







1. 20230620学习记录
目标
- 了解类加载过程
- 对象创建的几种方式
- 反射
- RebbitMQ的安装
文章目录
1.1. 编译
编译:编译器将源文件(src .java) 编译为 字节码文件(.class)
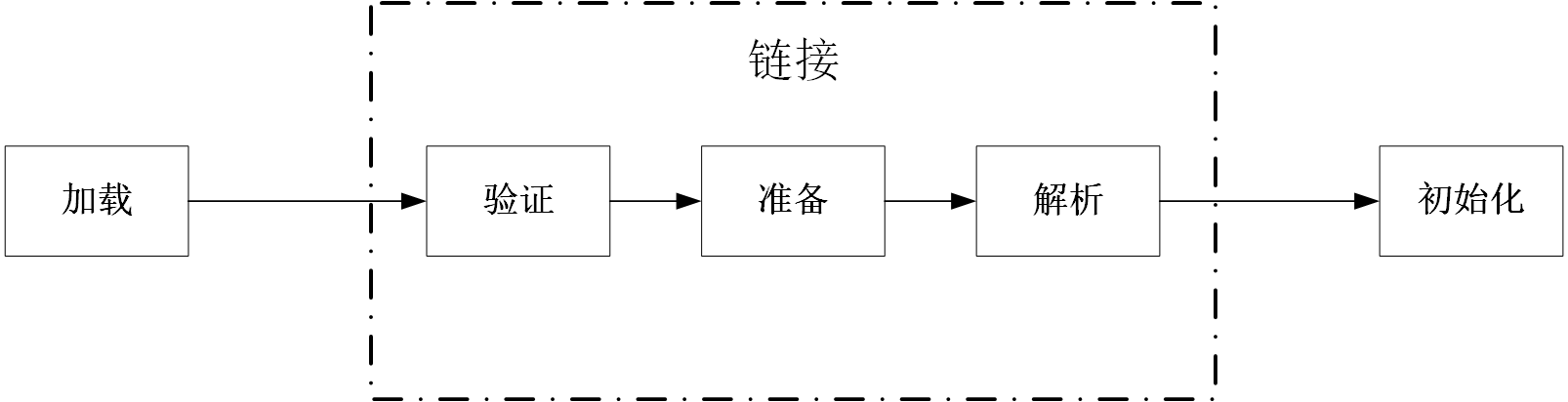
1.2. 类加载过程
-
加载:由【类加载器(ClassLoader)】把一个二进制字节流读入到JVM(java虚拟机)内部,并存储在【方法区】,接着生成一个与目标类型对应的java.lang.Class对象实例(该对象实例就是我们反射用到的Class对象),因为该对象实例记录了基本信息,可以拿到属性和方法名称,就像一面镜子一样,所以我们称其为反射。加载并不需要等到某个类被“首次主动使用”时再加载,JVM规范允许类加载器在预料某个类将要被使用时就预先加载它。
-
链接:链接包含验证、准备、解析阶段。
-
验证:这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
文件格式验证: 验证字节流是否符合Class文件格式的规范;例如: 是否以0xCAFEBABE开头、主次版本号是否在当前虚拟机的处理范围之内、常量池中的常量是否有不被支持的类型。元数据验证: 对字节码描述的信息进行语义分析,以保证其描述的信息符合Java语言规范的要求;例如: 这个类是否有父类,除了java.lang.Object之外。(注意: 对比javac编译阶段的语义分析,编译阶段也做了语义分析,此处再进行验证,应该是为了确保加载的class可以运行,因为不能确定class是否被修改过。)字节码验证: 通过数据流和控制流分析,确定程序语义是合法的、符合逻辑的。符号引用验证: 确保解析动作能正确执行。 -
准备:准备阶段会为
所有的静态变量分配空间(这些内存都将在方法区中分配),并初始化为默认值,被final修饰的static变量会直接赋值。 -
解析: 在解析阶段,虚拟机会把所有的类名,方法名,字段名这些符号引用替换为具体的内存地址或偏移量,也就是直接引用。
-
-
初始化:为静态变量赋值,执行static代码块;如果初始化一个类的时候,其父类尚未初始化,则优先初始化其父类。如果同时包含多个静态变量和静态代码块,则按照自上而下的顺序依次执行。
1.3. 类初始化时机
对于初始化阶段虚拟机规范是严格规定了如下几种情况,如果类未初始化会对类进行初始化(如果类还未被加载过,那么加载、验证、准备都会随着发生)
- 创建类的实例,new
- 访问类的静态变量(除常量【被final修辞的静态变量】)。
- 访问类的静态方法
- 反射如(Class.forName(“my.xyz.Test”))
- 当初始化一个类时,发现其父类还未初始化,则先进行父类的初始化
- 虚拟机启动时,定义了main()方法的那个类先初始化
1.4. 双亲委派机制
1.4.1. 什么是双亲委派机制
当类加载器加载时,会先委托给父加载器加载,父加载器收到加载请求时,也会先委托给它的父加载器;当父加载器无法加载某个类时,才会交给子加载器加载
- 什么时候父加载器会无法加载某一个类
Java中提供的这四种类型的加载器:
-
Bootstrap ClassLoader ,主要负责加载Java核心类库,%JAVA_HOME%\jre\lib下的rt.jar、resources.jar、charsets.jar和class等。
-
Extention ClassLoader,主要负责加载目录%JAVA_HOME%\jre\lib\ext目录下的jar包和class文件。
-
Application ClassLoader ,主要负责加载当前应用的classpath下的所有类
-
User ClassLoader , 用户自定义的类加载器,可加载指定路径的class文件
所以我们自己定义的类,不会被Bootstrap 和 Extention 加载
1.4.2. 为什么需要双亲委派机制
加载器的层级关系,使得类也具备层级关系;
因此可以避免类被重复加载,父加载器加载过的类,子加载器不会再加载
还能够保证安全,java.lang.string这个类,在本地%JAVA_HOME%\jre\lib下的rt.jar下,只会由Bootstrap ClassLoader加载,这样他人无法写一个相同名的类来随意替换。
参考:https://www.cnblogs.com/hollischuang/p/14260801.html
1.5. 创建对象的几种方式
- new关键字
- 反射:Class.newInstance 只能够调用无参的构造函数,即默认的构造函数;
- 反射:Constructor.newInstance 可以根据传入的参数,调用任意构造构造函数
- Clone方法(克隆):继承自Object的clone方法,使用的clone方法还需要该类实现Cloneable接口,注意克隆的浅拷贝问题
- 反序列化
1.5.1. clone
浅拷贝
当A对象中的属性为另一对象B时,拷贝A得到的对象只拷贝属性B的引用
public class People implements Cloneable{
private String name;
private Car car; //属性为Car对象
}
public static void main(String[] args) throws CloneNotSupportedException {
Car car = new Car("奔驰");
People p = new People("sb",car);
People b = p.clone();
car.setName("宝马");
System.out.println("原对象:"+p);
System.out.println("克隆对象:"+b);
//此时发现克隆对象的Car的name也变成了宝马
//这就是浅拷贝,拷贝的对象为新对象,但是其中的对象属性只拷贝了应用
}
要做到深拷贝,需要在clone方法中重写一下,收到新建一个Car对象给克隆对象
@Override
public People clone() throws CloneNotSupportedException {
Car car = new Car(this.getCar().getName());
return new People(this.getName(),car);
}
1.6. jvm栈和堆大小怎么调整
JVM(Java Virtual Machine)
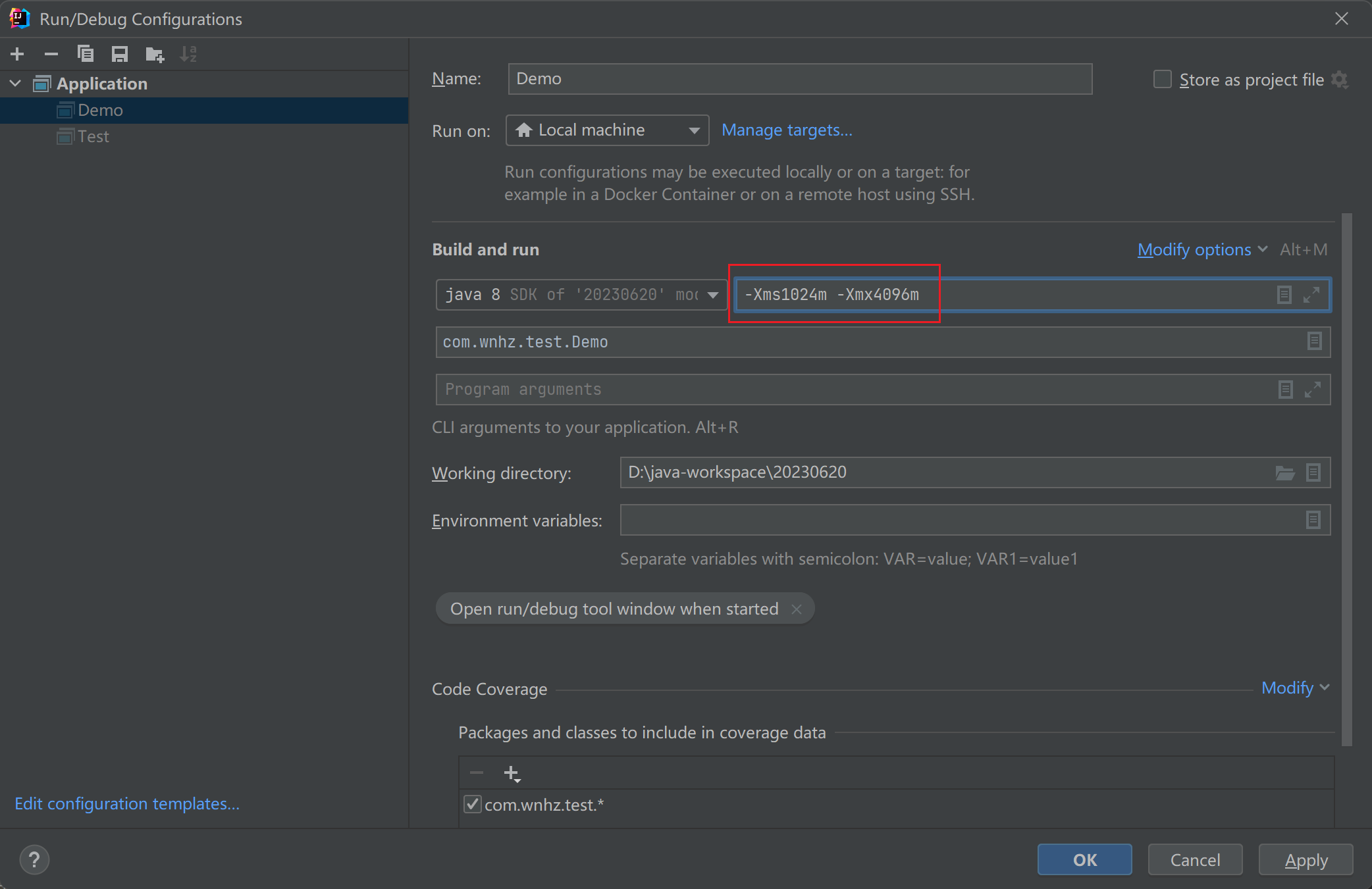
-Xmx 参数设置 JVM 最大可以使用的堆内存大小。如果没有设置该参数,默认值是物理内存的 1/4 或者 1GB(取两者中的较小值)。
-Xms 参数设置初始堆内存,默认是物理内存的1/64.
-Xss 参数设置单个线程栈的大小,一般默认为1M。
- 程序获取内存大小
//最大内存
long max = Runtime.getRuntime().maxMemory();
//初始化内存
long total = Runtime.getRuntime().totalMemory();
System.out.println("max:"+max/1024/1024+"MB");
System.out.println("total:"+total/1024/1024+"MB");
-
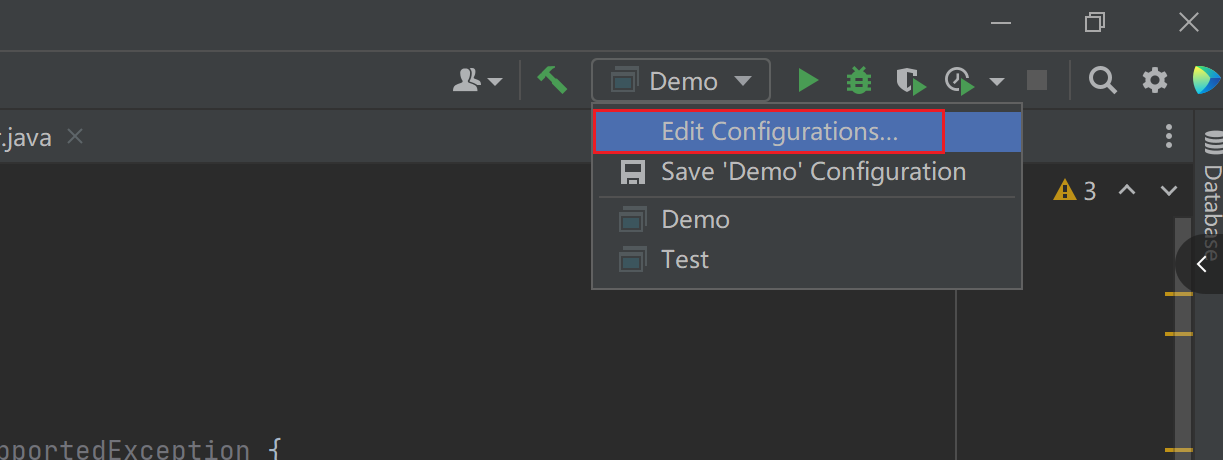
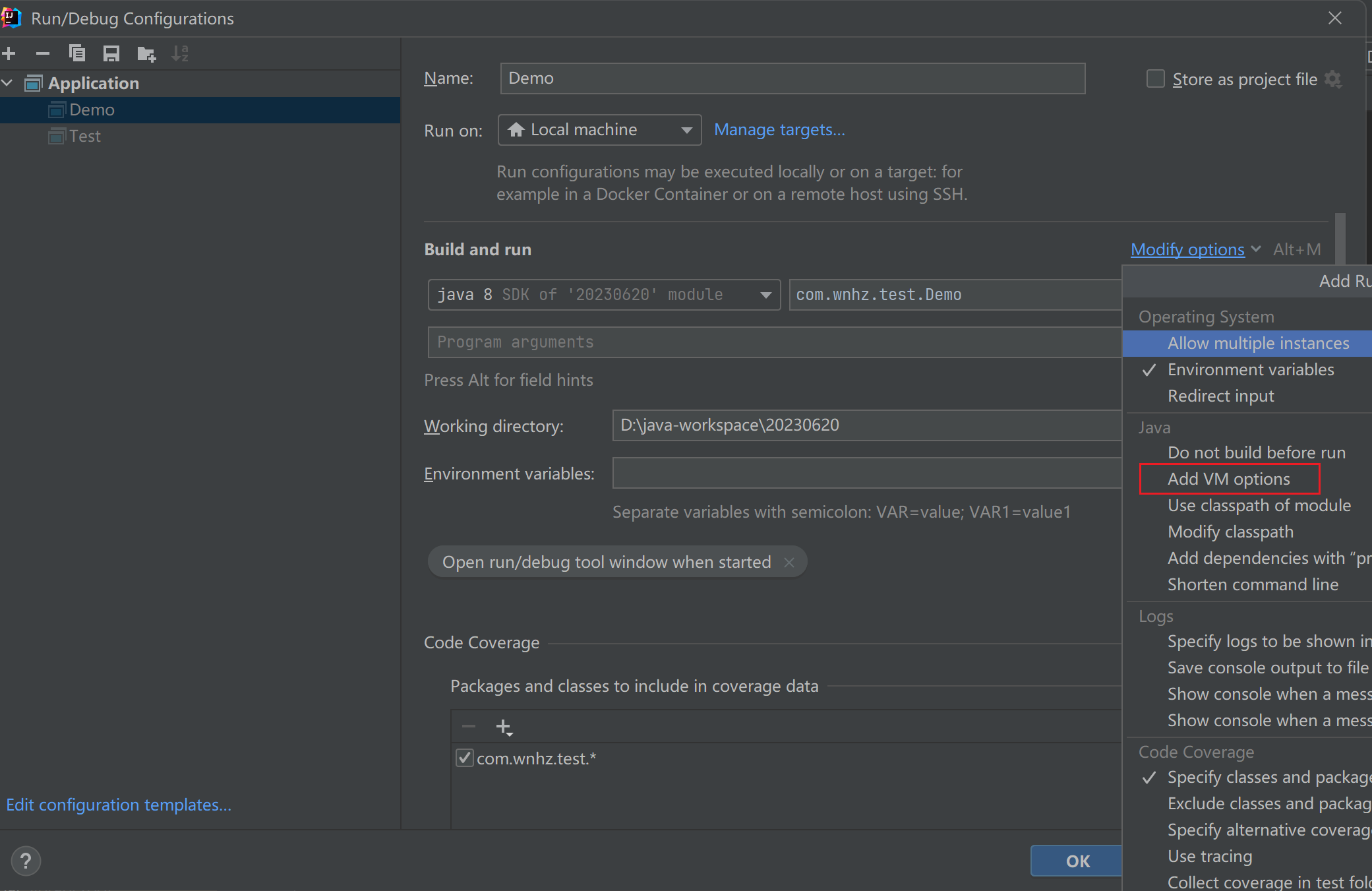
如何设置内存
在idea中
-
java对象的存储结构:
对象头(Header)、实例数据(Instance Data)、对齐填充(Padding)
使用jol-core工具可以查看JVM中内存布局
对象头至少占用16字节(8字节整数倍)
实例数据假设就一个int类型的属性,占用 指向class定义的引用8字节,int 4字节,12字节
对齐填充:填充实例为8字节的整数倍 填充4字节
对象总共32字节
1.7. RebbitMQ
1.7.1. 简介
RabbitMQ是非常热门的一款消息中间件。它接收消息并且转发
1.7.2. 作用
消峰:放访问量剧增的时候,使用消息中间件队列的形式减少突然的访问压力
解耦:子系统与子系统之间的交互时直接调用的话,一个系统的故障,会导致另一个系统无法调用也产生异常;而使用消息队列中间件时,调用数据的系统出现故障,不影响产生数据的系统继续产生数据并且放入消息队列,调用数据的系统等故障排除后继续拿取队列中的数据处理即可。
1.7.3. docker安装RebbitMQ
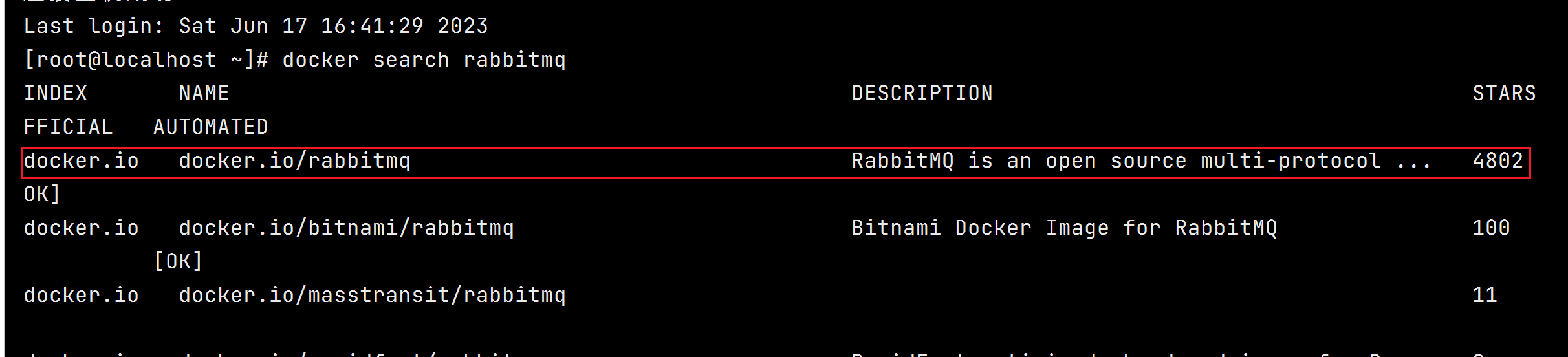
1.7.3.1. 查询镜像
docker search rabbitmq
1.7.3.2. 拉取镜像
docker pull rabbitmq
1.7.3.3. 创建文件夹
usr/local/software/rabbitmq/plugins
1.7.3.4. 创建容器
15672端口是web客户端界面访问端口
5672端口是java后台需要连接的端口
docker run -it --name=rabbitmq -e RABBITMQ_DEFAULT_USER=admin -e RABBITMQ_DEFAULT_PASS=99120805 -p 15672:15672 -p 5672:5672 rabbitmq
1.7.3.5. 启动管理插件
进入rabbitmq容器
docker exec -it rabbitmq bash
rabbitmq-plugins enable rabbitmq_management
1.7.3.6. 管理页面配置
进入到容器内的/etc/rabbitmq/conf.d文件夹
输入回车
echo management_agent.disable_metrics_collector=false > management_agent.disable_metrics_collector.conf
















 99
99











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









