







统计推断的三大基本形式:
- 抽样分布
- 参数估计(点估计、区间估计)
- 假设检验(参数检验、非参数检验)
一、 置信区间
在实际中,我们通常得不到总体在某方面的真值,比如总体均值。或者说,如果我们现在要估计公司某个产品的用户满意度,就可以通过抽样调查的方式获取一部分样本,然后根据样本估计出所有用户的满意程度范围。
一般这种估计需要有比较高的“可信程度”,比如要有 90% 的可信度(过高的可信程度需要更多的样本,导致抽样成本增高)
基本概念
参数估计包括:点估计与区间估计
点估计实际上就是利用样本算出一个值来近似代替总体真值,这个真值可能就在代替值的附近,但是点估计仅仅是未知参数的一个近似值,它并没有反映出这个近似值的误差范围,或者说,相信这个近似值的可靠度。
因此,在点估计的基础上,可以使用区间的形式来估计总体真值,在构造这个区间的同时,还需要给出一定的可靠程度,让其以较高的把握相信这个区间包含总体真值。
区间估计的定义:
若在某总体 F θ ( x ) F_{\theta}\left( x \right) Fθ(x) 抽取一个样本 x = ( x 1 , x 2 , ⋯ , x n ) \boldsymbol{x}=\left( x_1,x_2,\cdots ,x_n \right) x=(x1,x2,⋯,xn),基于样本构造出在参数空间上取值的两个统计量 θ ^ L ( x ) 、 θ ^ U ( x ) \hat{\theta}_L\left( x \right) \text{、}\hat{\theta}_U\left( x \right) θ^L(x)、θ^U(x),且满足
θ ^ L ( x ) < θ ^ U ( x ) \hat{\theta}_L\left( x \right) <\hat{\theta}_U\left( x \right) θ^L(x)<θ^U(x)
则称随机区间 [ θ ^ L ( x ) , θ ^ U ( x ) ] \left[ \hat{\theta}_L\left( x \right) \text{,}\hat{\theta}_U\left( x \right) \right] [θ^L(x),θ^U(x)] 为参数 θ \theta θ 的一个区间估计。
该区间覆盖参数 θ \theta θ 的概率 P ( θ ^ L ≤ θ ≤ θ ^ U ) P\left( \hat{\theta}_L\le \theta \le \hat{\theta}_U \right) P(θ^L≤θ≤θ^U) 称为置信度
也可称为 “置信概率”、“可靠程度”、“置信水平”
统计上通常把置信水平记作 1 − α 1-\alpha 1−α,这里的 α \alpha α 称为显著性水平,也是后面要讲到的犯第一类错误的概率。通常取 α = 0..05 \alpha=0..05 α=0..05 即 1 − α = 0.95 1-\alpha=0.95 1−α=0.95 。 这个95就是经常会提到的 95% 置信区间。
置信区间的定义
设 θ \theta θ 是总体的一个参数, x 1 , x 2 , ⋯ , x n x_1,x_2,\cdots ,x_n x1,x2,⋯,xn是来自该总体的一个样本,对给定的显著性水平 α \alpha α ,根据样本得到两个样本统计量
θ
^
L
(
x
1
,
x
2
,
⋯
,
x
n
)
、
θ
^
U
(
x
1
,
x
2
,
⋯
,
x
n
)
\hat{\theta}_L\left( x_1,x_2,\cdots ,x_n \right) \text{、}\hat{\theta}_U\left( x_1,x_2,\cdots ,x_n \right)
θ^L(x1,x2,⋯,xn)、θ^U(x1,x2,⋯,xn)
若满足
P
θ
(
θ
^
L
≤
θ
≤
θ
^
U
)
=
1
−
α
P_{\theta}\left( \hat{\theta}_L\le \theta \le \hat{\theta}_U \right) = 1-\alpha
Pθ(θ^L≤θ≤θ^U)=1−α
则称随机区间 [ θ ^ L , θ ^ U ] \left[ \hat{\theta}_L\text{,}\hat{\theta}_U \right] [θ^L,θ^U] 为参数 θ \theta θ 的置信水平为 1 − α 1-\alpha 1−α 的置信区间。
可以看出
置信区间就是由样本统计量所构造的总体参数的估计区间。 其区间的最小值称为置信下限,区间最大值称为置信上限。
例,正态总体的置信区间,在 1 − α 1-\alpha 1−α 的置信度下,总体的均值会落在置信区间范围内。

置信水平 1 − α 1-\alpha 1−α 的含义:
设法构造一个随机区间 [ θ ^ L , θ ^ U ] \left[ \hat{\theta}_L\text{,}\hat{\theta}_U \right] [θ^L,θ^U],它能盖住未知参数 θ \theta θ 的概率至少为 1 − α 1-\alpha 1−α 。这个区间会随着样本观察值的不同而不同,但100次运用这个区间估计,约有 100 ( 1 − α ) 100\left( 1-\alpha \right) 100(1−α)个区间能盖住 θ \theta θ ,或者说约有 100 ( 1 − α ) 100\left( 1-\alpha \right) 100(1−α)个区间含有 θ \theta θ ,也即大约有 100 α 100\alpha 100α 个区间不含 θ \theta θ (总体参数) 。
置信区间的误区 或者说 如何理解 95% 置信区间
通过区间估计得到的置信区间含义,不能理解为总体真值落入这个区间的概率!
可以理解为:
对于给定的置信水平
1
−
α
=
0.95
1-\alpha=0.95
1−α=0.95,现独立重复的进行100次试验,每次试验都会得到不同的样本,因此可以构造出100个不同的置信区间,这其中大约有95个置信区间包含总体真值,至于到底哪些区间包含,谁也不知道。
更简单的说
抽取100个样本,根据每个样本构造一个置信区间,这样由100个样本构造的总体参数的100个置信区间中,95%的区间包含了总体参数的真值,而5%没包含
判断置信区间优势的标准(好的置信区间的特性):置信度越高越好;置信区间宽度越小越好。
影响区间宽度的因素
1)总体数据的离散程度,用 s s s 来测度
2)样本容量:当置信水平固定时,置信区间的宽度随着样本容量的增大而减小,换言之,较大的样本所提供的有关总体的信息要比小样本多。
3)置信水平 1 − α 1-\alpha 1−α,影响 z z z 的大小:置信水平越大, z z z 越大
置信区间的分类
1、对正态总体均值 μ 的区间估计。
即已知样本的平均值,用样本均值估计总体均值在特定置信度下的置信区间。
1) 已知样本标准差等于总体标准差
2) 未知总体标准差
2、对正态总体方差 σ2 的区间估计
即已知样本的标准差,用样本标准差估计总体标准差在一定置信度下的置信区间。
1) 已知样本均值于总体均值
2) 未知总体标准差
3、对两个正态总体均值差的区间估计
1) 已知两个总体标准差
2) 未知总体标准差,但假设σ1=σ2 ,其中σ1 与σ2分别为两个正态分布的总体标准差
4、对两个正态总体方差比的区间估计。
1) 已知两个总体的均值
2) 未知总体均值


二、假设检验
假设检验概念
事先对总体参数或分布形式作出某种假设,然后利用样本信息来以一定的概率判断原假设是否成立。
即
假设检验要判断的是样本数据是否提供了不利于假设的证据。
假设检验要处理的是有关总体的假设
假设检验包括参数检验与非参数检验,参考:参数检验与【非参数检验】及Python/SPSS/R/Stata实现
假设检验的基本思想
引用百度百科的说法

假设检验的基本思想实质上是带有某种概率性质的小概率反证法。
为了检验一个假设 H 0 H_0 H0 是否正确,首先假设该假设 H 0 H_0 H0 是正确的,然后根据抽取到的样本对假设 H 0 H_0 H0 作出不拒绝或拒绝的决策。
- 如果可能性很小(小概率事件),在一次试验中本不该得到,现在居然得到了,说明我们的假设有问题,拒绝之;
- 如果有可能得到现在的结果,故根据现有的样本无法拒绝事先的假设(没理由拒绝原来的假设)
小概率反证法例子
比如说,现在有两个盒子,第一个盒子有99个白球1个红球,第二个盒子有99个红球1个白球

现从两个盒子中随机取出一个,问这个盒子里是99个白球还是99个红球?
假设:这个盒子里有99个白球!
现从中随机摸出一个球,发现是红球,
也就是说
如果盒中有99个白球,摸出红球的概率只有1/100,这是小概率事件,小概率事件在一次实验中发生的可能性很小或可认为不发生,现在竟然发生了,从而怀疑所作假设的真实性(即很有可能盒子不是99个白球),认为该盒中所装的为99个红球。
假设检验的步骤
(1)建立假设,原假设
H
0
H_0
H0 与备择假设
H
1
H_1
H1
(2)选择检验统计量,确定拒绝域
W
W
W 的形式
(3)给出显著性水平
α
\alpha
α ,给出临界值
(4)将统计量的值与临界值进行比较,作出决策。统计量的值落在拒绝域,拒绝
H
0
H_0
H0 ,否则不拒绝
H
0
H_0
H0 ,或者也可以直接利用
P
P
P 值作出决策
假设检验作用
一般是对有差异的数据进行检验,判断差异是否显著
- 如果通过了检验,则不能拒绝原假设,说明没有显著差异,那么这种差异是由抽样造成的。
- 如果不能通过检验,则拒绝原假设,说明有显著差异,这种差异是由系统误差造成的。
假设检验的两类错误
假设检验中所犯的错误有两种,可以概括为:弃真纳伪
(1)第一类错误之弃真:是当原假设 H 0 H_0 H0 为真时,由于抽样的随机性,样本落入拒绝域 W W W 内,拒绝了 H 0 H_0 H0 ,犯这类错误的概率用 α \alpha α 表示,即
α = P ( 犯第一类错误 ) = P ( 当 H 0 为真时拒绝 H 0 ) = P ( 拒绝 H 0 ∣ H 0 为真 ) \alpha =P\left( \text{犯第一类错误} \right) =P\left( \text{当}H_0\text{为真时拒绝}H_0 \right) =P\left( \text{拒绝}H_0|H_0\text{为真} \right) α=P(犯第一类错误)=P(当H0为真时拒绝H0)=P(拒绝H0∣H0为真)
(2)第二类错误之纳伪:是当原假设 H 0 H_0 H0 为假时,由于抽样的随机性,样本落入 W ‾ \overline{W} W 内,不拒绝 H 0 H_0 H0 ,犯这种错误的概率用 β \beta β 表示,即
β = P ( 犯第二类错误 ) = P ( 当 H 0 为假时不拒绝 H 0 ) = P ( 不拒绝 H 0 ∣ H 0 为假 ) \beta =P\left( \text{犯第二类错误} \right) =P\left( \text{当}H_0\text{为假时不拒绝}H_0 \right) =P\left( \text{不拒绝}H_0|H_0\text{为假} \right) β=P(犯第二类错误)=P(当H0为假时不拒绝H0)=P(不拒绝H0∣H0为假)
一般表明:
- 在固定样本量 n 下,要减小 α \alpha α 必导致 β \beta β 增大;
- 在固定样本量 n 下,要减小 β \beta β 必导致 α \alpha α 增大;
- 要同时减少犯两类错误的概率,只有增加样本容量,两者是此消彼长的关系。
注:不可能同时犯第一类型错误和第二类错误
一般情况下,会在样本量 n 已固定的场合,主要控制犯第一类错误的概率,并构造出显著性水平为 α \alpha α 的检验。

显著性水平 α \alpha α
显著性水平是当原假设正确时却被拒绝的概率或风险,即假设检验中犯弃真错误的概率,通常用 α \alpha α 表示,它是人们根据经验的要求确定的,通常取 α = 0.05 \alpha=0.05 α=0.05 或 α = 0.01 \alpha=0.01 α=0.01 。
显著性水平是人们事先指定的犯第一类错误概率 α \alpha α 的最大允许值,确定了显著性水平 α \alpha α ,就等于控制了第一类错误的概率。但犯第一类错误的概率 p p p 是不确定的
统计显著
统计显著值在原假设为真的条件下,用于检验的样本统计量的值落在了拒绝域内,作出了拒绝原假设的决定
假设检验的误区:不能拒绝就接受原假设
对假设检验统计结论,不能说“接受原假设”,只能说“目前没有足够的证据拒绝原假设”。
对于接受原假设的说法是非常荒谬的,书中,吴老师举了一个非常浅显易懂的例子,1-50或1-500的自然数来自正态分布吗?
还有一点是,Shapiro-Wilk正态性检验要比K-S正态性检验效率高。
影响检验效能的因素:
- 两总体参数的真实差异
- 总体标准差 σ \sigma σ
- 显著性水平 α \alpha α
- 样本数量 n n n
P值
在一个假设问题中选择不同的显著性水平 α \alpha α 有时会导致不同的结论,而显著性水平 α \alpha α 的选择又带有主观因素,因此对判断结果不宜解释得过死板。为了使这种解释有一个宽松的余地,剔除 P P P 值。
定义:在一个假设检验问题中,拒绝原假设 H 0 H_0 H0 的最小显著性水平称为 P P P 值。也即 P P P 值是指在原假设为真的条件下,检验统计量的观察值大于或等于其计算值的概率。
利用 P P P 值和给定的显著性水平 α \alpha α ,一般有如下的判断法则:
- 若 α ≥ P \alpha \ge P α≥P 值,则拒绝原假设 H 0 H_0 H0
- 若 α < P \alpha < P α<P 值,则不拒绝原假设 H 0 H_0 H0
P P P 值是反映实际观测到的数据与原假设 H 0 H_0 H0 之间不一致程度的一个概率值。
P P P 值越小,说明实际观测到的数据与 H 0 H_0 H0 之间不一致的程度就越大,检验的结果也就越显著
有了 P P P 值,假设检验的步骤为

P值得误区:p小于0.05就有意义?
通常,所学的课本中有 P P P 值小于显著性水平时,应拒绝原假设,但对于 P P P 值要多小才算小概率,或者说 P P P 值小于多少才能算显著的问题,往往具有主观性,也就是说,拒绝与否取决于显著性水平 α \alpha α 的取值, α \alpha α 取0.05还是0.01…,需要从问题的性质出发,不能盲目判定。
显著性水平 α \alpha α 与 P P P 值得区别
(1) α \alpha α 的含义是当原假设正确时却被拒绝的概率或风险,即犯弃真错误的概率,是有人们根据检验的要求确定的,通常 α = 0.05 \alpha=0.05 α=0.05 或 α = 0..01 \alpha=0..01 α=0..01;
而 P P P 值是原假设为真时所得到的样本观察结果或更极端结果出现的概率,它是通过计算得到的, P P P 值得大小取决于三个因素:样本数据与原假设之间的差异、样本量、被假设数据的总体分布
(2) α \alpha α 只能提供检验结论的可靠性地一个大致范围,而对于一个特定的假设检验为题,却无法给出观测数据与原假设之间不一致程度的精确度量。即仅从显著性水平来比较,如果选择的 α \alpha α 值相同,所有检查结果的可靠性都一样。
而 P P P 值可以测量出样本观察数据与原假设中假设的值的偏离程度。
参数估计和假设检验的区别和联系(参考资料)
(1)主要联系:
- 都是根据样本信息推断总体参数;
- 都以抽样分布为理论依据,建立在概率论基础之上的推断,推断结果都有风险;
- 对同一问题的参数进行推断,使用同一样本,同一统计量,同一分布,二者可相互转换
(2)主要区别:
- 参数估计是以样本信息估计总体参数的可能范围,假设检验是先对总体参数提出一个假设值,然后利用样本信息判断这一假设是否成立;
- 区间估计求得的是求以样本估计值为中心的双侧置信区间,假设检验既有双侧检验,也有单侧检验;
- 区间估计立足于大概率,通常以较大的可信度
1
−
α
1-\alpha
1−α 去估计总体参数的置信区间。
假设检验立足于小概率。通常是给定很小的显著性水平a去检验总体参数的先验假设是否正确
置信区间与假设检验之间的关系
1、根据置信度
1
−
α
1-\alpha
1−α 构造置信区间,如果统计量落在置信区间中,那么不拒绝原假设,如果不在置信区间中,那么拒绝原假设。
2、根据显著水平
α
\alpha
α ,可以构建置信度为
1
−
α
1-\alpha
1−α 的置信区间。
双侧检验与单侧检验
双侧检验:拒绝域在不拒绝域两侧的检验
单侧检验:拒绝域和不拒绝域各为一侧的检验称为单侧检验。且拒绝域在不拒绝域右边的检验,称为右边单侧检验;拒绝域在不拒绝域左边的,称为左边单侧检验。
注:检验的单双侧必须依据专业知识和研究目的在设计时确定,而不能在确定P值时主观选择

正态总体均值的假设检验

两个总体均值的假设检验

正态方差的检验
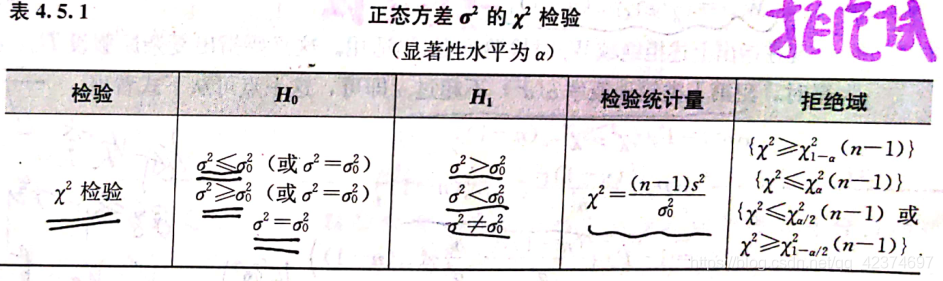
两个正态总体方差比的检验


















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









