










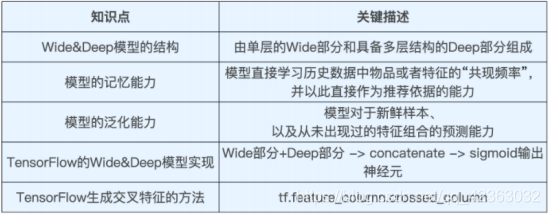
Wide&Deep 模型的结构
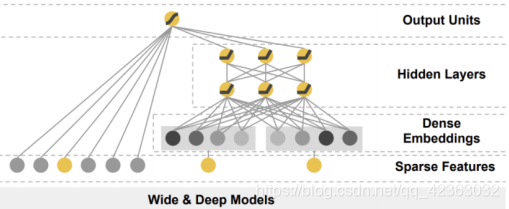
上图就是 Wide&Deep 模型的结构图了,它是由左侧的 Wide 部分和右侧的 Deep 部分组成的。Wide 部分的结构 太简单了,就是把输入层直接连接到输出层,中间没有做任何处理。Deep 层的结构稍复杂,是一个深层的网络。
知道了 Wide&Deep 模型的结构之后,我们先来解决第一个问题,那就是 Google 为什么要创造这样一个混合式的 模型结构呢?这我们还得从 Wide 部分和 Deep 部分的不同作用说起。
简单来说,Wide 部分的主要作用是让模型具有较强的“记忆能力”(Memorization),而 Deep 部分的主要作用是 让模型具有“泛化能力”(Generalization),因为只有这样的结构特点,才能让模型兼具逻辑回归和深度神经网络 的优点,也就是既能快速处理和记忆大量历史行为特征,又具有强大的表达能力,这就是 Google 提出这个模型的 动机。
模型的记忆能力
所谓的 “记忆能力”,可以被宽泛地理解为模型直接学习历史数据中物品或者特征的“共现频率”,并且把它们直接作 为推荐依据的能力 。 就像我们在电影推荐中可以发现一系列的规则,比如,看了 A 电影的用户经常喜欢看电影 B,这种“因为 A 所以 B”式的规则,非常直接也非常有价值。
但这类规则有两个特点:一是数量非常多,一个“记性不好”的推荐模型很难把它们都记住;二是没办法推而广之, 因为这类规则非常具体,没办法或者说也没必要跟其他特征做进一步的组合。就像看了电影 A 的用户 80% 都喜欢 看电影 B,这个特征已经非常强了,我们就没必要把它跟其他特征再组合在一起。
现在,我们就可以回答开头的问题了,为什么模型要有 Wide 部分?就是因为 Wide 部分可以增强模型的记忆能 力,让模型记住大量的直接且重要的规则,这正是单层的线性模型所擅长的。
模型的泛化能力
接下来,我们来谈谈模型的“泛化能力”。“泛化能力”指的是模型对于新鲜样本、以及从未出现过的特征组合的预测 能力。 这怎么理解呢?我们还是来看一个例子。假设,我们知道 25 岁的男性用户喜欢看电影 A,35 岁的女性用户 也喜欢看电影 A。如果我们想让一个只有记忆能力的模型回答,“35 岁的男性喜不喜欢看电影 A”这样的问题,这个 模型就会“说”,我从来没学过这样的知识啊,没法回答你。
这就体现出泛化能力的重要性了。模型有了很强的泛化能力之后,才能够对一些非常稀疏的,甚至从未出现过的情 况作出尽量“靠谱”的预测。
回到刚才的例子,有泛化能力的模型回答“35 岁的男性喜不喜欢看电影 A”这个问题,它思考的逻辑可能是这样的: 从第一条知识,“25 岁的男性用户喜欢看电影 A“中,我们可以学到男性用户是喜欢看电影 A 的。从第二条知 识,“35 岁的女性用户也喜欢看电影 A”中,我们可以学到 35 岁的用户是喜欢看电影 A 的。那在没有其他知识的前 提下,35 岁的男性同时包含了合适的年龄和性别这两个特征,所以他大概率也是喜欢电影 A 的。这就是模型的泛 化能力。
事实上,我们学过的矩阵分解算法,就是为了解决协同过滤“泛化能力”不强而诞生的。因为协同过滤只会“死板”地 使用用户的原始行为特征,而矩阵分解因为生成了用户和物品的隐向量,所以就可以计算任意两个用户和物品之间 的相似度了。这就是泛化能力强的另一个例子。
Wide&Deep 模型的应用场景
Wide&Deep 模型是由 Google 的应用商店团队 Google Play 提出的,在 Google Play 为用户推荐 APP 这样的应用 场景下,Wide&Deep 模型的推荐目标就显而易见了,就是应该尽量推荐那些用户可能喜欢,愿意安装的应用。那 具体到 Wide&Deep 模型中,Google Play 团队是如何为 Wide 部分和 Deep 部分挑选特征的呢?下面,我们就一 起来看看。
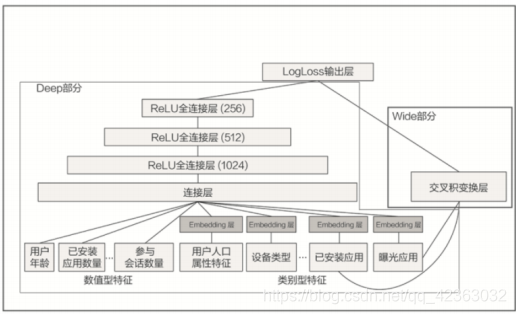
我们先来看上图,它补充了 Google Play Wide&Deep 模型的细节,让我们可以清楚地看到各部分用到的特征是 什么。我们先从右边 Wide 部分的特征看起。这部分很简单,只利用了两个特征的交叉,这两个特征是“已安装应 用”和“当前曝光应用”。这样一来,Wide 部分想学到的知识就非常直观啦,就是希望记忆好“如果 A 所以 B”这样的 简单规则。在 Google Play 的场景下,就是希望记住“如果用户已经安装了应用 A,是否会安装 B”这样的规则。
接着,我们再来看看左边的 Deep 部分,它就是一个非常典型的 Embedding+MLP 结构了。我们看到其中的输入 特征很多,有用户年龄、属性特征、设备类型,还有已安装应用的 Embedding 等等。我们把这些特征一股脑地放 进多层神经网络里面去学习之后,它们互相之间会发生多重的交叉组合,这最终会让模型具备很强的泛化能力。
比如说,我们把用户年龄、人口属性和已安装应用组合起来。假设,样本中有 25 岁男性安装抖音的记录,也有 35 岁女性安装抖音的记录,那我们该怎么预测 25 岁女性安装抖音的概率呢?这就需要用到已有特征的交叉来实现 了。虽然我们没有 25 岁女性安装抖音的样本,但模型也能通过对已有知识的泛化,经过多层神经网络的学习,来 推测出这个概率。
总的来说,Wide&Deep 通过组合 Wide 部分的线性模型和 Deep 部分的深度网络,取各自所长,就能得到一个综 合能力更强的组合模型。
TensorFlow 实现
# wide and deep model architecture
# deep part for all input features
deep = tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns)(inputs)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
deep = tf.keras.layers.Dense(128, activation='relu')(deep)
# wide part for cross feature
wide = tf.keras.layers.DenseFeatures(crossed_feature)(inputs)
both = tf.keras.layers.concatenate([deep, wide])
output_layer = tf.keras.layers.Dense(1, activation='sigmoid')(both)
model = tf.keras.Model(inputs, output_layer)
movie_feature = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
rated_movie_feature = tf.feature_column.categorical_column_with_identity(key='userRatedMovie1', num_buckets=1001)
crossed_feature = tf.feature_column.crossed_column([movie_feature, rated_movie_feature], 10000)
Pytorch实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tqdm import tqdm
import datetime
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchkeras import summary, Model
from sklearn.metrics import roc_auc_score
import warnings
warnings.filterwarnings('ignore')
# ## 数据准备
# In[3]:
file_path = 'G:\A_实训前置1\推荐系统基础1804A\paper\推荐算法代码\code\widedeep/preprocessed_data/'
# In[4]:
def prepared_data(file_path):
# 读入训练集,验证集和测试集
train = pd.read_csv(file_path + 'train_set.csv')
val = pd.read_csv(file_path + 'val_set.csv')
test = pd.read_csv(file_path + 'test_set.csv')
trn_x, trn_y = train.drop(columns='Label').values, train['Label'].values
val_x, val_y = val.drop(columns='Label').values, val['Label'].values
test_x = test.values
fea_col = np.load(file_path + 'fea_col.npy', allow_pickle=True)
return fea_col, (trn_x, trn_y), (val_x, val_y), test_x
# In[5]:
fea_cols, (trn_x, trn_y), (val_x, val_y), test_x = prepared_data(file_path)
# In[6]:
# 把数据构建成数据管道
dl_train_dataset = TensorDataset(torch.tensor(trn_x).float(), torch.tensor(trn_y).float())
dl_val_dataset = TensorDataset(torch.tensor(val_x).float(), torch.tensor(val_y).float())
dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=32)
dl_val = DataLoader(dl_val_dataset, shuffle=True, batch_size=32)
# In[7]:
# 看一下数据
for b in iter(dl_train):
print(b[0].shape, b[1])
break
# ## 构建模型
# 这里依然是使用继承nn.Module基类构建模型, 并辅助应用模型容器进行封装, Wide&Deep的模型结构如下:
#
# 
#
# 这个模型搭建起来,相对比较简单, 主要分为wide部分, Deep部分和两者的拼接
# In[8]:
class Linear(nn.Module):
"""
Linear part
"""
def __init__(self, input_dim):
super(Linear, self).__init__()
self.linear = nn.Linear(in_features=input_dim, out_features=1)
def forward(self, x):
return self.linear(x)
class Dnn(nn.Module):
"""
Dnn part
"""
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units: 列表, 每个元素表示每一层的神经单元个数, 比如[256, 128, 64], 两层网络, 第一层神经单元128, 第二层64, 第一个维度是输入维度
dropout: 失活率
"""
super(Dnn, self).__init__()
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(p=dropout)
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
# In[9]:
class WideDeep(nn.Module):
def __init__(self, feature_columns, hidden_units, dnn_dropout=0.):
super(WideDeep, self).__init__()
self.dense_feature_cols, self.sparse_feature_cols = feature_columns
# embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(i): nn.Embedding(num_embeddings=feat['feat_num'], embedding_dim=feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_cols)
})
hidden_units.insert(0, len(self.dense_feature_cols) + len(self.sparse_feature_cols)*self.sparse_feature_cols[0]['embed_dim'])
self.dnn_network = Dnn(hidden_units)
self.linear = Linear(len(self.dense_feature_cols))
self.final_linear = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
dense_input, sparse_inputs = x[:, :len(self.dense_feature_cols)], x[:, len(self.dense_feature_cols):]
sparse_inputs = sparse_inputs.long()
sparse_embeds = [self.embed_layers['embed_'+str(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])]
sparse_embeds = torch.cat(sparse_embeds, axis=-1)
dnn_input = torch.cat([sparse_embeds, dense_input], axis=-1)
# Wide
wide_out = self.linear(dense_input)
# Deep
deep_out = self.dnn_network(dnn_input)
deep_out = self.final_linear(deep_out)
# out
outputs = F.sigmoid(0.5 * (wide_out + deep_out))
return outputs
# In[10]:
# 建立模型
hidden_units = [256, 128, 64]
dnn_dropout = 0.
model = WideDeep(fea_cols, hidden_units, dnn_dropout)
summary(model, input_shape=(trn_x.shape[1],))
# In[11]:
# 测试一下模型
for fea, label in iter(dl_train):
out = model(fea)
print(out)
break
# ## 模型的训练
# In[21]:
# 模型的相关设置
def auc(y_pred, y_true):
pred = y_pred.data
y = y_true.data
return roc_auc_score(y, pred)
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
metric_func = auc
metric_name = 'auc'
# In[31]:
# 脚本训练风格
epochs = 10
log_step_freq = 10
dfhistory = pd.DataFrame(columns=['epoch', 'loss', metric_name, 'val_loss', 'val_'+metric_name])
print('start_training.........')
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print('========'*8 + '%s' %nowtime)
for epoch in range(1, epochs+1):
# 训练阶段
model.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features, labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = model(features)
predictions = predictions.squeeze(-1)
loss = loss_func(predictions, labels)
try:
metric = metric_func(predictions, labels)
except ValueError:
pass
# 反向传播
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
print(("[step=%d] loss: %.3f, " + metric_name + ": %.3f") % (step, loss_sum/step, metric_sum/step))
# 验证阶段
model.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features, labels) in enumerate(dl_val, 1):
with torch.no_grad():
predictions = model(features)
predictions = predictions.squeeze(-1)
val_loss = loss_func(predictions, labels)
try:
val_metric = metric_func(predictions, labels)
except ValueError:
pass
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 记录日志
info = (epoch, loss_sum/step, metric_sum/step, val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印日志
print(("\nEPOCH=%d, loss=%.3f, " + metric_name + " = %.3f, val_loss=%.3f, " + "val_" + metric_name + " = %.3f") %info)
nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print('\n' + '=========='* 8 + '%s' %nowtime)
print('Finished Training')
# In[30]:
dfhistory
# In[14]:
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
# 观察损失和准确率的变化
plot_metric(dfhistory,"loss")
plot_metric(dfhistory,"auc")
# 出现过拟合了,其实,并且比较严重
# In[15]:
# 预测
y_pred_probs = model(torch.tensor(test_x).float())
y_pred = torch.where(y_pred_probs>0.5, torch.ones_like(y_pred_probs), torch.zeros_like(y_pred_probs))
# In[16]:
print(y_pred.data)



















 3419
3419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











