







1. 20230615学习记录
目标
- 缓存更新的实现
- redis的缓存问题
- 布隆过滤器的使用
文章目录
1.1. 缓存更新
昨天分析到数据库和缓存一致性问题,需要一种方案当数据库数据产生增删改时来及时更新缓存
canal基于订阅binlog的同步机制,可以同步主服务器修改操作,可以利用其进行更新缓存。
1.1.1. 解读官方canal可运行代码
public class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接,此处AddressUtils.getHostIp()改为自己canal服务的ip
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();//和canal服务建立连接
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
-
AddressUtils.getHostIp(),11111;redis连接信息
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
11111), "example", "", "");
-
建立canal服务
connector.connect();//和canal服务建立连接
connector.subscribe(".*\\..*");//订阅数据库表,全部表
connector.rollback();//回滚到未进行ack的地方
-
int totalEmptyCount用于控制循环体循环次数while (emptyCount < totalEmptyCount) {}循环体内是main函数的主要部分,循环读取同步状态if (batchId == -1 || size == 0) {//没有增删改数据}else{//有增删改数据}判断是否有增删改数据,没有线程休眠会儿,可以用于控制更新缓存的时机
int totalEmptyCount = 120; //根据循环条件,可以得出,此变量用于控制循环体循环次数
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
//没有增删改数据
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
//线程休眠1s
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
//有增删改数据
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
-
printEntry(message.getEntries());修改后打印数据,都在该方法中进行。其中在
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {}内打印修改前和修改后的数据
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
//删除
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
//监听到的操作类型为修改时,打印数据
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList()); //用于打印数据 由结果可以rowData
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
-
rowData.getBeforeColumnsList()得到修改前的数据rowData.getAfterColumnsList()得到修改后的数据方法返回的是
CanalEntry.Column类型的集合一个
CanalEntry.Column包含了被修改的行数据的字段名(getName()),该字段数据值(getValue()),该字段是否修改(getUpdated())
private void printColumn(List<CanalEntry.Column> columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
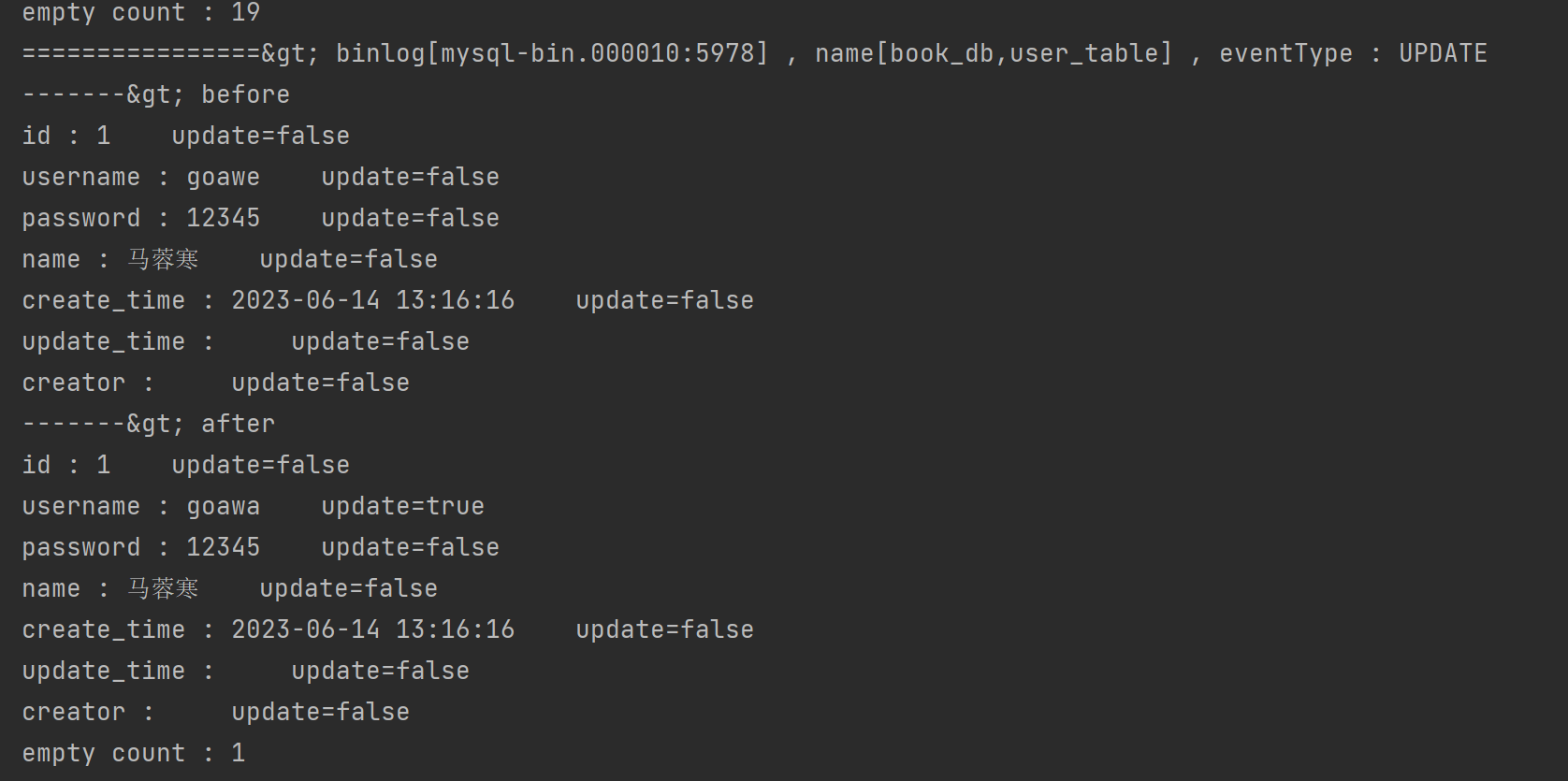
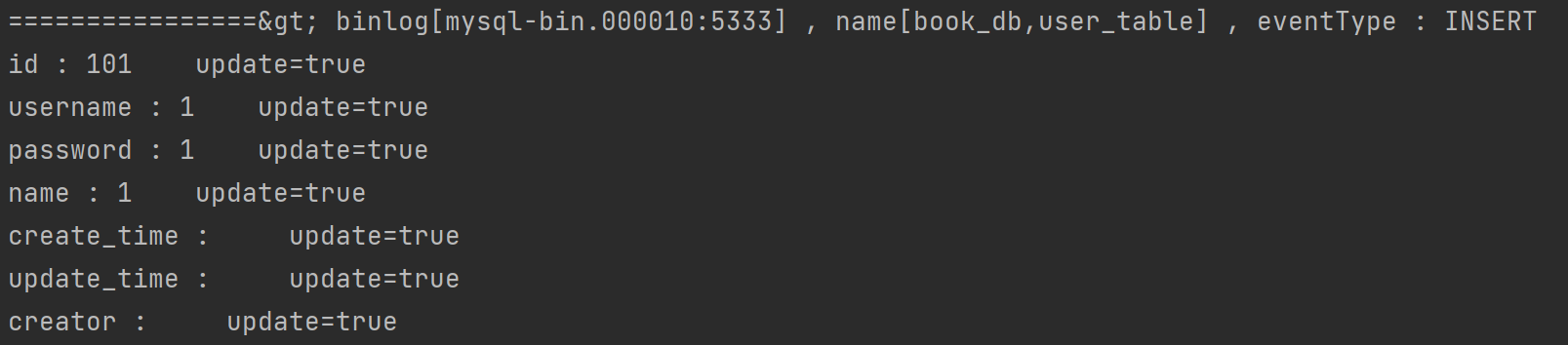
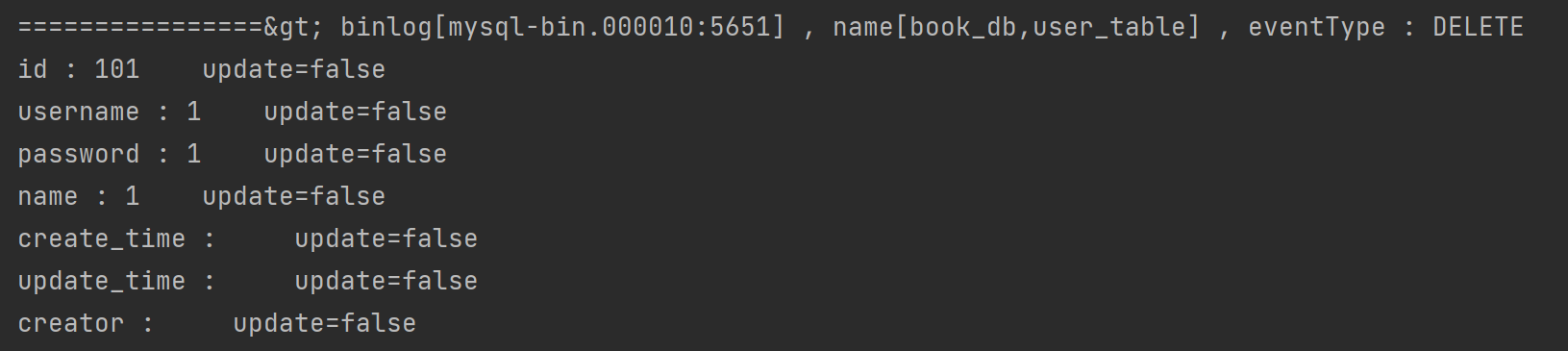
- 修改,增加,删除操作的获取结果
修改
添加
删除
1.1.2. 应用项目的修改
-
新建类,作更新缓存操作
将可运行代码复制粘贴,main方法更改为自定义的方法
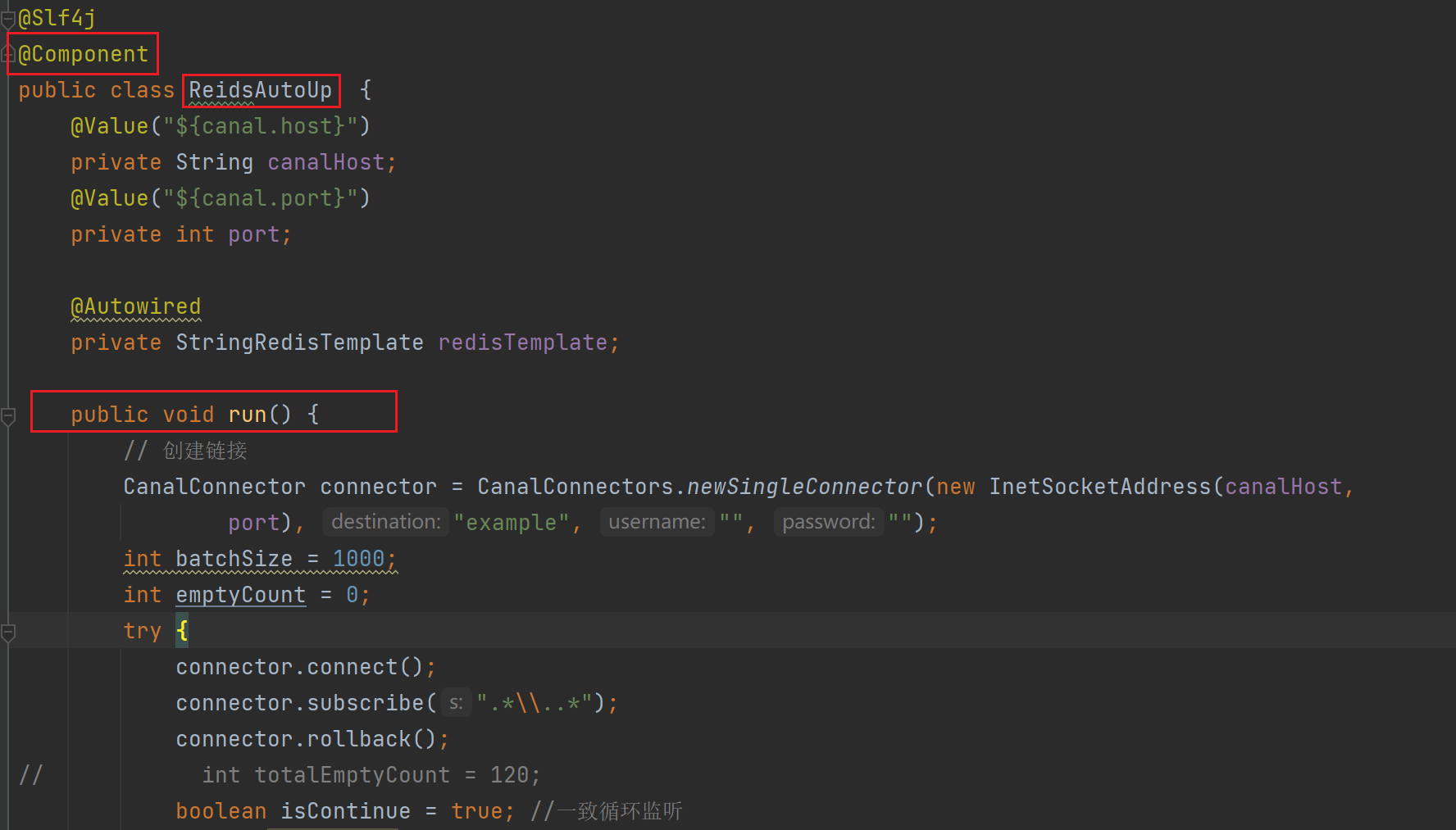
-
需要随着项目一起启动,且一直获取同步状态
启动类实现
CommandLineRunner,重写public void run(String... args)方法,在方法中调用缓存更新方法
@SpringBootApplication
@MapperScan("com.wnhz.bm.dao")
public class App implements CommandLineRunner {
@Autowired
private ReidsAutoUp reidsAutoUp;
public static void main(String[] args) {
SpringApplication.run(App.class,args);
}
@Override
public void run(String... args) throws Exception {
reidsAutoUp.run();
}
}
循环体作死循环
boolean isContinue = true; //一致循环监听
while (isContinue) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(500); //500ms
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
- 获取到修改前,修改后数据,用以更新缓存
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
//监听到的操作类型为修改时,打印数据
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList()); //用于打印数据 由结果可以rowData
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
updateRedis(rowData.getBeforeColumnsList(),rowData.getAfterColumnsList());
}
}
/**
* 更新缓存操作
* @param beforColumns
* @param afterColumns
*/
private void updateRedis(List<CanalEntry.Column> beforColumns,List<CanalEntry.Column> afterColumns){
String beforUsername = "";
for (CanalEntry.Column column : beforColumns) {
if("username".equals(column.getName())){
beforUsername = column.getValue();
break;
}
}
for (CanalEntry.Column column : afterColumns) {
if("username".equals(column.getName()) && column.getUpdated()){
redisTemplate.opsForSet().remove("username",beforUsername);
redisTemplate.opsForSet().add("username",column.getValue());
}
}
}
1.2. redis缓存雪崩
大量请求访问redis时,刚好缓存中数据大批量到过期时间,大量的请求到去请求数据库,导致数据库压力陡增,可能导致宕机。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
(热点数据:请求频繁的数据)
1.3. redis缓存击穿
大量请求访问redis的同一数据,刚好该数据到了过期时间,大量的请求到去请求数据库,导致数据库压力陡增,可能导致宕机。
解决方案:
- 设置热点数据永远不过期。(不是真正的永不过期)
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
1.4. redis缓存穿透
当缓存和数据库没有数据时,当查询数据缓存不存在时,会继续查询数据量,当大量请求访问不存在的数据时,每次访问都要查询数据库,访问不存在数据请求的并发量一大数据库容易宕机;该问题容易被有心之人进行攻击。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,设置较短的过期时间
- 使用布隆过滤器判断
1.4.1. 布隆过滤器
简介:
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
布隆过滤器的原理:当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:如果这些点有任何一个 0,则被检元素一定不在;如果都是 1,则被检元素很可能在。
用自己理解的话解释一下:
-
首先引出
BitMap数据结构设想这样一个情况:我们想存储数据,并且有需求要判断某个值是否存在,我们会使用list、map存储;假设大量的数据要存到集合中会怎样,假设一个请求就要存储一亿个int类型的整数,就需要380多MB(4byte × 10 ^8),高并发情况下,需要很大的内存存储集合数据,不实际。
BitMap结构是指,以位数来代表一个数字大小,比如1B,第7位被置了1,代表存了一个数字1,假设要存一个数字10,则在第十位置。那么1B就能用来存储0-7这八个数,一个int 4B 32位,可以存储32个值,存储大小直接减少到1/32,大大减少

BitMap结构能存储的数量庞大,但是用位数代表值的做法有个弊端,要开辟的存储空间与最大数的数值成正比,假如要存储1万个的数据,但是数据的最大值是100万,意味着要101万bit空间来存储这1万个数据。怎么办?用算法,将数据面值减小 -
布隆过滤器
存储的结构利用的BitMap,对一个数据进行了K个hash函数计算,得到K个值,这k个值表示一个数,在这k个值的位数上置1、这样也可以保证装下面值大的数据,而且想判断一个数据是否存在,只需要进行一下hash计算,看对应结果的位数上是否置1,只要有一个0就表示这个数据存在;
怎么理解布隆过滤器对于
判断为存在的结果有误识别概率(通过布隆过滤器计算判断不存在的结果肯定正确,但是存在的结果不一定正确)上述所说,hash得到的结果肯定能够对应上数据,所以只要对应结果的位数上有一个0,该hash结果对应的数据不存在是100%的;但是数据变多的情况下,置1的位数会变多,可能不同的位数组成了一个数据的hash结果,但是这个数据其实并不存在
假设x的hash结果为 1、3、7,那么在第一位,第三位、第七位置一;查找x是否存在是,hash得到1、3、7,检查第一位,第三位、第七位是否都置1,其中1个为0,就可以判定x不存在。
假设x的hash结果为1、3、7,y的hash结果为2、4、8,x和y都存在了,此时要找一个c,它的hash结果为1、2、7,它实际没有存入,但是x和y的hash结果包含了c的hash结果,导致查找的时候误判c存在了。
参考:https://developer.huawei.com/consumer/cn/forum/topic/0201117114074403582
1.4.2. 布隆过滤器应用
还是hutool提供了工具类
1.4.2.1. BitMapBloomFilter的使用
// 初始化
BitMapBloomFilter filter = new BitMapBloomFilter(10);
filter.add("123");
filter.add("abc");
filter.add("ddd");
// 查找 返回类型boolean
filter.contains("abc")
1.4.2.2. 项目中应用
查询不存在的数据时,先用布隆过滤器过滤查询不存在用户的请求,防止缓存穿透;此处布隆过滤器充当类似白名单功能,布隆过滤器中有的才放行
- 缓存预热时,同时也预热布隆过滤器;
- 访问先查布隆过滤器,没有,直接返回;有,继续查询缓存;
- 缓存有,取出,返回数据;
- 缓存没有,继续查询数据库,查询出来后回写更新缓存,返回数据
1.4.2.3. 自定义布隆过滤器工具类
public class WhiteListUtil {
private static BitMapBloomFilter bf = new BitMapBloomFilter(10);
public static void add(String str){
bf.add(str);
}
public static boolean isExist(String str){
return bf.contains(str);
}
}
1.4.2.4. 布隆过滤器数据装载
在预热缓存的时候同时装载
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
log.debug("缓存预热开始");
//缓存预热
//先清空缓存
redisTemplate.delete("username");
//查询数据库,将用户名全部存入key="username"的set类型value中
List<User> allUsers = userService.findAll();
allUsers.forEach(u -> {
redisTemplate.opsForSet().add("username",u.getUsername());
//布隆过滤器装载
WhiteListUtil.add(u.getUsername());
});
log.debug("缓存预热结束");
}
1.4.2.5. controller层,先查布隆过滤器
@GetMapping("/findByUsername")
public RespData findByUsername(String username){
if(WhiteListUtil.isExist(username)){
//布隆过滤器中存在,继续查询缓存
log.debug("布隆过滤器中存在,继续查询缓存");
String result = userService.findByUsername(username);
return RespData.respData(ResultCode.BOOK_QUERY_SUCCESS,result);
}else {
//不存在直接返回
log.debug("布隆过滤器中不存在");
return RespData.respData(ResultCode.BOOK_QUERY_ERROR.getCode(),"用户不存在",null);
}
}
1.4.2.6. service层查缓存和数据库
@Override
public String findByUsername(String username) {
log.debug("通过了布隆过滤器,查询缓存");
//先查缓存有没有
Boolean isExist = redisTemplate.opsForSet().isMember("username", username);
if(isExist){
//缓存中有,取出来返回
log.debug("缓存中有");
Set<String> usernames = redisTemplate.opsForSet().members("username");
return usernames.stream().filter(s -> s.equals(username)).collect(Collectors.toList()).get(0);
}else {
//缓存中不存在
log.debug("缓存没有,查询数据库");
LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(User::getUsername,username);
User user = userDao.selectOne(queryWrapper);
//回写缓存
log.debug("回写缓存");
redisTemplate.opsForSet().add("username",user.getUsername());
return user.getUsername();
}
}
















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









