







前言
所有java开发者都离不开Springboot,市面上百分之99.999的公司都在用Springboot框架。而搭建一个最简单的项目就是Springboot+mysql,大部分项目的起步阶段都是这样,然后再根据业务场景再引入其他redis,nacos等中间件,这节教大家如果快速的搭建一个项目。
一、mysql
MySQL 是目前项目中运用最广泛的关系型数据库,无论是互联网大厂,还是中小型公司,几乎都在用。
MySQL 体积小、速度快、源码开放,所以广受开发者喜爱。
MySQL 的安装非常简单,针对不同的操作系统,MySQL 都提供了安装包的下载。
至于mysql 的安装,之前文章docker里面已经介绍了,详情请戳:
docker一键部署mysql
二、springboot集成mysql
1.集成mysql
Spring Boot 整合 MySQL 数据库非常简单,只需要添加 MySQL 依赖并在配置文件中添加数据库配置即可。我们可以不用编写原始的访问数据库的代码,也不用调用 JDBC 或者连接池就可以访问 MySQL。
1)使用 Intellij IDEA 新建一个 Spring Boot 项目,使用 Java 8 版本。(现在springboot官方已经不提供java8版本的springboot项目初始化,可以配置阿里镜像)
2)引入mysql相关依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
3)填写配置文件
spring:
datasource:
username: root
password: 123456
url:jdbc: mysql://127.0.0.1:3306/qcby?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false
上面相关配置更换为自己配置即可。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.集成数据库连接池
Druid 是阿里巴巴开源的一款数据库连接池,结合了C3P0、DBCP 等 DB 池的优点,同时还加入了日志监控。
Druid 在 GitHub 上已经收获了 25.4k 的 star,可以说非常的知名,从简介上也能看得出,Druid 就是为了监控而生的。
druid源码
Druid 包含了三个重要的组成部分:
- DruidDriver,能够提供基于 Filter-Chain 模式的插件体系;
- DruidDataSource,高效可管理的数据库连接池;
- SQLParser,支持所有 JDBC 兼容的数据库,包括 Oracle、MySQL 等。
Spring Boot2.0 以上默认使用的是 Hikari 连接池,我们从之前的日志信息里就可以看得到。
Hikari 和 Druid 有什么区别呢?
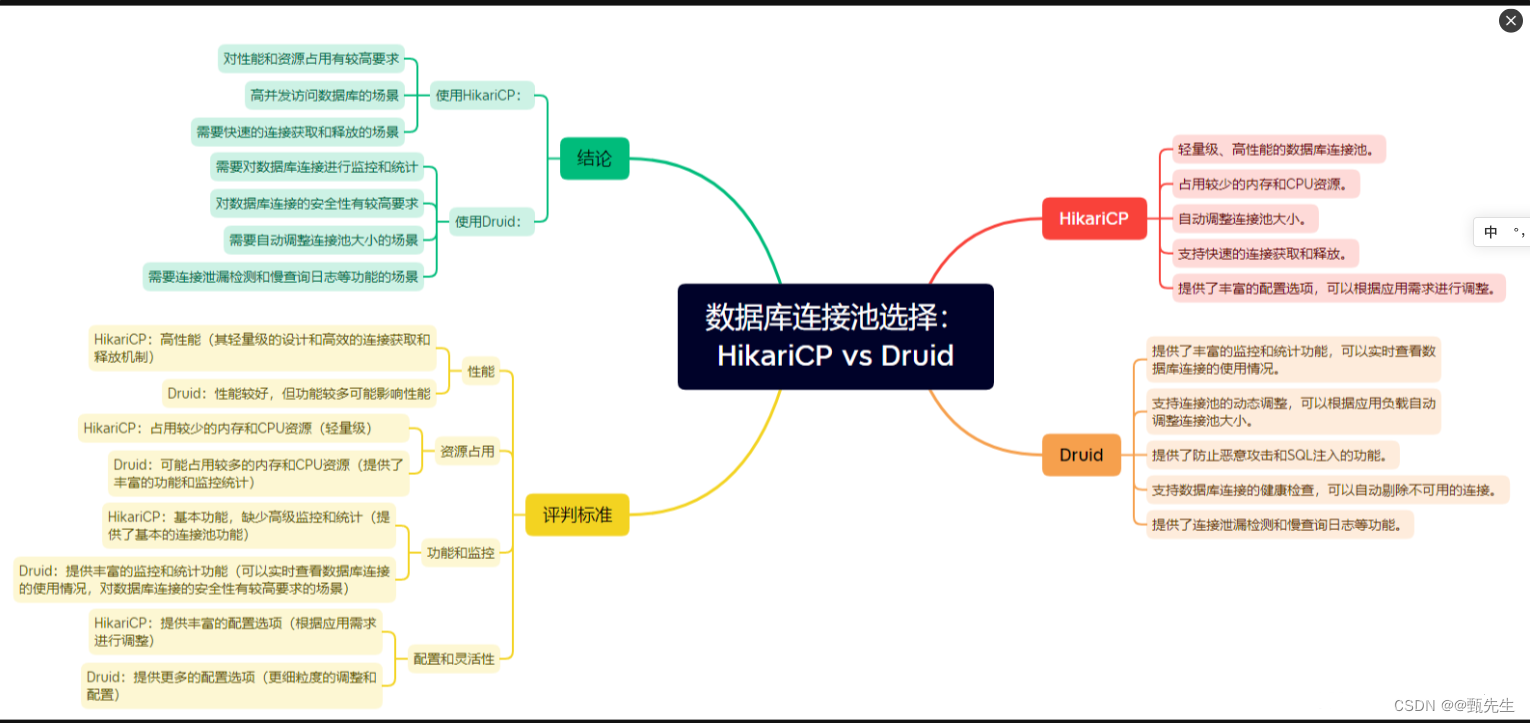
简单的说Druid功能更全面,而Hikari性能则更高。
那如果我们想使用 Druid 的话,该怎么整合呢?
1)添加pom依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
2)在 application.yml 文件中添加 Druid 配置(将数据库连接池由Hikari切换为Druid)
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/1cby?characterEncoding=utf8&serverTimezone=UTC
username: root
password: 123456
# druid-spring-boot-starter 依赖自动生效 druid,可以不配置 type 属性,但建议配置
type: com.alibaba.druid.pool.DruidDataSource
只需要在原有的配置上加上type即可。
3)添加Druid专有配置
# druid 数据源专有配置
# 不是druid-spring-boot-starter依赖,SpringBoot默认是不注入druid数据源专有属性值的,需要自己绑定
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计。stat:监控统计 log4:日志记录 wall:防御sql注入
# 如果运行时报错:ClassNotFoundException:orgapache.log4j.Priority,则导入log4j依赖即可
filters: stat,wall,log4j
# 自动往数据库建表
#schema:
#- classpath:department.sql
该配置需要结合自己的业务模块单独设置,比如连接池最大连接数,最小连接数,核心连接数(可以结合线程池的参数来理解)具体配置可以从官网地址来了解。
总结
上篇博客说了,博主要搞一个大型的分布式应用,经过昨天一天的奋斗,终于把底层框架给搞完了(涉及到各种底层,想学互联网架构底层的可以参考),由于该项目还没做完(代码还没进行review)所以暂时先不开源,想了解的佬们可以私信我获取地址。

关注我学最先进的互联网技术。















 4089
4089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









