









文章目录
1. 知识图谱
1.1 无处不在的图结构



在我们现实生活中存在着大量的图结构,图结构能方便准确的建模现实世界,并且描述现实世界中各事物之间的关系,比如,社交网络、分子图、互联网、交通网的神经网络等,在一项任务中,只要有关系分析的需求,知识图谱与图神经网络就“有可能”派的上用场。
1.2 知识图谱介绍
Google为了提升搜索引擎返回的答案质量和用户查询的效率,于2012年5月16日发布了知识图谱(Knowledge Graph)。有知识图谱作为辅助,搜索引擎能够洞察用户查询背后的语义信息,返回更为精准、结构化的信息,更大可能地满足用户的查询需求。Google知识图谱的宣传语“things not strings”给出了知识图谱的精髓,即,不要无意义的字符串,而是获取字符串背后隐含的对象或事物。
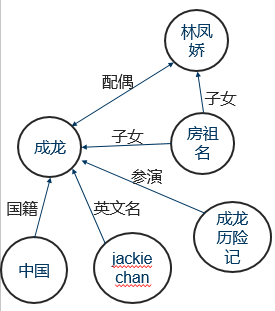
以成龙为例,我们想知道成龙的相关信息(很多情况下,用户的搜索意图可能也是模糊的,在之前的搜索方式,我们只能得到包含这个字符串的相关网页作为返回结果,然后再进入某些网页查找我们感兴趣的信息;现在,除了相关网页,搜索引擎还会返回一个“知识卡片”,包含了查询对象的基本信息和其相关的其他对象,在最短的时间内,我们获取了最为简洁,最为准确的信息。
1.3 知识图谱概念
知识图谱本质它背后的思想可以追溯到上个世纪五六十年代所提出的语义网络(Semantic Network)。
语义网络(Semantic Network):由相互连接的节点和边组成,节点表示概念或者对象,边表示他们之间的关系。
本质上,知识图谱是真实世界中存在的各种实体、概念及其关系构成的语义网络图,用于形式化地描述真实世界中各类事物及其关联关系。
知识图谱在逻辑架构层面可分为模式层和数据层。

模式层:模式层在数据层之上,是知识图谱的核心。主要内容为知识的数据结构,包括实体(Entity)、关系(Relation)、属性(Attribute)等知识类的层次结构和层级关系定义,约束数据层的具体知识形式。
数据层:数据层是以事实(Fact)三元组等知识为单位,存储具体的数据信息。知识图谱一般以三元组 G = { E,R,F }的形式表示。其中,E 表示实体集合{ e1,e2,⋯,e E},实体 e 是知识图谱中最基本的组成元素,指代客观存在并且能够相互区分的事物,可以是具体的人、事、物,也可以是抽象的概念。R 表示关系集合{ r1,r2,⋯,r R},关系 r 是知识图谱中的边,表示不同实体间的某种联系。F表示事实集合{ f1,f2,⋯,f F},每一个事实 f 又被定义为一个三元组(h,r,t) ∈ f。其中,h表示头实体,r表示关系,t 表示尾实体。事实的基本类型可以用三元组表示为(实体,关系,实体 )和(实体,属性,属性值 )等。
1.4 知识图谱构建流程
知识图谱是通过知识抽取(KnowledgeExtraction,KE)、知识融合(Knowledge Fusion,KF)、知识加工(Knowledge Processing,KP)和知识更新(Knowledge Update,KU)等构建技术,从原始数据(包括结构化数据、半结构化数据和非结构化数据)和外部知识库中抽取知识事实。
狭义的知识图谱是真实世界中存在的各种实体、概念及其关系构成的语义网络图,用于形式化地描述真实世界中各类事物及其关联关系,广泛的知识图谱概念是指构建知识图谱的整套流程。

1.4.1 知识抽取
知识抽取是知识图谱构建的首要任务,通过自动化或半自动化的知识抽取技术,从原始数据中获得实体、关系及属性等可用知识单元,为知识图谱的构建提供知识基础。
1.4.2 知识融合
知识融合是融合各个层面的知识,包括融合不同知识库的同一实体、多个不同的知识图谱、多源异构的外部知识等,并确定知识图谱中的等价实例、等价类及等价属性,实现对现有知识图谱的更新。知识融合的主要任务包含实体对齐(Entity Alignment,EA)和实体消歧(EntityDisambiguation,ED)。
实体对齐旨在发现不同知识图谱中表示相同语义的实体。(不同实体指称项表示同一实体)

实体消歧是根据给定文本,消除不同文本中实体指称的歧义(即一词多义问题),将其映射到实际的实体上。
1.4.3 知识加工
知识加工是在知识抽取、知识融合的基础上,对基本的事实进行处理,形成结构化的知识体系和高质量的知识,实现对知 识 的 统 一 管 理 。 知 识 加 工 的 具 体 步 骤 包 括 本 体 构 建(Ontology Construction,QC)、知识推理(Knowledge Reasoning,KR)和质量评估(Quality Evaluation,QE)。

知识推理:知识推理是针对知识图谱中已有事实或关系的不完备性,挖掘或推断出未知或隐含的语义关系。一般而言,知识推理的对象可以为实体、关系、和知识图谱的结构等。


其中链接预测是知识推理的一种。通过知识图谱中已知的节点以及网络结构等信息来预测网络中无边相连的两个节点之间产生链接关系的可能性。
1.4.4 知识更新
知识更新是随着时间的推移或新知识的增加,不断迭代更新知识图谱的内容,保障知识的时效性。
知识更新有模式层更新和数据层更新两种层次,包括全面更新和增量更新两种方式。

1.5 知识图谱应用

参考文献:(里面有更详细的内容)
[1]田玲,张谨川,张晋豪,等. 知识图谱综述——表示、构建、推理与知识超图理论_田玲[J]. 计算机应用, : 1-26.
2. 图神经网络
2.1 图数据与其他数据区别
数据分类:欧几里得数据(欧式数据)与非欧几里得数据(非欧式数据)

欧几里得数据:节点有固定的排列规则和顺序,具有平移不变性。如图片、文字、语音。
它是一类具有很好的平移不变性的数据。对于这类数据以其中一个像素为节点,其邻居节点的数量相同。所以可以很好的定义一个全局共享的卷积核来提取图像中相同的结构
- 图像中的平移不变性:即不管图像中的目标被移动到图片的哪个位置,得到的结果(标签)应该相同的。
- 卷积被定义为不同位置的特征检测器。
图像:图像是一种2D的网格类型数据,通常用矩阵进行存储。
文本:文本是一种1D的网格类型数据,通常可以用向量进行存储。对于文本,我们通常做法是去停用词、以及高频词(DIFT),最后嵌入到一个一维的向量空间。

图像:卷积神经网络
文字、语音:循环神经网络
非欧几里得数据:节点没有固定的排列规则和排序。如:图数据
它是一类不具有平移不变性的数据。这类数据以其中的一个为节点,其邻居节点的数量可能不同。常见这类数据有知识图谱、社交网络、化学分子结构等等。
这类数据由于其不具备平移不变性,不能利用卷积核去提取相同的结构信息,所以卷积神经网络对于这类数据无能为力。所以衍生出了处理这类数据的网络,即图神经网络。
2.2 图数据
欧式数据也可以视为特殊的非欧式数据

首先我们看一下如何把图片表示成图,假如我们有一张图片高宽都是244,然后有RGB 3个通道,一般来说会把它表示成三个维度的tensor,但是从另外一个角度来说我们可以把它当做一个图,它的每一个像素可以当做一个节点,如果一个像素和这个像素是邻接关系的话我们就在它们之间连一条边。
我们来看一下这个图,首先来看一下节点image 0-0 表示的是第0列第0行,对应图上的点是graph 0-0,同样的第1列第一行对应在图上就是1-1这个节点。这样的话把图片上的每一个像素都映射到图上的每一个点。接下来我们来看一下边,把1-1这个像素点,上下左右对角线的像素点都看作它的邻居,那么那么在图上也是有8条边,这就是怎么把一个图片表示成一个图的形式。
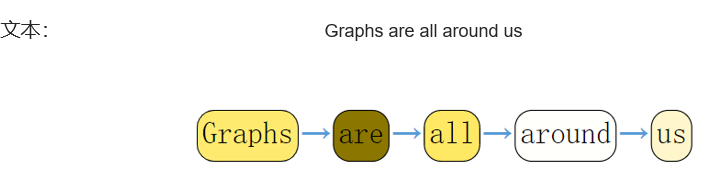
文本可以认为是一条序列,我们可以把每一个词表示成一个顶点,一个词和下一个词之间有一个有向边。
当然,在实践中,文本和图像通常不是这样编码的:这些图形表示是多余的,因为所有图像和所有文本都将具有非常规则的结构。
除了图像和文本能够表示为图之外,现实生活中还有很多别的数据也能表示为图。例如分子图,每一个原子表示成一个节点,每个键表示成一条边。
社交网络:这是空手道俱乐部的交互图,其中包含两位教练与32名学生,这个交互图描述了他们之间交手的情况。

此外还有引用图,如果一篇论文引用另一篇论文的话,就可以引一条边过去。
交通图:把路口当做节点,路口之间的路当做边。
2.3 图
什么是图?
A graph represents the relations (edges) between a collection of entities (nodes).
图表示一组实体(节点)之间的关系(边)。

一个图由节点和边构成。我们不仅关心整个图的架构,还关心每个顶点每条边以和整个图表示的信息。这些信息被称为attitudes属性,那么如何来表示这些属性,用于深度学习?

可以进行embedding用向量来表示这些属性,这些柱状图,它的高矮就表示它的大小,例如一个顶点的属性embedding后用长度为6的向量表示,一条边的属性embedding后用长度为8的向量表示。整个全局的信息embedding后可以用长度为5的向量表示。
图神经网络关注的重点:我们怎么样把我们想要的信息表示成这些向量,以及这些向量能不能通过数据来学到。有了向量表示后就可以解决图上面的问题,也就是图任务。
2.3 图任务
图上的预测任务一般分为三种类型:图级、节点级和边级。
在图级任务中,我们预测整个图的单个属性。 对于节点级任务,我们预测图中每个节点的一些属性。 对于边级任务,我们希望预测图中边的属性或预测边存在。
Graph-level task:在图级任务中,我们的目标是预测整个图的属性。 例如,对于以图表示的分子,我们可能想要预测该分子的气味,或者它是否会与疾病有关的受体结合。下面图片表示输入一些图,在里面识别有哪些图是包含两个环的,有两个环的分子可能会有一些特性,给他识别出来。

这类似于图像分类问题,我们希望将标签与整个图像相匹配。
Node-level task
节点级任务与预测图中每个节点的身份或角色有关。
节点级预测问题的一个典型例子是 Zach 的空手道俱乐部。 该数据集是一个单一的社交网络图, 假如有一天,Hi先生(教练)和John H(管理员)之间的出现争执,导致空手道俱乐部解散。 节点代表单个空手道练习者,边缘代表这些成员交互情况。 给一个学员,预测发生在争执之后该学员继续跟随 Mr. Hi 还是 John A教练。 其中图中蓝色节点表示继续跟谁john A 的可能性大,红色节点继续跟谁MR Hi的可能性大。

知识图谱中实体对齐也属于节点级任务。在两个知识图谱中可能含有表示同一现实对象的节点,通过实体对齐形成一个知识图谱。

Edge-level task
边级推理的一个例子是图像场景理解。 除了识别图像中的对象之外,深度学习模型还可用于预测它们之间的关系。 我们可以将其表述为边级分类:给定表示图像中对象的节点,我们希望预测这些节点中的哪些节点共享一条边或该边的值是什么。 如果我们希望发现实体之间的连接,我们可以考虑完全连接的图,并根据它们的预测值修剪边以得到稀疏图。
通过语义分割将左边的图片分为右边的五部分,分别是裁判、两个选手、观众、垫子,然后下边图片给出了他们之间的关系。

在这里顶点已经有了我们要学习顶点之间边的属性是什么。比如说D选手正在踢J选手,这两个选手都站在垫子上,这些是观众,他们正在看这两个选手在比赛。这些边的属性都要通过预测得到。
也就是说给出左面的原始图,然后去预测图中每个边的属性。

知识图谱中的链接预测也是属于边级别任务。

2.4 图神经网络
那么,我们如何用神经网络来解决这些不同的图任务呢?
我们将神经网络用在图上面最核心的问题是怎么样表示图使得图与神经网络是兼容的。
图上面有四种信息,分别是顶点的属性、边的属性、全局的信息和以及它的连接性,也就是说一条边到底连接哪两个顶点,我们希望使用这些信息进行预测,来完成任务。 前三个相对简单,顶点的属性、边的属性、全局的信息都可以用向量来表示,神经网络对向量是友好的,但是问题是怎么来表示连接性呢?连接性当然可以用邻接矩阵来表示,如果有n个顶点的话那么邻接矩阵就是由n*n的矩阵。其中如果两个顶点有连接的话就是1,否则就是0.

基于空间方法的图神经网络关键思想是利用图上的信息传播机制(消息传递机制),即节点状态不多更新,每一时刻更新都使用了上一时刻相邻节点状态信息。

通过接收、聚合邻居特征信息,来更新当前节点的特征。GNN的每一层都聚合了来自于上一层的信息,从递归的角度看,k层GNN就是汇总了当前节点k跳邻居的信息。因此,可以将GNN模型抽象为一个多层结构(类似RNN展开),其中每一层都包含了所有节点,层与层之间的边就是原图中的边,那GNN就是一个L+1层的网格结构(类似序列标注),第0层是输入层。
每一层消息传递只聚合一阶邻域邻接信息,通过多层消息传递可以聚合多阶邻域信息。

只要层数够多,一个节点就可以聚合所有节点的表示,但是不是层数越多越好,当层数够多时可能会出现过渡平滑的问题,每个节点的表示类似,难以用于分类预测等下游任务。一般2~3层GNN就可以达到比较好的效果。
2.5图卷积神经网络 GCN

GCN 多层图卷积神经网络逐层传播规则:
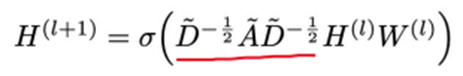
H(l) 当前层节点的特征,W(l) 要学习的参数,如果不看前面这一项的话就是一个全连接层,A~表示图的邻接矩阵A+单位矩阵I,也就是给每个节点加上自环之后的邻接矩阵
D~表示每个节点加上自环之后的度矩阵,矩阵中对角线的值为邻接矩阵每行相加。
前面这个化红线的公式矩阵相乘的结果表示图上面的转换,在每一层都会乘这个矩阵,这个值是固定不变的,求得了前面这个公式之后,乘以这个节点本层的特征,再乘一个节点的权重,权重是可学习的参数,就学习了这个节点在下一层的特征表示。这就是GCN的方法
GCN公式只使用邻接矩阵A的话,由于A的对角线上都是0,所以在和特征矩阵H相乘的时候,只会计算一个node的所有邻居的特征的加权和,该node自己的特征却被忽略了。因此,我们可以做一个小小的改动,给邻接矩阵A加上一个单位矩阵 I 得到A~ ,这样就让对角线元素变成1了。A是没有经过归一化的矩阵,这样与特征矩阵相乘会改变特征原本的分布,产生一些不可预测的问题。所以我们对A做一个标准化处理。首先让A的每一行加起来为1,我们可以乘以一个D的逆,D就是度矩阵。我们可以进一步把D的拆开与A相乘,得到一个对称且归一化的矩阵 。



然后来看一下这个公式表达了什么意思,度矩阵的操作是归一化的操作,先不看这个度矩阵,只看AHW,AH矩阵相乘之后,聚合了邻居节点的特征,1节点的特征=周围2,3节点特征相加。A加了单位矩阵成A之后,AH相乘之后聚合的不仅是邻居节点的信息还包含了自己本身的信息,对于度大的节点聚合之后特征越来越大,而对于度小的节点却相反,这可能导致网络训练过程中梯度爆炸或者消失的问题。,就需要对节点特征进行归一化操作,左右分别乘D~ -1/2。
 当使用这种归一化矩阵,在对A这个节点的特征进行更新时,B占的权重会更大,C占的权重会更小。因为B对A产生影响,与A对B产生对影响是一样的(无向图),由于B只有A这个邻居,所以A对B影响很大;同样地,C对A产生影响,与A对C产生对影响是一样的,因为C有很多节点,所以A对C节点对影响没那么大,即C对A节点对影响没那么大。
当使用这种归一化矩阵,在对A这个节点的特征进行更新时,B占的权重会更大,C占的权重会更小。因为B对A产生影响,与A对B产生对影响是一样的(无向图),由于B只有A这个邻居,所以A对B影响很大;同样地,C对A产生影响,与A对C产生对影响是一样的,因为C有很多节点,所以A对C节点对影响没那么大,即C对A节点对影响没那么大。

GCN操作:左边是输入的原始图,节点特征向量维数为C,经过一层GCN后得到节点特征向量维数为C的输出图,输入输出图结构一样、没有发生改变,最终将输出F维的特征进行softmax操作,就得到每一个节点所属的类别,公式9 中经过了两层GCN操作此时A矩阵是归一化之后的矩阵,A * 节点本身的特征,输入的特性X ,* 学习的参数W,经过一个ReLu 的激活层,就算出了经过一层GCN之后的节点特征表示,然后经过第二次GCN ,就算出了最终一个节点它的特征最终为了预测一个节点所属的类别,经过一个softmax函数就得到了,节点所属的类别,这时候再经过一些反向传播就学习了每一层GCN学习的参数W。这是最后一层的维度是最终输出的类别数,还有一种是最后一层的维度不等于最终输出的类别数,再经过一个全连接层,把GCN当做特征提取器,然后将GCN最后一层输出的节点的特征再经过一个全连接层进行分类。
图注意力网络GAT

图注意力网络(graph attention networks,GAT).在传统的GNN 框架中,加入了注意力层,从而可以学习出各个邻居节点的不同权重,将其区别对待.进而在聚合邻居节点的过程中只关注那些作用比较大的节点,而忽视一些作用较小的节点,求节点I 与周围节点的注意力系数,再用注意力系数对该节点的邻居节点进行加权求和,就求得了该节点聚合邻接节点之后的特征。算法流程 ,其中aij 表示节点 j 相对于节点i的注意力因子,W 是一个用于降维的仿射变换,是可学习得到的,aT表示权重向量参数,是可学习得到的,||表示向量的拼接操作,然后加上非线性激活函数d ,利用学习到的注意力因子ai j 就可以实现对中心节点i 的更新:
计算例子:


为了使模型更加稳定,作者还应用了多头注意力机制.在计算j节点对i节点的注意力因子的时候,不仅仅考虑一次注意力因子,而是计算多个注意力因子,来更好的学习j节点对i节点的注意力因子。如图中使用了3个 多头注意力机制,这样就分别学习了3个1节点与邻居节点聚合之后的表示,公式:首先计算多头的注意力机制,然后每一个注意力机制都学习到节点的特征,最后将多头注意力机制学习到的节点的特征拼接到一起当做这个节点最终的特征表示。在最后一层注意力机制 就没有必要将这三个注意力机制得到的特征向量拼接,而是求三个向量的平均。为什么求平均而不是拼在一起呢?是因为对于最后一个卷积层,如果利用多头注意力机制进行求解,则要利用求平均的方式来求解:,也就是说如果在最后有一个softmax层要利用求平均的方式来求解,softmax层意义:学习到每一个节点最终的特征都对应一个类别,图中多头注意力机制学习到一个节点的三个特征向量,如果将这三个特征向量拼接起来用sofmax的话不能很好表示每一个特征向量所对应的类别是什么样的,如果最后不是softmax而是全连接层的话就可以将这三个特征向量拼接在一起,把它当做一个特征,在经过分类器最终输出节点所属的类别。
3.图神经网络在知识图谱中应用
节点分类:对论文进行分类。

数据集及代码
参考资料:
















 909
909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









