







 本文回顾了视觉推理领域的关键进展,从CLEVR数据集的提出到基于此的多项创新研究,包括程序生成、模块网络等。此外,还介绍了TRANCE数据集及其提出的更复杂视觉推理挑战。
本文回顾了视觉推理领域的关键进展,从CLEVR数据集的提出到基于此的多项创新研究,包括程序生成、模块网络等。此外,还介绍了TRANCE数据集及其提出的更复杂视觉推理挑战。
一、视觉推理的发展
视觉推理 (Visual Reasoning) 概念的兴起是在Li Fei-Fei组提出的 CLEVR 数据集后,被大家广泛认识并且越来越多的人开始研究,大家提出的各种模型都是为了让机器或者是神经网络具有一定的推理能力,能够像人一样进行一些稍微复杂的推理能力,传统的VQA任务上work的模型,如CNN+LSTM这类神经网络模型直接用于该推理数据集效果很差,这基本说明一般的神经网络模型并没有办法通过End-to-End端到端的训练来具备推理能力,为了在CLEVER数据集上取得好的结果,我们必须寻找新的神经网络模型。
在数据集2016.12月提出之后出现了大量的工作,提出了很多全新的idea,首先来说Li Fei-Fei组的文章:
[1] Inferring and Executing Programs for Visual Reasoning,以下是该文章的模型架构图。
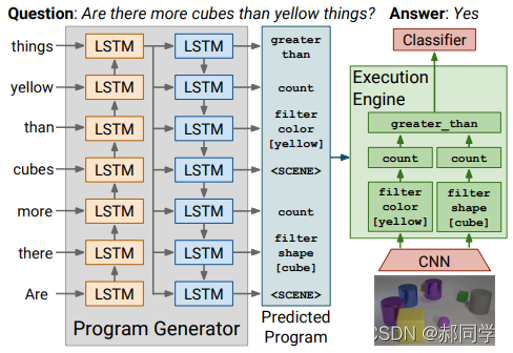
以上的文章有新意的点:Seq2seq Program Generator + Execution Engine 全新的解决方案的提出
具体是1) Take each reasoning as a program. 2) Neural Module Networks! (Dan Klein, UCB ). 3) The two modules are trained separately, followed by reinforcement learning.
本篇文章达到了一个较好的效果,有一个主要的原因使用了数据集的中间推理标签,但经过了训练的神经网络从效果来看,确实是能看出来该网络具有了逻辑推理的能力,这也可以说明神经网络的确可以具有逻辑推理能力。
这篇论文可以说是一小步,如果能不实现额外的监督数据就能让神经网络有逻辑那必然是更好的,毕竟这种监督数据做起来也是很麻烦。
2017年还依托于CLEVR数据集发表了一系列视觉推理的文章,有兴趣的同学可以进一步阅读:
[2] Learning to reason: End-to-end module networks for visual question answering — ICCV2017
[3] A simple neural network module for relational reasoning — DeepMind发表,把CNN提取的feature特征信息当做图像中的物体来看待,然后不同物体两两组合再加上问题的LSTM输出特征,连在一起经过MLP输出一个所谓的关系feature
[3] FiLM: Visual Reasoning with a General Conditioning Layer — AAAI2018 一个可以通用的嵌入到CNN或者是线形层中的结构
[4] Learning Visual Reasoning Without Strong Priors — AAAI2018 在FiLM的基础上进一步改进
[5] Compositional attentionnetworks for machine reasoning — ICLR2018 全可微神经网络架构,参考了计算机架构模式
[6] Murel: Multimodal relational reasoning for visual question answering — CVPR2019
部分参考来自:Here
上述系列的文章是我在做相关视觉推理survey所精读的相关文章,感觉大受启发,还有相关有趣的推理文章大家可以互相分享啊!!!
上述文章没有特意的找Attention机制和外部知识库KB相关的推理论文,有兴趣的朋友可以评论补充噶。这里CodeAntenna有一部分相关的论文大家可以参考!这里是基于外部知识的VQA的相关博客!
二、视觉推理的展望
人工智能的发展很多是来自于数据集的驱动,如果说CLEVR数据集启发了视觉推理领域的发展,最近我看到了由清华和计算所发布的 [7] Transformation Driven Visual Reasoning 一文中提出视觉推理中更加复杂的视觉推理概念—Transformation,这篇工作提出了更加复杂的数据集 TRANCE dataset 以及一种新的encoder-decoder的框架TranceNet来解决提出的数据集。如下所示。
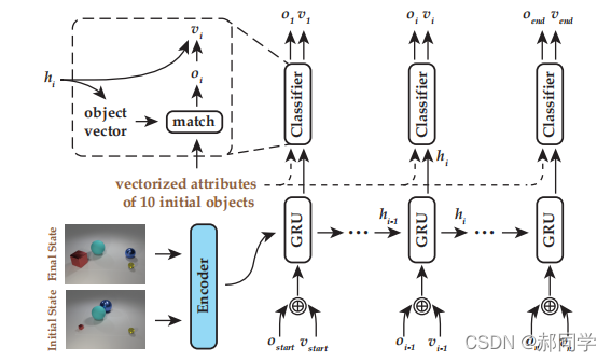
论文链接:CVPR2021
代码及数据集:https://hongxin2019.github.io/TVR
CLEVR 定义问答的范式,来测试机器对图像是否具有空间,关系和其他推理能力。
TRANCE 在CLEVR的基础上提出,给定最初和最终的状态,比如两个图像,目标是推断两个图片状态变换对应的单步或多步变换。
这个数据集的提出是为了解决大多数现有的视觉推理任务都只在静态设置上定义,不能很好地捕捉状态之间的动态的问题,我也粗浅的认为未来的视觉推理也有可能是向着这个方向来改进,不断的解决更加复杂以及动态变换的推理关系,有兴趣的可以详读论文,以此为基础进行相关的研究!我目前只时粗浅的进行了相关Survey,有不严谨的地方还恳请各位指出 Respect!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











