









参考自:
https://blog.csdn.net/weixin_41485334/article/details/104393236
自定义循环训练,加入评估
# coding:utf-8
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
from model import FGCNN
from utils import create_criteo_dataset
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras import optimizers, losses, metrics, layers
import time
import pandas as pd
''' 用于 spare field embedding '''
def sparseFeature(feat, vocabulary_size, embed_dim):
return {'spare': feat, 'vocabulary_size': vocabulary_size, 'embed_dim': embed_dim}
''' 用于 dense field embedding '''
def denseFeature(feat):
return {'dense': feat}
class DNN_model(Model):
def __init__(self, spare_feature_columns, hidden_units, droup_out):
super(DNN_model, self).__init__()
self.sparse_feature_columns = spare_feature_columns
self.embed_layers = {
'embed_' + str(i): layers.Embedding(feat['vocabulary_size'], feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_columns)
}
self.DNN = tf.keras.Sequential()
for hidden in hidden_units:
self.DNN.add(layers.Dense(hidden, activation='relu'))
self.DNN.add(layers.Dropout(droup_out))
self.output_layer = layers.Dense(1)
def call(self, inputs, training=None, mask=None):
dense_inputs, sparse_inputs = inputs[:, :13], inputs[:, 13:]
sparse_embed = tf.concat([self.embed_layers['embed_{}'.format(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])], axis=1)
x = tf.concat([dense_inputs, sparse_embed], axis=1)
dnn_out = self.DNN(x)
return tf.nn.sigmoid(self.output_layer(dnn_out))
@tf.function
def train_step(x_batch_train, y_batch_train):
# 打开GradientTape以记录正向传递期间运行的操作,这将启用自动区分
with tf.GradientTape() as tape:
y_pred = model(x_batch_train) # FP
y_pred = tf.squeeze(y_pred)
loss = losses.binary_crossentropy(y_batch_train, y_pred) # 计算这个mini batch的损失
loss = tf.reduce_mean(loss)
# 使用GradientTape自动获取可训练变量相对于损失的梯度
grads = tape.gradient(loss, model.trainable_variables)
# 更新梯度,梯度下降
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
train_loss.update_state(loss)
train_acc.update_state(y_batch_train, y_pred)
train_auc.update_state(y_batch_train, y_pred)
train_precision.update_state(y_batch_train, y_pred)
train_recall.update_state(y_batch_train, y_pred)
@tf.function
def val_step(x_batch_val, y_batch_val):
y_pred = model(x_batch_val)
y_pred = tf.squeeze(y_pred)
loss = losses.binary_crossentropy(y_batch_val, y_pred)
loss = tf.reduce_mean(loss)
val_loss.update_state(loss)
val_acc.update_state(y_batch_val, y_pred)
val_auc.update_state(y_batch_val, y_pred)
val_precision.update_state(y_batch_val, y_pred)
val_recall.update_state(y_batch_val, y_pred)
if __name__ == '__main__':
file_path = '/Users/wangguisen/Documents/markdowns/推荐(广告)-精排-CTR模型/code/data/criteo_sampled_data_OK.csv'
data = pd.read_csv(file_path)
data = shuffle(data, random_state=42)
data_X = data.iloc[:, 1:]
data_y = data['label'].values
dense_features = ['I' + str(i) for i in range(1, 14)]
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_feature_columns = [denseFeature(feat) for feat in dense_features]
spare_feature_columns = [sparseFeature(feat, data_X[feat].nunique(), 4) for feat in sparse_features]
tmp_X, test_X, tmp_y, test_y = train_test_split(data_X, data_y, test_size=0.05, random_state=42, stratify=data_y)
train_X, val_X, train_y, val_y = train_test_split(tmp_X, tmp_y, test_size=0.05, random_state=42, stratify=tmp_y)
print(len(train_X))
print(len(val_y))
print(len(test_y))
batch_size = 2000
train_dataset = tf.data.Dataset.from_tensor_slices((train_X, train_y)).batch(batch_size)
val_dataset = tf.data.Dataset.from_tensor_slices((val_X, val_y)).batch(batch_size)
model = DNN_model(spare_feature_columns, (64, 128, 128), 0.5)
optimizer = optimizers.Adam(0.001)
# 定义训练的损失和评估
train_loss = metrics.Mean(name='train_loss')
train_acc = metrics.BinaryAccuracy(name='train_acc')
train_auc = metrics.AUC(num_thresholds=498, name='train_auc')
train_precision = metrics.Precision(name='train_precision')
train_recall = metrics.Recall(name='trian_recall')
# 定义验证的损失和评估
val_loss = metrics.Mean(name='val_loss')
val_acc = metrics.BinaryAccuracy(name='val_acc')
val_auc = metrics.AUC(num_thresholds=498, name='val_auc')
val_precision = metrics.Precision(name='val_precision')
val_recall = metrics.Recall(name='val_recall')
epochs = 3
for epoch in range(1, epochs + 1):
start = time.time()
print('Epoch %s / %s' % (epoch, epochs))
for batch, (x_batch_train, y_batch_train) in enumerate(train_dataset, 1):
train_step(x_batch_train, y_batch_train)
# # 每200 batches打印一次.
# if batch % 200 == 0:
# print('Training loss (for one batch) at step %s: %s' % (batch, train_loss.result().numpy()))
for batch, (x_batch_val, y_batch_val) in enumerate(val_dataset, 1):
val_step(x_batch_val, y_batch_val)
end = time.time()
run_epoch_time = int((end - start) % 60)
print(
'ETA : %ss, loss : %s, accuracy: %s, auc: %s, precision: %s, recall: %s | val_loss : %s, val_accuracy: %s, val_auc: %s, val_precision: %s, val_recall: %s'
% (
run_epoch_time, train_loss.result().numpy(), train_acc.result().numpy(), train_auc.result().numpy(),
train_precision.result().numpy(), train_recall.result().numpy(),
val_loss.result().numpy(), val_acc.result().numpy(), val_auc.result().numpy(),
val_precision.result().numpy(), val_recall.result().numpy()))
# 每个epoch结束后重置状态
train_loss.reset_states()
train_acc.reset_states()
train_auc.reset_states()
train_precision.reset_states()
train_recall.reset_states()
val_loss.reset_states()
val_acc.reset_states()
val_auc.reset_states()
val_precision.reset_states()
val_recall.reset_states()
Epoch 1 / 3
ETA : 13s, loss : 0.5064437, accuracy: 0.7613524, auc: 0.72211564, precision: 0.61324364, recall: 0.18712182 | val_loss : 0.47642323, val_accuracy: 0.7754667, val_auc: 0.76726425, val_precision: 0.64394903, val_recall: 0.27672094
Epoch 2 / 3
ETA : 8s, loss : 0.41599652, accuracy: 0.8123706, auc: 0.8367436, precision: 0.6962574, recall: 0.475595 | val_loss : 0.5233103, val_accuracy: 0.75556666, val_auc: 0.73736054, val_precision: 0.5327738, val_recall: 0.36485562
Epoch 3 / 3
ETA : 8s, loss : 0.31700167, accuracy: 0.8591446, auc: 0.9079631, precision: 0.7951273, recall: 0.6069988 | val_loss : 0.5988434, val_accuracy: 0.7462334, val_auc: 0.717707, val_precision: 0.5066857, val_recall: 0.38894212
在此基础上训练可视化
# coding:utf-8
from sklearn.model_selection import train_test_split
from sklearn.utils import shuffle
import matplotlib.pyplot as plt
from model import FGCNN
from utils import create_criteo_dataset
import tensorflow as tf
from tensorflow.keras import Model
from tensorflow.keras import optimizers, losses, metrics, layers
import time
import pandas as pd
''' 用于 spare field embedding '''
def sparseFeature(feat, vocabulary_size, embed_dim):
return {'spare': feat, 'vocabulary_size': vocabulary_size, 'embed_dim': embed_dim}
''' 用于 dense field embedding '''
def denseFeature(feat):
return {'dense': feat}
class DNN_model(Model):
def __init__(self, spare_feature_columns, hidden_units, droup_out):
super(DNN_model, self).__init__()
self.sparse_feature_columns = spare_feature_columns
self.embed_layers = {
'embed_' + str(i): layers.Embedding(feat['vocabulary_size'], feat['embed_dim'])
for i, feat in enumerate(self.sparse_feature_columns)
}
self.DNN = tf.keras.Sequential()
for hidden in hidden_units:
self.DNN.add(layers.Dense(hidden, activation='relu'))
self.DNN.add(layers.Dropout(droup_out))
self.output_layer = layers.Dense(1)
def call(self, inputs, training=None, mask=None):
dense_inputs, sparse_inputs = inputs[:, :13], inputs[:, 13:]
sparse_embed = tf.concat([self.embed_layers['embed_{}'.format(i)](sparse_inputs[:, i]) for i in range(sparse_inputs.shape[1])], axis=1)
x = tf.concat([dense_inputs, sparse_embed], axis=1)
dnn_out = self.DNN(x)
return tf.nn.sigmoid(self.output_layer(dnn_out))
@tf.function
def train_step(x_batch_train, y_batch_train):
# 打开GradientTape以记录正向传递期间运行的操作,这将启用自动区分
with tf.GradientTape() as tape:
y_pred = model(x_batch_train) # FP
y_pred = tf.squeeze(y_pred)
loss = losses.binary_crossentropy(y_batch_train, y_pred) # 计算这个mini batch的损失
loss = tf.reduce_mean(loss)
# 使用GradientTape自动获取可训练变量相对于损失的梯度
grads = tape.gradient(loss, model.trainable_variables)
# 更新梯度,梯度下降
optimizer.apply_gradients(grads_and_vars=zip(grads, model.trainable_variables))
train_loss.update_state(loss)
train_acc.update_state(y_batch_train, y_pred)
train_auc.update_state(y_batch_train, y_pred)
train_precision.update_state(y_batch_train, y_pred)
train_recall.update_state(y_batch_train, y_pred)
@tf.function
def val_step(x_batch_val, y_batch_val):
y_pred = model(x_batch_val)
y_pred = tf.squeeze(y_pred)
loss = losses.binary_crossentropy(y_batch_val, y_pred)
loss = tf.reduce_mean(loss)
val_loss.update_state(loss)
val_acc.update_state(y_batch_val, y_pred)
val_auc.update_state(y_batch_val, y_pred)
val_precision.update_state(y_batch_val, y_pred)
val_recall.update_state(y_batch_val, y_pred)
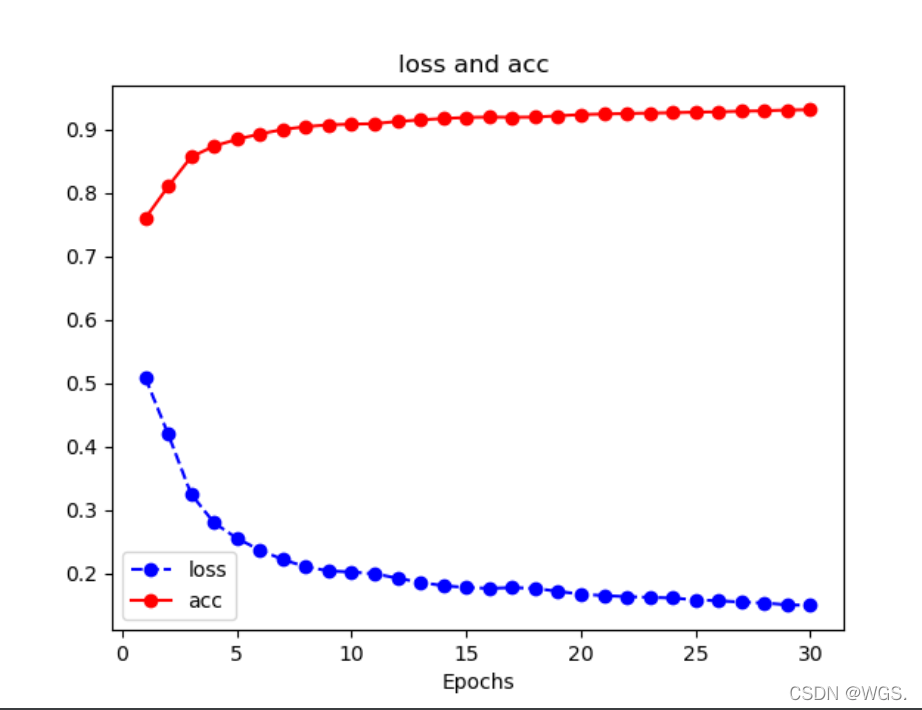
def plot_metric(train_polt_list, val_polt_list, metric, epochs):
epochs = [int(i + 1) for i in range(epochs)]
plt.plot(epochs, train_polt_list, 'bo--')
plt.plot(epochs, val_polt_list, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_" + metric, 'val_'+metric])
plt.show()
def plot_metric2(train_loss_list, train_acc_list, metric, epochs):
epochs = [int(i + 1) for i in range(epochs)]
plt.plot(epochs, train_loss_list, 'bo--')
plt.plot(epochs, train_acc_list, 'ro-')
plt.title('loss and acc ')
plt.xlabel("Epochs")
# plt.ylabel(metric)
plt.legend([metric[0], metric[1]])
plt.show()
if __name__ == '__main__':
file_path = '/Users/wangguisen/Documents/markdowns/推荐(广告)-精排-CTR模型/code/data/criteo_sampled_data_OK.csv'
data = pd.read_csv(file_path)
data = shuffle(data, random_state=42)
data_X = data.iloc[:, 1:]
data_y = data['label'].values
dense_features = ['I' + str(i) for i in range(1, 14)]
sparse_features = ['C' + str(i) for i in range(1, 27)]
dense_feature_columns = [denseFeature(feat) for feat in dense_features]
spare_feature_columns = [sparseFeature(feat, data_X[feat].nunique(), 4) for feat in sparse_features]
tmp_X, test_X, tmp_y, test_y = train_test_split(data_X, data_y, test_size=0.05, random_state=42, stratify=data_y)
train_X, val_X, train_y, val_y = train_test_split(tmp_X, tmp_y, test_size=0.05, random_state=42, stratify=tmp_y)
print(len(train_X))
print(len(val_y))
print(len(test_y))
batch_size = 2000
train_dataset = tf.data.Dataset.from_tensor_slices((train_X, train_y)).batch(batch_size)
val_dataset = tf.data.Dataset.from_tensor_slices((val_X, val_y)).batch(batch_size)
model = DNN_model(spare_feature_columns, (64, 128, 128), 0.5)
optimizer = optimizers.Adam(0.001)
# 定义训练的损失和评估
train_loss = metrics.Mean(name='train_loss')
train_acc = metrics.BinaryAccuracy(name='train_acc')
train_auc = metrics.AUC(num_thresholds=498, name='train_auc')
train_precision = metrics.Precision(name='train_precision')
train_recall = metrics.Recall(name='trian_recall')
# 定义验证的损失和评估
val_loss = metrics.Mean(name='val_loss')
val_acc = metrics.BinaryAccuracy(name='val_acc')
val_auc = metrics.AUC(num_thresholds=498, name='val_auc')
val_precision = metrics.Precision(name='val_precision')
val_recall = metrics.Recall(name='val_recall')
# 可视化训练过程
train_loss_polt = []
train_acc_polt = []
epochs = 30
for epoch in range(1, epochs + 1):
start = time.time()
print('Epoch %s / %s' % (epoch, epochs))
for batch, (x_batch_train, y_batch_train) in enumerate(train_dataset, 1):
train_step(x_batch_train, y_batch_train)
# # 每200 batches打印一次.
# if batch % 200 == 0:
# print('Training loss (for one batch) at step %s: %s' % (batch, train_loss.result().numpy()))
for batch, (x_batch_val, y_batch_val) in enumerate(val_dataset, 1):
val_step(x_batch_val, y_batch_val)
end = time.time()
run_epoch_time = int((end - start) % 60)
print(
'ETA : %ss, loss : %s, accuracy: %s, auc: %s, precision: %s, recall: %s | val_loss : %s, val_accuracy: %s, val_auc: %s, val_precision: %s, val_recall: %s'
% (
run_epoch_time, train_loss.result().numpy(), train_acc.result().numpy(), train_auc.result().numpy(),
train_precision.result().numpy(), train_recall.result().numpy(),
val_loss.result().numpy(), val_acc.result().numpy(), val_auc.result().numpy(),
val_precision.result().numpy(), val_recall.result().numpy()))
train_loss_polt.append(train_loss.result().numpy())
train_acc_polt.append(train_acc.result().numpy())
# 每个epoch结束后重置状态
train_loss.reset_states()
train_acc.reset_states()
train_auc.reset_states()
train_precision.reset_states()
train_recall.reset_states()
val_loss.reset_states()
val_acc.reset_states()
val_auc.reset_states()
val_precision.reset_states()
val_recall.reset_states()
plot_metric2(train_loss_polt, train_acc_polt, ['loss', 'acc'], epochs)
https://blog.csdn.net/qq_42363032/article/details/122167732



















 2793
2793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











