







1. 20230613学习记录
目标
- 了解雪花ID
- Redis持久化策略
- Redis的事务(lua脚本简单编写)
- Redis主从搭建
- JMeter的使用
1.1. 雪花ID
202306012中的验证码应用中,使用UUID作为每一个验证码的唯一标识,用于存取和识别。
当访问量大,UUID生成量变大时,会有重复的情况。
雪花ID(snowflake)是Twitter开源的分布式ID生成算法,结果是64bit的Long类型的ID,有着全局唯一和有序递增的特点。
1.1.1. 组成结构
- 最高位是符号位,因为生成的 ID 总是正数,始终为0。
- 41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
- 10位的机器标识,10位的长度最多支持部署1024个节点。
- 12位的计数序列号,序列号即一系列的自增ID,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号。
1.1.2. 优缺点
-
优点
- 能满足高并发分布式系统环境ID不重复
- 生成效率高,64位,一个long型就能表示
- 总体有序递增,基于时间戳且位于高位,时间戳不断递增,整个ID都是趋势递增的
-
缺点
- 强依赖机器时钟,如果机器上时钟回拨,会导致生成重复ID。
1.1.3. 工具类
hutool
1.1.3.1. 引入依赖
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.16</version>
</dependency>
1.1.3.2. 使用
//参数1为终端ID
//参数2为数据中心ID
Snowflake snowflake = IdUtil.getSnowflake(1, 1);
long id = snowflake.nextId();
//简单使用
long id = IdUtil.getSnowflakeNextId();
String id = IdUtil.getSnowflakeNextIdStr();
1.1.4. 应用
1.1.4.1. 使用hutool简单封装自己的工具类
package com.wnhz.springboot.util;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;
import javax.annotation.PostConstruct;
@Slf4j
public class SnowFlakeUtil {
private static long workerId = 0;
private static long dataCenterId = 1;
private static Snowflake snowflake = IdUtil.getSnowflake(workerId, dataCenterId);
@PostConstruct
public void init() {
try {
workerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());
log.info("当前机器的workId:[]", workerId);
} catch (Exception e) {
log.error("当前机器的workId获取失败", e);
workerId = NetUtil.getLocalhostStr().hashCode();
}
}
public static synchronized long snowflakeId() {
return snowflake.nextId();
}
public static synchronized String snowflakeIdStr() {
return String.valueOf(snowflake.nextId());
}
}
1.1.4.2. 使用工具类生成验证码key

1.2. Redis的持久化策略
Redis 的读写都是在内存中,所以它的性能较高,但在内存中的数据会随着服务器的重启而丢失,为了保证数据不丢失,Redis支持数据的持久化。
1.2.1. RDB(Redis DataBase)
在指定时间间隔内将内存中的数据集快照写入磁盘的方式;
fork一个新的子线程,fork的过程主线程是阻塞的,fork操作完成后主线程即可继续执行;子线程先将内存中的数据写入到临时的rdb文件中,待快照数据写入完成后再替换旧的rdb文件;重启会通过加载rdb文件恢复数据
优点:
- RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景;
- Redis加载RDB文件恢复数据快
缺点:
- RDB是每隔一段时间进行持久化,如果期间redis服务器宕机,还没有进行持久化,就丢失了一段时间内的数据
- fork子线程时,而且主线程的内存越大fork时间越长,阻塞时间越长。(fork子进程时,操作系统需要拷贝父进程的内存页表给子进程,如果整个Redis实例内存占用很大,那么它的内存页表也会很大,在拷贝时就会比较耗时,同时这个过程会消耗大量的CPU资源)
- 如果频繁 fork ,这就会频繁阻塞主线程。
应用场景:对数据恢复时间要求高、需要数据备份存储、数据完整性要求不那么高的场景
1.2.2. AOF(Append Only File)
往磁盘的AOF文件追加每个写操作的命令记录
所有的写入的命令都会被追加到aof_buf缓冲区,接着AOF缓冲区根据对应的同步策略向磁盘做同步的操作,有三个方式:
- appendfsync always:每次写入到缓冲区就同步到AOF文件中
- appendfsync everysec:每秒同步一次缓冲区到aof文件
- appendfsync no:同步aof文件操作时机由系统来决定
优点:
- 实时性好,数据完整性更高,不易丢失;
缺点:
- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。
- 与AOF相比,在恢复大的数据时候,RDB方式更快一些
应用场景:对数据完整性要求高的场景
1.3. Redis的事务
1.3.1. Lua脚本
Lua 是一种轻量小巧的脚本语言,用标准C语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
Redis的执行命令是原子性的,但是假如我们一个操作同时执行好几个命令的同时又想这个操作保持原子性,就需要使用Lua脚本。
Redis 嵌入了 Lua 环境,支持 Lua 脚本
Redis会将整个Lua脚本作为一个整体执行,不会被其他请求打断,可以保持原子性
1.3.2. 模拟数据
模拟书本库存数据,使用hash类型,设置 书本名称 Java 书本库存 100
hset book title java amount 100
1.3.3. 编写Lua脚本
使用Lua脚本编写
书本库存减少操作
1.3.3.1. idea安装插件,便于编写
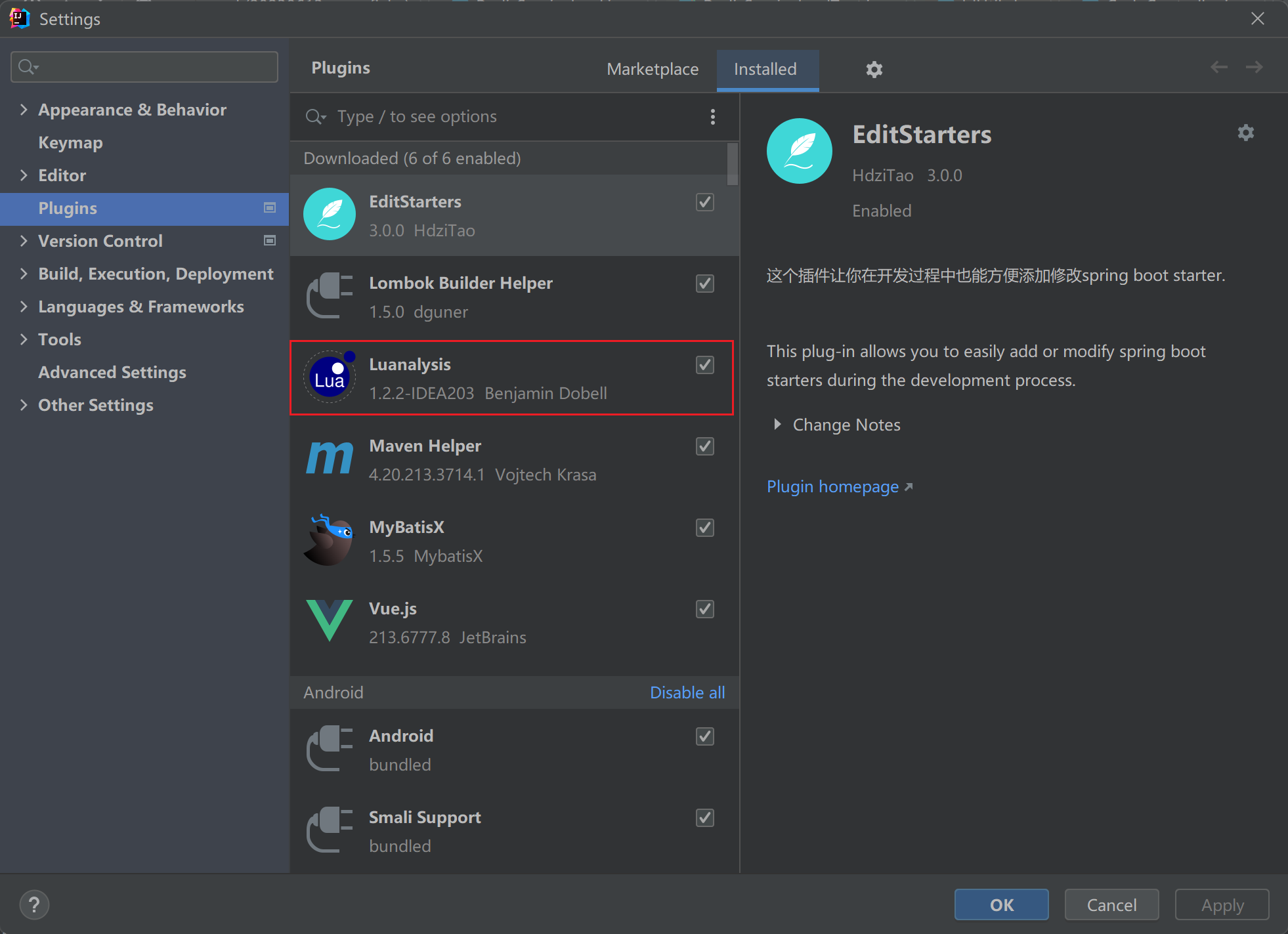
1.3.3.2. 创建lua文件

1.3.3.3. 编写lua脚本
-- 定义变量,执行lua 会传入参数
-- 当前操作redis的hash数据类型,执行该lua文件时 把key和filed作为KEYS参数传入
local book = KEYS[1] -- 获取第一个key
local amount = KEYS[2] -- 获取第一个filed
local wanted = tonumber(ARGV[1]) -- 库存减少数量参数 tonumber:转number类型
-- 判断book中amount字段是否存在
-- redis.call方法调用redis的命令
local isExists = tonumber(redis.call('hexists',book,amount)) -- 获取hexists命令的结果
-- 判断结果 存在为1,key和filed存在才进行接下去的动作
if isExists == 1 then
-- 获取amount对应的值
local currVal = tonumber(redis.call('hget',book,amount))
-- 判断是否>0 库存是否大于要减少的数量
if currVal>0 and currVal-wanted>0 then
-- 符合,执行减少命令
redis.call('hincrby',book,amount,0-wanted)
-- 执行成功
return 1
else
-- 不符合,库存不够
return -2
end
else
-- key和filed不存在
return -1
end
1.3.4. 执行java代码调用
@RestController
@RequestMapping("/api/book")
public class BookController {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@PutMapping("/unstock")
public RestData unstock(){
//Spring提供了RedisScript接口,方便调用lua脚本,DefaultRedisScript为实现类
//泛型为lua脚本返回数据类型
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
//设置lua脚本返回数据类型
redisScript.setResultType(Long.class);
//加载lua脚本资源
redisScript.setLocation(new ClassPathResource("/lua/book-unstock.lua"));
// 定义lua脚本所需参数KEYS
List<String> keys = new ArrayList<>();
keys.add("book");
keys.add("amount");
//使用stringRedisTemplate的execute方法执行lua脚本
// "10" lua脚本所需参数ARGV
Long result = stringRedisTemplate.execute(redisScript, keys, "10");
return new RestData(result.intValue()==1?"操作成功":(result.intValue()==-1?"书不存在":"库存不够"));
}
}
1.4. Redis主从搭建
1.4.1. 下载redis配置文件
https://redis.io/docs/management/config

1.4.2. 创建redis的挂载目录
在/usr/local/software下创建redis目录
在redis目录下创建对应3个redis服务器的目录,以端口号命名: 6379,6380,6381
在每个文件夹下都创建data, conf, 和logs文件夹。
- conf:存储redis配置文件
- logs: 存储redis日志文件
mkdir -p 6379/conf 6379/data 6379/logs
mkdir -p 6380/conf 6380/data 6380/logs
mkdir -p 6381/conf 6381/data 6381/logs
#创建对应日志文件 并修改为777权限
touch 6379/logs/redis_6379.log
touch 6380/logs/redis_6380.log
touch 6381/logs/redis_6381.log
chmod 777 6379/logs/redis_6379.log
chmod 777 6380/logs/redis_6380.log
chmod 777 6381/logs/redis_6381.log
1.4.3. 上传配置文件并修改
上传官网下载的配置文件到每个conf目录下
-
6379作为主服务器,修改其配置
# 修改75行为 bind 0.0.0.0 #修改94行为 protected-mode no #修改304行 日志存放位置 logfile "/var/log/redis/redis_6379.log" -
6380、6381作为从服务器,修改配置
#6380依次修改 bind 0.0.0.0 protected-mode no logfile "/var/log/redis/redis_6380.log" #1254行,开启AOF持久化 appendonly yes #6381依次修改 bind 0.0.0.0 protected-mode no logfile "/var/log/redis/redis_6381.log" #1254行 appendonly yes
1.4.4. 创建主从容器
删除以前创建的容器
1.4.4.1. 创建主服务器容器
docker run -itd --name redis_6379 --privileged=true -v /usr/local/software/redis/6379/conf/redis.conf:/usr/local/etc/redis/redis.conf -v /usr/local/software/redis/6379/data/:/data -v /usr/local/software/redis/6379/logs/redis_6379.log:/var/log/redis/redis_6379.log -p 6379:6379 redis /usr/local/etc/redis/redis.conf
创建成功后,检查容器是否允许,是否能正常进入redis
docker ps
docker exec -it redis_6379 bash
redis-cli
ping
#如果容器没有启动可以检查日志,看看问题
docker logs redis_6379
1.4.4.2. 创建从服务器容器并配置
-
查主服务的容器ip地址
docker inspect redis_6379| grep IPA -
修改从服务器挂载的配置文件
末尾添加主从配置
vim 6380/conf/redis.conf vim 6381/conf/redis.conf slave-read-only no #主服务器容器的ip 端口 replicaof 172.17.0.2 6379 -
创建6380、6381的容器
docker run -itd --name redis_6380 --privileged=true -v /usr/local/software/redis/6380/conf/redis.conf:/usr/local/etc/redis/redis.conf -v /usr/local/software/redis/6380/data/:/data -v /usr/local/software/redis/6380/logs/redis_6380.log:/var/log/redis/redis_6380.log -p 6380:6379 redis /usr/local/etc/redis/redis.conf
docker run -itd --name redis_6381 --privileged=true -v /usr/local/software/redis/6381/conf/redis.conf:/usr/local/etc/redis/redis.conf -v /usr/local/software/redis/6381/data/:/data -v /usr/local/software/redis/6381/logs/redis_6381.log:/var/log/redis/redis_6381.log -p 6381:6379 redis /usr/local/etc/redis/redis.conf
-
查看主从设置是否生效
进入每个redis服务中查看
docker exec -it 容器名 bash redis-cli info replication主服务正常
从服务器正常

配置成功
1.5. JMeter
1.5.1. 简介
Apache JMeter是Apache组织开发的基于Java的压力测试工具。用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域。 它可以用于测试静态和动态资源。
JMeter 可以用于对服务器、网络或对象模拟巨大的负载,来自不同压力类别下测试它们的强度和分析整体性能
1.5.2. 使用
1.5.2.1. 进入bin目录,使用jmeter.bat启动程序

1.5.2.2. 创建线程组

设置线程数和循环次数

1.5.2.3. 配置元件
在刚刚创建的线程组上右键 【添加】–>【配置元件】–>【HTTP请求默认值】

不必须 配置需要进行测试的程序协议、地址和端口,这样可以为一组相同地址端口的接口统一配置

1.5.2.4. 构造HTTP请求
在“线程组”右键 【添加-】->【取样器】–>【HTTP 请求】

设置我们需要测试的API的请求路径和数据 不添加配置元件,可以在此处设置

1.5.2.5. 添加HTTP请求头
右键 【添加】–>【配置元件】–>【HTTP信息头管理器】

可以定义请求头信息,比如需要传输的时json串

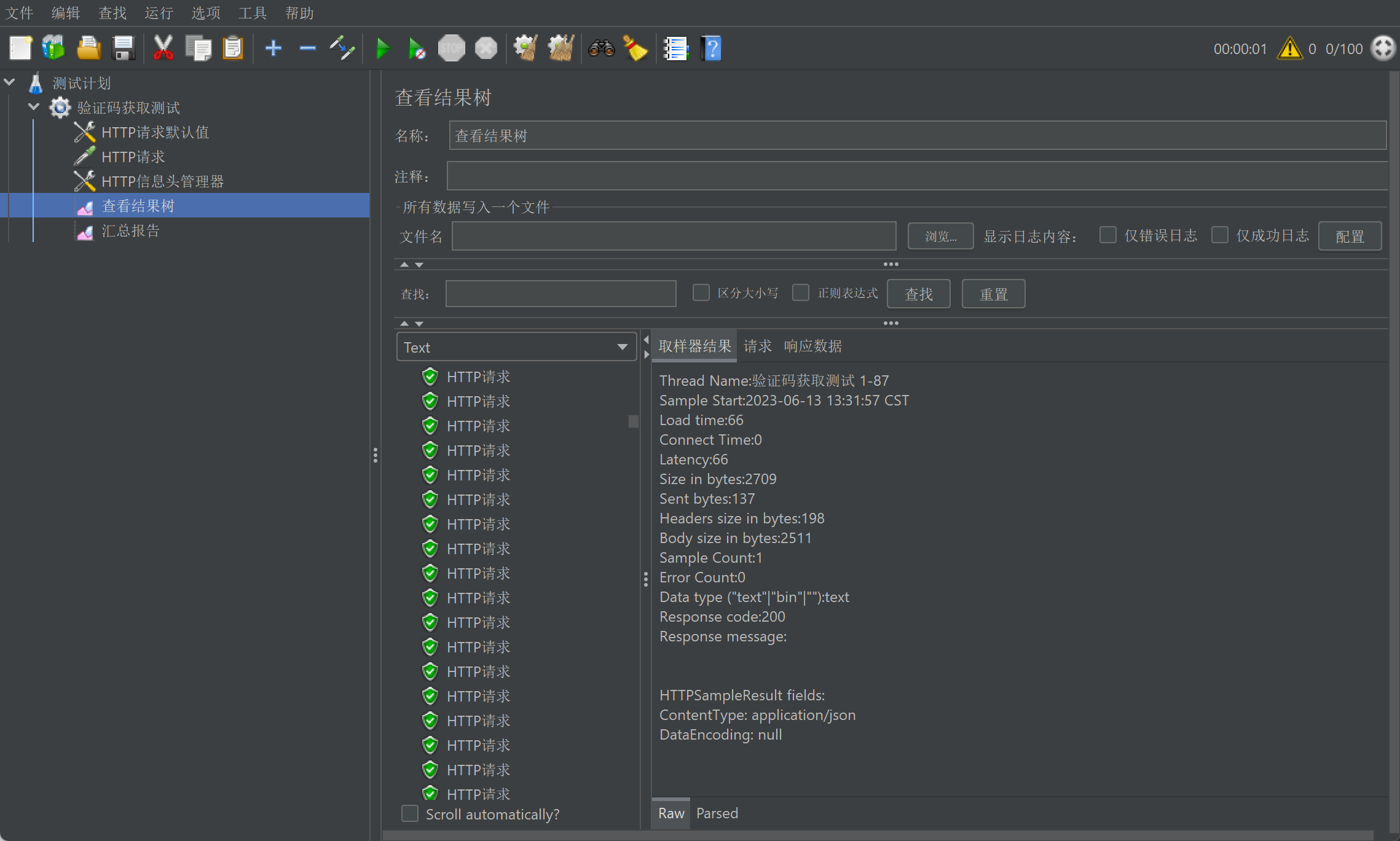
1.5.2.6. 添加查看结果树
右键 【添加】–>【监听器】–>【查看结果树】。

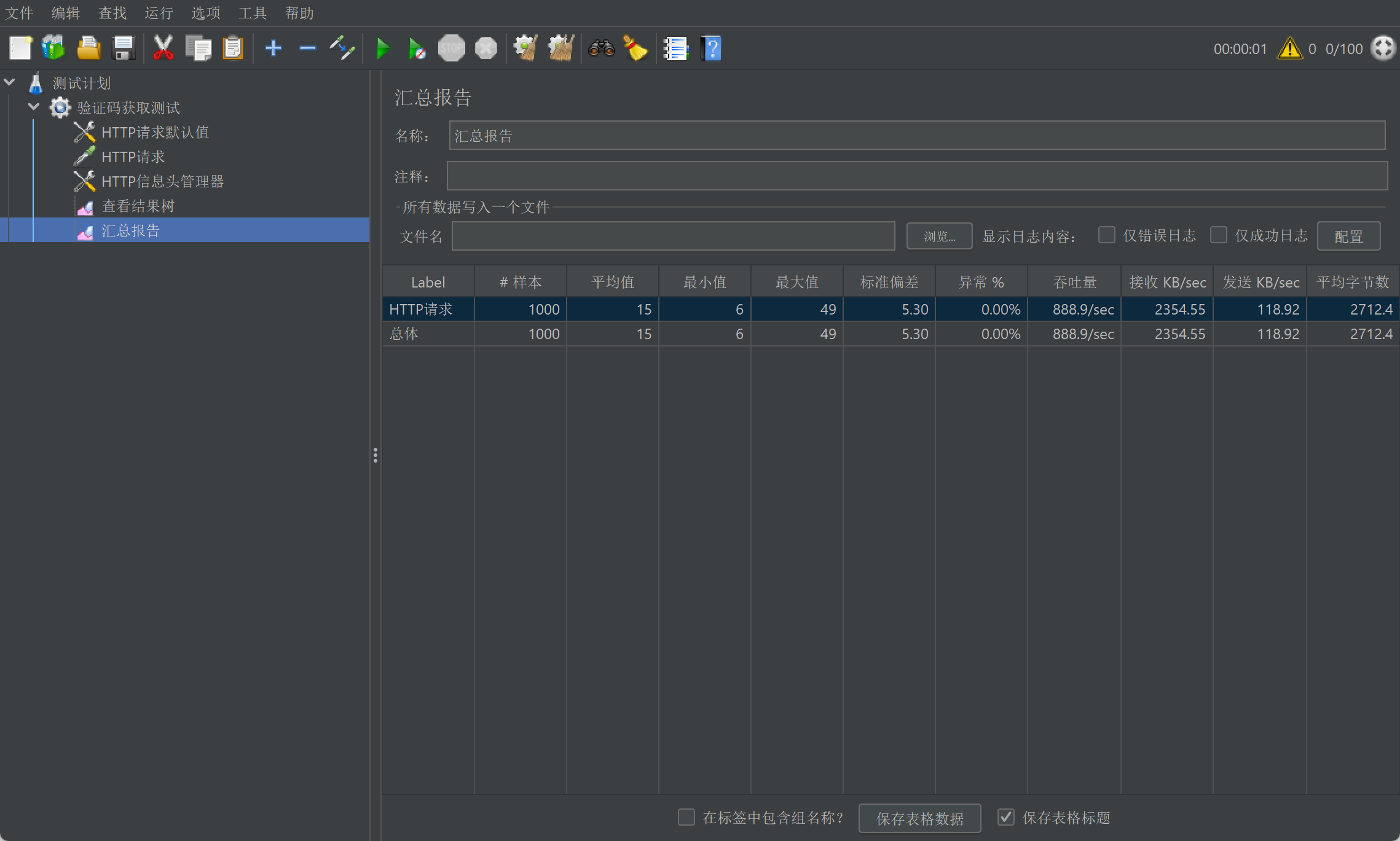
1.5.2.7. 添加报告
右键 【添加】–>【监听器】–>【汇总报告】

参考:
















 178
178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









