想访问库存的时候,因为线程A还没有计算完,锁还没有释放,线程B只能等待,等待线程A释放完锁,线程B才能够访问。
通过上面的例子可以看到,哪种情况需要上锁呢,当多个线程需要竞争同一资源的时候,并且操作不是原子性的。
原子性:操作不能再被细分,这个叫原子。读是原子性,写是原子性,先读再写就不符合原子性(上图的例子就是先读后写)
二、使用场景
分布式锁的使用场景和上面的例子类似,只不过说从线程变换成为了进程(一个微服务就是一个进程),具体可以总结为:
- 在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行
三、实现方式
- 基于数据库实现分布式锁
- 基于Zookeeper实现分布式锁
- 基于reids实现分布式锁
1.数据库实现分布式锁
先科普一个知识点:排他锁。
排他锁:for update。在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。获得排它锁的线程即可获得分布式锁,当获得锁之后,可以执行方法的业务逻辑,执行完方法之后,释放锁connection.commit()。当某条记录被加上排他锁之后,其他线程无法获取排他锁并被阻塞。
select * from lock where lock_name=xxx for update;
上面这条sql,执行以后会对lock 进行上锁,上锁后只要涉及到这个表的sql都会等待,直到显示的再执行commit,排他锁才会消除。
说白了用数据库实现分布式锁就是在表里放一个值,然后只要那个值存在就说明有锁,那个值被删除了,锁才被释放。
优点:直接借助数据库,简单容易理解。
缺点:在并发比较少的时候推荐使用,并发高的时候不推荐。而且如果不显示操作commit,这个锁不会自动释放,会一直持有,并且那些由于锁不释放而被占用的数据库连接也不会自己中断,一旦类似的连接变得多了,就可能把数据库连接池撑爆。
2.zookeeper实现分布式锁
简单的说就是在zk上创建一个节点,如果这个节点存在就说明锁存在,如果节点不存在就说明没有锁。具体可描述为下面四步:
- 当一个客户端想要获取锁时,它在 ZooKeeper 上创建一个有序的临时节点。
- 每个客户端创建的节点会按照顺序排列,形成一个有序的节点路径。客户端会监视前一个节点,一旦前一个节点被删除(代表锁被释放),该客户端就获得了锁。
- 如果某个客户端没有获得锁,它会监听自己创建的节点,并等待前一个节点被删除,从而触发自己获取锁的机会。
- 当客户端完成任务后,它会删除自己创建的临时节点,从而释放锁。
代码如下:
ZooKeeper zk = new ZooKeeper("localhost:2181", 5000, null);
String lockPath = zk.create("/locks/lock-", new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
List<String> children = zk.getChildren("/locks", false);
Collections.sort(children);
String smallestNode = children.get(0);
if (lockPath.endsWith(smallestNode)) {
// 已获取到锁,执行业务逻辑
} else {
// 未获取到锁,等待或执行其他逻辑
}
// 删除锁
zk.delete(lockPath, -1);
zk分布式锁和数据库锁不同的地方是,zk提供了一个观察者机制(watch),即所有线程都能够实时感知锁的状态变化,当锁被释放后,等待的线程能够实时被唤醒,可以不用采取轮询锁的方式来判断锁是否被释放,避免了不必要的轮询。
但是也正是因为这个观察者机制,当并发非常高的时候,容易产生羊群效应,即如果同一时间多个节点对应的客户端完成事务或事务中断引起节点消失,ZooKeeper 服务器就会在短时间内向其他客户端发送大量的事件通知,会对zookeeper服务器造成极大的性能影响和流量冲击。
3.redis实现分布式锁(推荐)
背景知识:setnx命令:set if not exists,当且仅当 key 不存在时,将 key 的值设为 value。若给定的 key 已经存在,则 SETNX 不做任何动作。简单的说就是在redis里放一个key,如果这个key存在,说明锁存在,如果这个key不存在,说明锁不存在。
现在市面上有很多实现redis分布式的工具,博主这里推荐使用Redisson(redis性能最高的客户端,很多大厂都在使用),直接上代码:
RLock lock = redisson.getLock("myLock");
try {
// 尝试获取锁,最长等待10秒
boolean isLocked = lock.tryLock(10, TimeUnit.SECONDS);
if (isLocked) {
// 成功获取锁,执行业务逻辑
System.out.println("Lock acquired, performing business logic...");
} else {
// 获取锁失败,处理相应逻辑
System.out.println("Unable to acquire lock within specified time.");
}
} catch (InterruptedException e) {
// 处理异常
e.printStackTrace();
} finally {
// 释放锁
lock.unlock();
}
看上述代码,和zk,数据库都不同的是,在使用redis做分布式锁的我们需要先给key设置一下过期时间,而这个过期时间设置为多少合适呢?设置大了会极大的影响系统性能,设置小了,怕代码还没执行完,锁就失效了?这个也是一个很经典的面试问题。听到这个问题直接回答:看门狗机制。
什么是看门狗机制:redisson在获取锁之后,会维护一个看门狗线程,在每一个锁设置的过期时间的1/3处,如果线程还没执行完任务,则不断延长锁的有效期。看门狗的检查锁超时时间默认是30秒,可以通过 lockWactchdogTimeout 参数来改变。
总结
总之实现分布式的方案有很多很多,一定要结合自己的业务和公司的技术栈,不要为了技术而技术,技术存在的意义就是为了业务服务。想要提高自己的编程技术一定要勤敲代码和多思考。
博主每天都会发一篇博客,主要分享大厂常用技术栈和面试题(不是分享八股,是分享实战技术),最后点赞+关注的人都能拿到好offer,下篇博客分享前言提到的,为什么明明上锁了,但是却没锁住(和redis底层有关!)















 140
140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









