







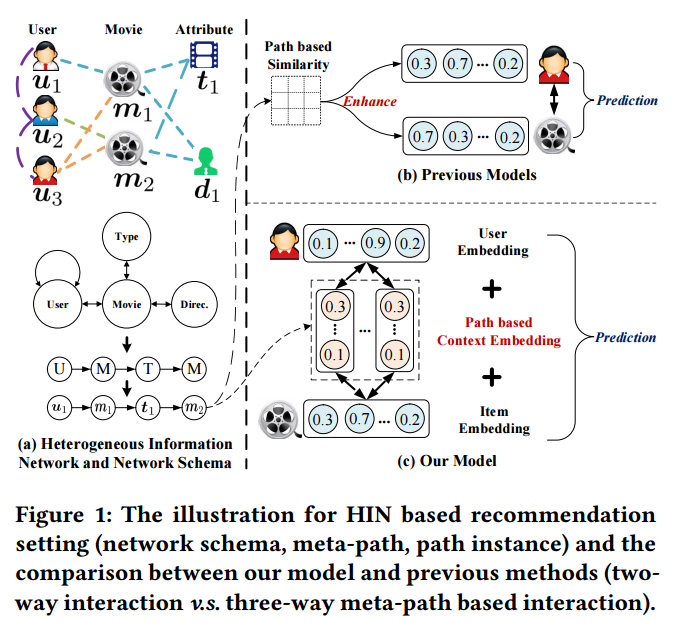
以往的基于HIN的推荐模型存在两个不足。几乎不学习路径或者元路径的显式表达;只考虑user-item交互,而忽视了元路径与涉及到的user-item pair之间的相互影响。本文是来自KDD 2018的工作,不仅学习user和item的表达,还显式的表示user-item的基于元路径的上下文信息,并且提出co-attention机制来相互促进,改善三者的表达效果。
预备知识
隐式反馈:存在n个users U = { u 1 , . . . , u n } \mathcal{U}=\{u_1,...,u_n\} U={u1,...,un}和m个items I = { i 1 , . . . , i m } \mathcal{I}= \{i_1,...,i_m\} I={i1,...,im},定义隐式反馈矩阵 R ∈ R n × m R \in \mathbb{R}^{n\times m} R∈Rn×m的元素 r u , i r_{u,i} ru,i,代表用户u和物品i之间是否有交互。当 r u , i = 1 r_{u,i}=1 ru,i=1,表示观察到user u和item i之间的交互,否则没有观察到。
异构图:异构图与同构信息网络的区别在于顶点和边的类型可能不只一种。
元路径:在异质信息图中,两个节点的连接路径可以是不同的语义,代表一种语义的路径就是一个元路径。在给定的一个元路径 ρ \rho ρ下,存在许多具体的路径,它们被叫做路径实例
元路径上下文:给定一个用户 u 和一个物品 i,基于元路径的上下文是指,连接两个节点的所有路径中,考虑的元路径的路径实例的集合。
例如,用户u1和电影m2可以通过多个元路径连接,这些元路径组成了交互<u1,m2>的上下文。不同元路径表达不同的语义,列如UMUM和UMTM指示用户u1看过m2,理由有二,1)与u1都看过电影m1的用户u3,看过电影m2。2)m2与用户u1看过的电影m2,拥有相同的类型t1。
MCRec
模型学习user items和他们交互上下文的表示。首先,user和item节点分别embedding,然后,使用层次神经网络,将基于元路径的上下文embedding成低维向量。最后,co-attention机制作用在初始学习的user、items和meta-path based context的表达特征上,进一步改善三者的表达。
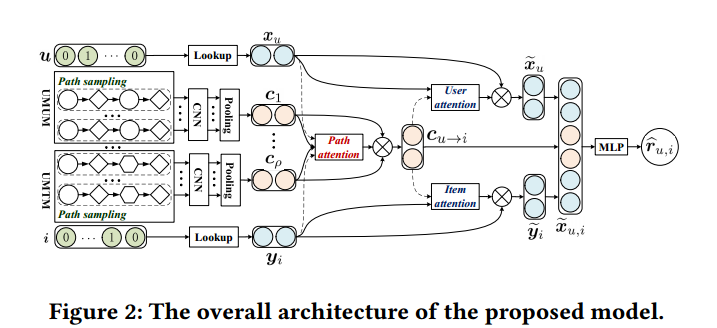
1.User and Item Embedding
构建lookup层将user和item的one-hot向量转化层低维密集向量。给定一个user-item pair
<
u
,
i
>
<u, i>
<u,i>,如果
p
u
∈
R
∣
U
∣
×
1
\mathbf{p}_u \in \mathbb{R}^{|\mathcal{U}|\times 1}
pu∈R∣U∣×1和
q
i
∈
R
∣
I
∣
×
1
\mathbf{q}_i \in \mathbb{R}^{|\mathcal{I}|\times 1}
qi∈R∣I∣×1分别表示用户和物品的one-hot表示,lookup层需要两个对应的参数矩阵
P
∈
R
∣
U
∣
×
d
\mathbf{P}\in \mathbb{R}^{|\mathcal{U}|\times d}
P∈R∣U∣×d和
Q
∈
R
∣
I
∣
×
d
\mathbf{Q}\in \mathbb{R}^{|\mathcal{I}|\times d}
Q∈R∣I∣×d,它们存有用户和物品的潜在因素。这里
d
d
d是用户和物品embedding向量的长度,也可以理解成特征的个数。
∣
U
∣
和
∣
I
∣
|\mathcal{U}|和|\mathcal{I}|
∣U∣和∣I∣分别代表用户和物品的个数。lookup操作如下:
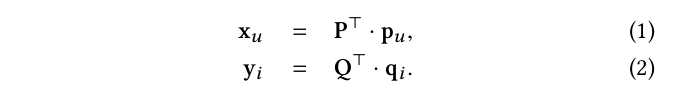
2.表示交互的元路径上下文
生成高质量元路径的实例
首先需要生成高质量的路径实例。在元路径指导下,通过随机游走策略生成路径实例,这是现有的HIN embedding模型采用的方法。他依赖于对out-going节点的均匀采样。这样生成的路径实例低质并且包含太多噪声。这里需要更优秀的方法。
walker漫游的每一步中,如果每一个out-going节点都有一个优先级得分,那么直觉上,选择优先级得分高的节点的概率
应该更大。因为这样的节点代表更紧密的连接,反映更可靠的语义。现在的问题是,怎么定义这个优先级得分。
使用预训练思想,先抛开元路径信息,使用SVDFeature在图上训练每个顶点的表达,计算当前顶点到候选out-going顶点的相似度作为优先度。这个优先度得分直接反映了两个节点之间连接紧密程度。使用SVDFeature学习到的潜在因素,计算两个路径实例的成对节点相似度。对这些节点成对相似度取平均,并据此在所有候选路径实例中排序。对于一个给定的元路径,只取平均相似度最高的K个路径实例。
元路径上下文Embedding
得到元路径的实例之后,使用逐级结构,先学习一个路径实例的embedding,在得到一个元路径的embedding,最后得到元路径集合的embedding。
Path Instance Embedding 一个路径实例是一个节点的序列,序列长度不是固定的,这里作者使用CNN来处理变长节点序列。对于一条来自元路径
ρ
\rho
ρ的路径实例p,concat每个节点的embedding,得到一个embedding矩阵
X
p
∈
R
L
×
d
\mathbf{X}^p \in \mathbb{R}^{L \times d}
Xp∈RL×d,其中,L表示序列的长度,d表示每个节点embedding向量的长度。使用CNN学习路径实例p的embedding
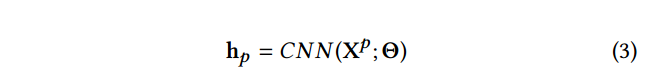
CNN分为卷积层和pooling层,
X
p
\mathbf{X}^p
Xp表示路径实例p的特征,
Θ
\Theta
Θ是CNN模型中的参数。
Meta-Path Embeding 一个元路径
ρ
\rho
ρ可以产生多条路径的实例,前面已经筛选出了K个高质量的路径实例。CNN学习到这K个路径实例的表示为
{
h
p
}
p
=
1
K
\{\mathbf{h}_p\}_{p=1}^K
{hp}p=1K,进一步采用max-pooling操作来得到元路径的表示。那么元路径
ρ
\rho
ρ的表示为:
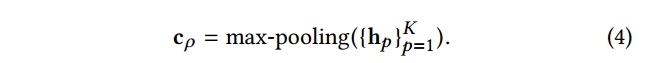
max-pooling操作是作用在K个路径实例的表示上,这样旨在从众多路径实例中捕获重要的维度特征。
Simple Average Embedding for Meta-Path based Context 最后使用简单的average-pooling来得到元路径上下文的表达
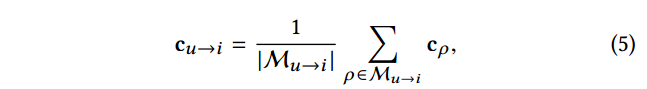
其中,
c
u
→
i
\mathbf{c}_{u\rightarrow i}
cu→i表示元路径上下文的表示,
M
u
→
i
\mathcal{M}_{u \rightarrow i}
Mu→i是当前交互考虑的元路径的集合。
在这个embedding模型中,每个元路径的attention相同,元路径上下文的表示完全依赖于生成的路径实例。在不同交互场景中,由于没有考虑交互涉及到的用户和物品,模型无法从元路径中捕获不同的语义。
3.Co-Attention
Attention for Meta-Path based Context. 在一个交互中,不同的元路径拥有不同的语义,所以在涉及用户和物品的元路径上学习特定于交互的注意力权重。给定一个用户的表示
x
u
\mathbf{x}_u
xu, 物品的表示
y
i
\mathbf{y}_i
yi和上下文的表示
c
ρ
\mathbf{c}_{\rho}
cρ。作者使用两层结构来计算attention
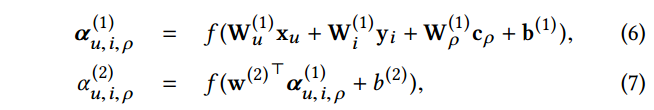
最后使用 softmax 函数,标准化所有元路径的以上atentive score,得到最终的权重
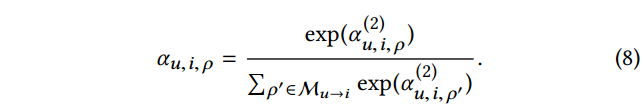
他可以解释成,在u和i之间的交互中,元路径
ρ
\rho
ρ的贡献。得到元路径attention score
α
u
,
i
,
ρ
\alpha_{u,i,\rho}
αu,i,ρ之后,可以通过单条元路径表达的attention score加权求和,给出新的综合元路径上下文表达,
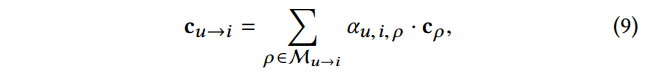
其中,
c
ρ
\mathbf{c}_{\rho}
cρ是学习到的元路径
ρ
\rho
ρ的表示。
Attention for Users and Items. 对于给定的 user 和 item,连接它们的元路径提供了重要的交互上下文。这中交互上下文会影响user 和 item 的原始表示。给定user的原始表示 x u \mathbf{x}_u xu、item的原始表示 y i \mathbf{y}_i yi 和 u到i的元路径上下文表示 c u → i \mathbf{c}_{u \rightarrow i} cu→i。使用单层神经网络计算user 和 item的attention 向量
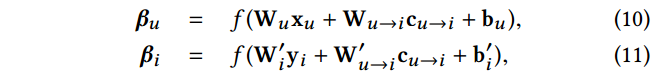
通过原始表示与attention向量的按元素操作,得到最终的user和item的表示

通过组合以上两个attention 组件,模型以一种相互促进的方式,提升了user、item和元路径上下文的原始表示。
实验
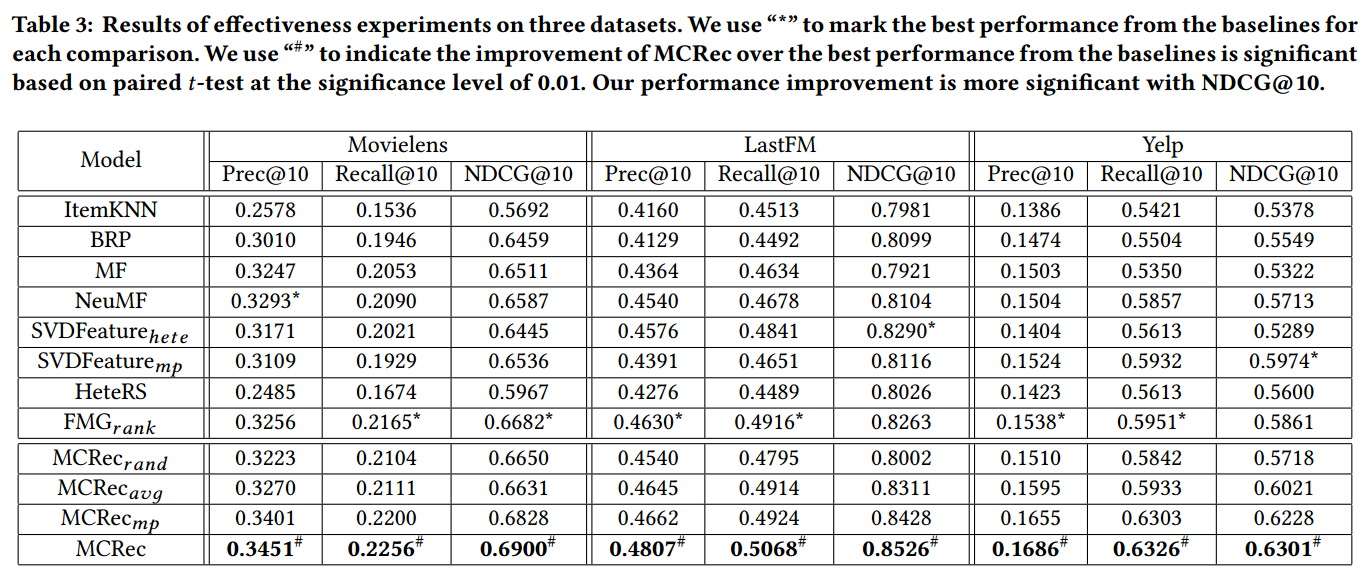
作者在Movielens、LastFM、Yelp三个数据集上测试MCRec方法的效果。对比基于FC的和HIN的两类代表性的推荐方法,体现了MCRec方法的强大表示能力。
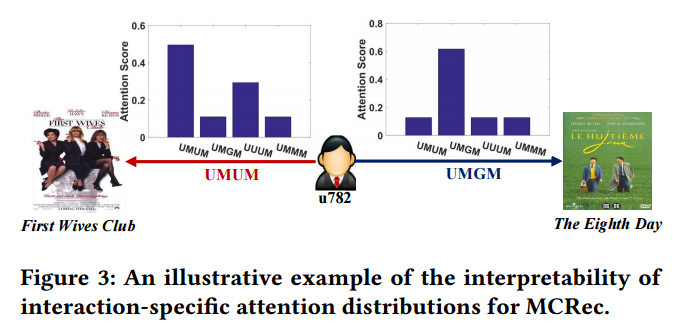
详细分析MCRec方法,发现本方法在三个方面存在着其他方法所没有的优势,可解释性,适应冷启动,直观体现元路径的影响。
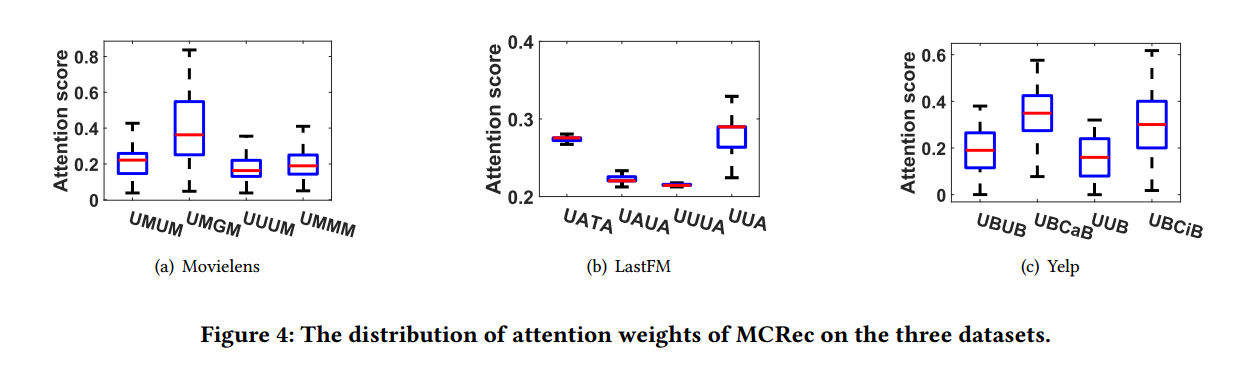
以Movielens 数据中的用户 u782 为例来阐明方法的可解释性。用户的两条交互记录,“First Wives Club” 和 “The Eighth Day”。如图Fig 3,可以看到每个交互对应的attention 分布,它反映了元路径的贡献。第一个交互主要依赖元路径 UMUM 和 UUUM,第二个交互依赖元路径 UMGM。检查原始数据发现,用户u782有至少5个朋友看过“First Wives Club”,这就解释了为什么user引导的元路径UMUM 和 UUUM在交互中起到了重要作用。第二个交互,发现“The Eighth Day”属于u782最喜欢的戏剧类型的电影,这解释了为什么genre导向的元路径 UMGM 起到了主要作用。
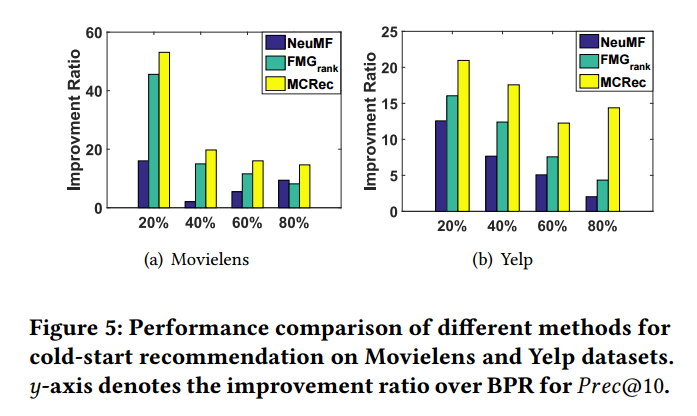
HINs可以有效缓解冷启动问题,因为即使评分记录很少,但是异质交互信息依然在存在。研究推荐系统的冷启动度。分别在不同比率的训练集上训练模型,比较其他方法,可以看到,在所有情况下,MCRec 方法产生了最大的改进。虽然总体来看,随着训练集的增加,改善越来越小。结果显示,MCRec 方法利用了可以有效利用异质网络信息。
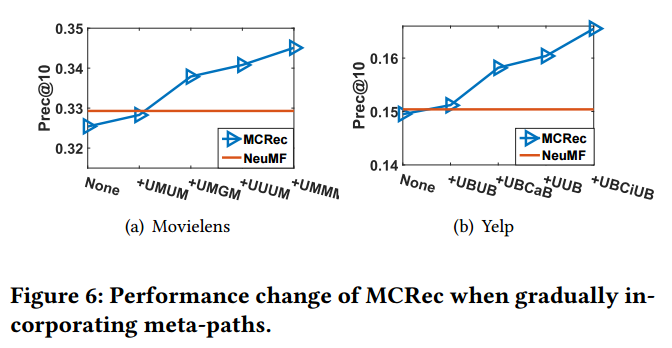
通过元路径的attention分布,可以分析增加不同元路径,对于提升模型效果的影响。结合Fig4和Fig6,发现增加了attention score较高的元路径,加速了对模型整体表现的改善。














 2782
2782











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









