







以Cora的链接预测任务为例,
把下面代码换成
# path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', dataset_name)
# dataset = Planetoid(path, name="Cora", transform=transform)
dataset = Planetoid(root="./dataset", name="Cora",transform=transform)
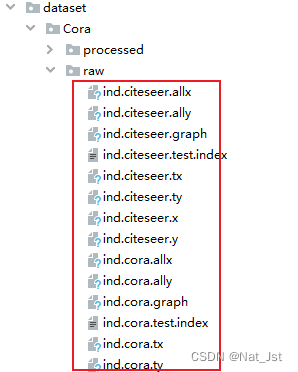
代码同级文件目录:(需要创建以下图片中文件夹)raw中数据从链接下载
完整代码
import os.path as osp
import torch
from sklearn.metrics import roc_auc_score
import torch_geometric.transforms as T
from torch_geometric.datasets import Planetoid
from torch_geometric.nn import GCNConv
from torch_geometric.utils import negative_sampling
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = T.Compose([
T.NormalizeFeatures(),
T.ToDevice(device),
T.RandomLinkSplit(num_val=0.05, num_test=0.1, is_undirected=True,
add_negative_train_samples=False),
])
# path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', dataset_name)
dataset = Planetoid(root="./dataset", name="Cora",transform=transform)
print(dataset)
print(dataset[0])
# dataset = Planetoid(path, name="Cora", transform=transform)
# After applying the `RandomLinkSplit` transform, the data is transformed from
# a data object to a list of tuples (train_data, val_data, test_data), with
# each element representing the corresponding split.
train_data, val_data, test_data = dataset[0]
class Net(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels):
super().__init__()
self.conv1 = GCNConv(in_channels, hidden_channels)
self.conv2 = GCNConv(hidden_channels, out_channels)
def encode(self, x, edge_index):
x = self.conv1(x, edge_index).relu()
return self.conv2(x, edge_index)
def decode(self, z, edge_label_index):
return (z[edge_label_index[0]] * z[edge_label_index[1]]).sum(dim=-1)
def decode_all(self, z):
prob_adj = z @ z.t()
return (prob_adj > 0).nonzero(as_tuple=False).t()
model = Net(dataset.num_features, 128, 64).to(device)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.01)
criterion = torch.nn.BCEWithLogitsLoss()
def train():
model.train()
optimizer.zero_grad()
z = model.encode(train_data.x, train_data.edge_index)
# We perform a new round of negative sampling for every training epoch:
neg_edge_index = negative_sampling(
edge_index=train_data.edge_index, num_nodes=train_data.num_nodes,
num_neg_samples=train_data.edge_label_index.size(1), method='sparse')
edge_label_index = torch.cat(
[train_data.edge_label_index, neg_edge_index],
dim=-1,
)
edge_label = torch.cat([
train_data.edge_label,
train_data.edge_label.new_zeros(neg_edge_index.size(1))
], dim=0)
out = model.decode(z, edge_label_index).view(-1)
loss = criterion(out, edge_label)
loss.backward()
optimizer.step()
return loss
@torch.no_grad()
def test(data):
model.eval()
z = model.encode(data.x, data.edge_index)
out = model.decode(z, data.edge_label_index).view(-1).sigmoid()
return roc_auc_score(data.edge_label.cpu().numpy(), out.cpu().numpy())
best_val_auc = final_test_auc = 0
for epoch in range(1, 101):
loss = train()
val_auc = test(val_data)
test_auc = test(test_data)
if val_auc > best_val_auc:
best_val_auc = val_auc
final_test_auc = test_auc
print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Val: {val_auc:.4f}, '
f'Test: {test_auc:.4f}')
print(f'Final Test: {final_test_auc:.4f}')
z = model.encode(test_data.x, test_data.edge_index)
final_edge_index = model.decode_all(z)














 4022
4022











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









