











🌺系列文章推荐🌺
扩散模型系列文章正在持续的更新,更新节奏如下,先更新SD模型讲解,再更新相关的微调方法文章,敬请期待!!!(本文及其之前的文章均已更新)
🌈历史文章🌈:
SD模型原理:
- Stable Diffusion概要讲解
- Stable diffusion详细讲解
- Stable Diffusion的加噪和去噪详解
- Diffusion Model
- Stable Diffusion核心网络结构——VAE
- Stable Diffusion核心网络结构——CLIP Text Encoder
- Stable Diffusion核心网络结构——U-Net
- Stable Diffusion中U-Net的前世今生与核心知识
- SD模型性能测评
- Stable Diffusion经典应用场景
- SDXL的优化工作
- DiT(Diffusion Transformer)详解
- Stable Diffusion 3详解
- FLUX.1概要——原SD核心团队推出的最强文生图
微调方法原理:

目录
摘录于:https://zhuanlan.zhihu.com/p/684068402
论文:未公开
项目地址:GitHub - black-forest-labs/flux: Official inference repo for FLUX.1 models
在2024年8月1号,由Stable Diffusion系列模型前核心团队重新组建的Black Forest Labs(黑森林实验室)带着迄今为止最大的开源文生图大模型FLUX.1王者归来。FLUX.1一共有12B的参数量,具备强劲的图像生成能力。FLUX.1系列模型基于Stable Diffusion 3架构上进行了优化升级
模型初识
当前FLUX.1系列一共包含了三个变体模型:
- FLUX.1-pro:FLUX.1系列的最强模型,只能通过API和官方平台在线使用。
- FLUX.1-dev:在FLUX.1-pro基础上进行指引蒸馏(guidance-distilled)后的模型,图像生成的质量与文本一致性与FLUX.1 -pro非常接近,同时推理效率比FLUX.1 -pro更高。
- FLUX.1-schnell:为个人开发者和应用者(ToD)发布的本系列推理速度最快的模型。FLUX.1-schnell是基于指引蒸馏(guidance-distilled)和时间步蒸馏(TimeStep-distilled)双重蒸馏后的模型,仅需1-4步就可以能完成图像的生成过程,代价是无法设置图像生成过程的Classifier-Free Guidance强度。
指引蒸馏(Guidance-distilled)的目标是让AI绘画模型直接学习 Classifier-Free Guidance (CFG) 的生成结果,使得AI绘画模型一次输出之前要运行两次才能得到的指引生成结果,从而能够节约近一半的推理耗时。
时间步蒸馏(TimeStep-distilled)通过【引入时间步映射函数】加速蒸馏手段,在FLUX-pro基础上蒸馏得到的模型,从而能在极少的采样步数(1-4步)里完成图像的生成过程。
指引蒸馏(Guidance-Distilled)
CFG详细介绍参考:Stable Diffusion 3详解_stable diffusion 3 系列原理-CSDN博客
背景:Classifier-Free Guidance (CFG)
- CFG 是扩散模型中一种增强生成质量的技术:
- 模型在推理时会运行两次:
- 无条件生成:生成不带文本指导的预测。
- 条件生成:生成带文本指导的预测。
- 最终输出通过将无条件和条件预测加权组合(使用 CFG 强度 λ )得到:

:最终指导噪声预测。
:无条件噪声预测。
:条件噪声预测。
- CFG 提高了文本一致性,但代价是推理时需要额外计算一次无条件预测。
指引蒸馏的目标
- 目标:通过蒸馏技术,让模型直接学习带 CFG 指引的生成结果,从而避免在推理时重复运行两次生成过程。
实现方法
- 蒸馏数据准备:
- 使用 FLUX.1-pro 模型的 CFG 推理结果作为蒸馏数据。
- 输入数据包括:
- 条件输入(文本或图像条件)。
- 模型生成的最终输出(带 CFG 指引)。
- 训练新模型:
- 将原始扩散模型的生成任务调整为直接输出带 CFG 指引的结果。
- 新模型不再需要单独计算无条件和条件结果。
- 优化目标:
- 使用监督学习,使蒸馏模型尽可能拟合带 CFG 的生成结果。
效果
- 推理效率:直接输出带 CFG 指引的结果,避免重复运行,节省接近一半的推理耗时。
- 保持性能:由于蒸馏过程精确模拟了原始 CFG 生成的结果,生成质量与一致性接近 Pro 模型。
时间步蒸馏(TimeStep-Distilled)
背景:扩散模型的时间步数
- 扩散模型(如 DDPM 或 DDIM)在生成图像时需要逐步去噪:
- 每一步对噪声进行小幅调整,逐渐恢复原始图像。
- 标准扩散模型通常需要 50-100 步才能生成高质量图像。
- 问题:
- 每一步采样都需要计算生成结果,推理时间较长。
- 如果时间步数减少,会显著降低生成质量。
时间步蒸馏的目标
- 目标:通过蒸馏技术,将生成过程压缩到极少的时间步(1-4 步),同时尽可能保留生成质量。
实现方法
- 高质量生成参考:
- 使用 FLUX.1-pro 模型在完整时间步数(如 50 步)的生成结果作为高质量参考。
- 加速蒸馏:
- 将生成过程压缩到更少的时间步:
- 从原始的 50-100 步压缩到 1-4 步。
- 使用时间步数较少的采样网络直接预测最终生成结果。
- 通过引入时间步映射函数(Time Mapping),使得模型在少数时间步内完成从纯噪声到清晰图像的转换:
时间步映射函数 f(t) 定义为:
其中:
t 是原始扩散过程中的时间步。
t' 是映射后的时间步。
T 是完整扩散过程的总步数(如 100 步)。
T' 是压缩后的时间步数(如 1-4 步)。
f(t)可以是线性映射、线性映射、线性映射等。
- 损失函数:
- 使用标准扩散损失函数,结合多尺度对比损失,确保蒸馏后的模型能够准确生成与高时间步参考一致的结果。
效果
- 推理效率:将生成过程压缩到 1-4 步,大幅减少推理时间。
- 生成质量:
- 蒸馏后的模型保持高质量输出。
- 尽管质量可能略逊于完整时间步数生成的结果,但对于需要快速生成的场景(如实时交互应用),该策略尤为高效。
FLUX.1系列模型的三个版本对比如下所示:
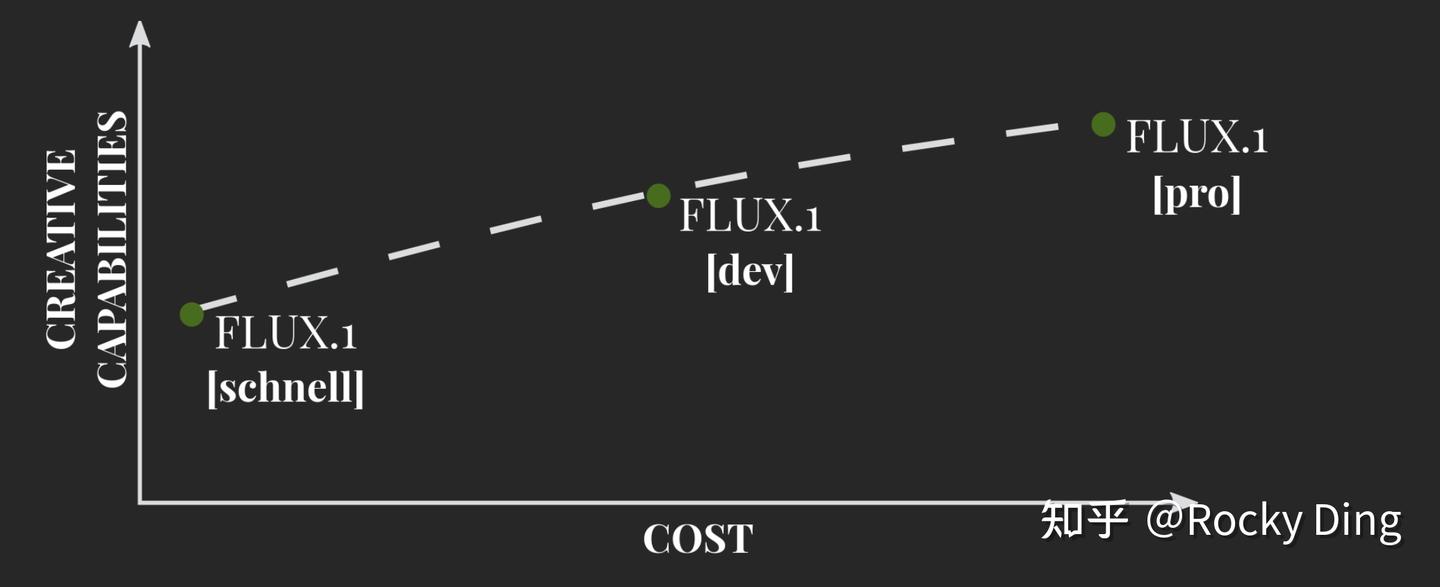
从上图可以看到,FLUX.1-pro版本是生成创造力最强的一个版本,同时所需的成本(包括计算资源、运行时间等)也最高。
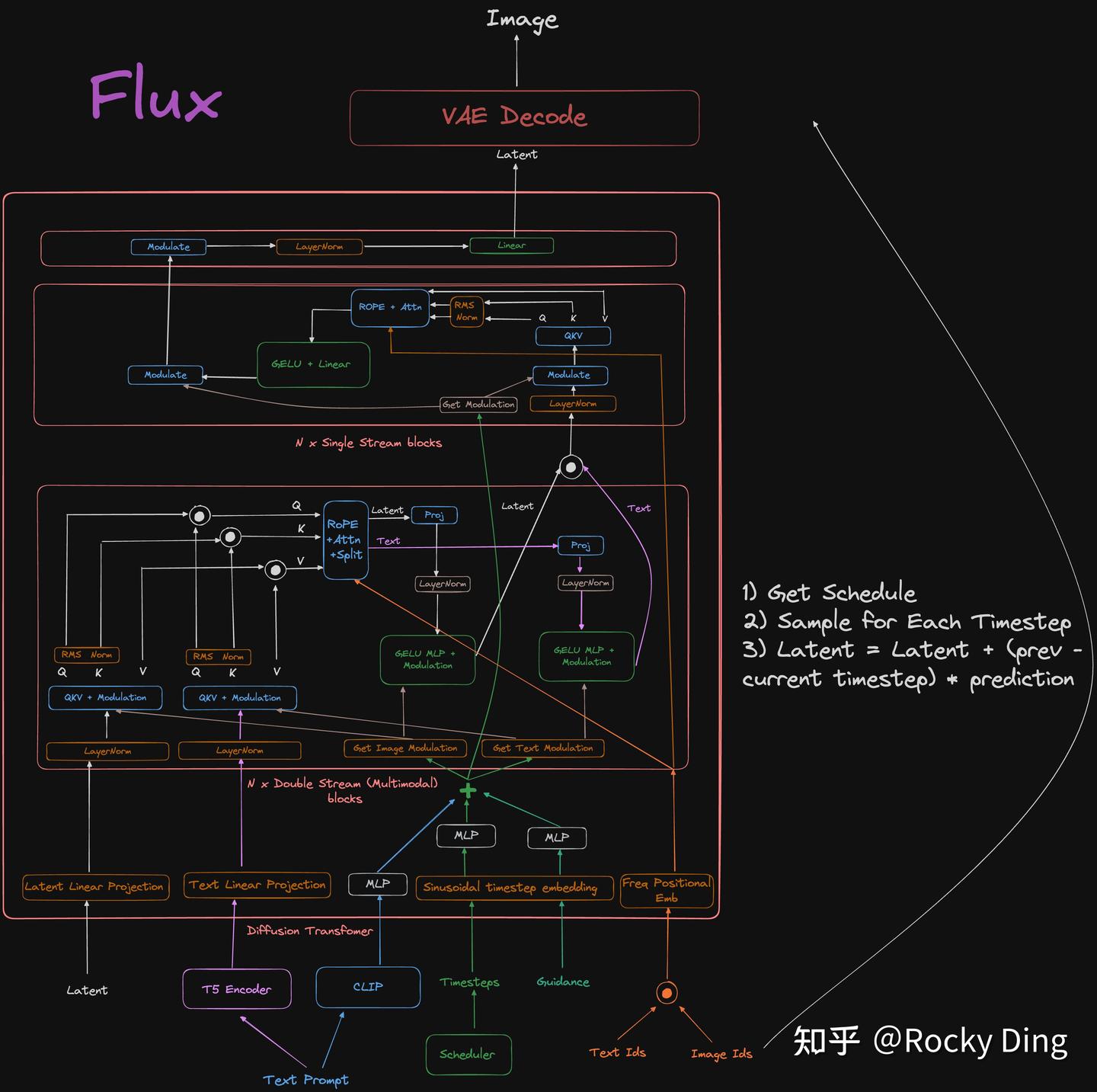
FLUX.1系列的扩散模型部分是基于Stable Diffusion 3的MM-DiT架构和自主设计的Single-DiT架构进行组合,参数量直接scale up至120亿,可以说在模型工程上进行了大大阔斧的改进。同时FLUX.1和Stable Diffusion 3一样,也是根据Rectified Flow采样进行推导的扩散模型。
除此之外,FLUX.1系列模型还引入了NLP领域经典的旋转式位置编码 (RoPE) 技术和并行注意力机制【将 多头自注意力(Multi-Head Self-Attention, MHSA) 和 多层感知机(MLP) 并行处理,下文会详细介绍】等技术,来提升图像生成的整体性能。
下面是FLUX.1系列模型的完整网络架构示意图:
VAE结构
SD 3模型通过提升VAE架构的通道数(16)来增强VAE的重建能力,进而提高重建后的图像整体质量。FLUX.1系列中,FLUX.1 VAE架构依然继承了SD 3 VAE的8倍下采样和【latten 2 × 2 patches,以及】输入通道数(d=16)。
通道堆叠Pack_Latents
在FLUX.1 VAE输出Latent特征,并在Latent特征输入扩散模型前,还进行了Pack_Latents操作,一下子将Latent特征通道数提高到64(16 -> 64),换句话说,FLUX.1系列的扩散模型部分输入通道数为64,是SD3的四倍。这也代表FLUX.1要学习拟合的内容比起SD 3也增加了4倍,所以官方大幅增加FLUX.1模型的参数量级来提升模型容量(model capacity)。
【TODO:为什么是4倍?可能是2x2的原因?目前未知】
下面是Pack_Latents操作的详细代码,让大家能够更好的了解其中的含义:
@staticmethod def _pack_latents(latents, batch_size, num_channels_latents, height, width): latents = latents.view(batch_size, num_channels_latents, height // 2, 2, width // 2, 2) latents = latents.permute(0, 2, 4, 1, 3, 5) latents = latents.reshape(batch_size, (height // 2) * (width // 2), num_channels_latents * 4) return latentsFLUX.1模型的Latent特征Patch化方法是将2×2像素块直接在通道维度上堆叠 。这种做法保留了每个像素块的原始分辨率,只是将它们从空间维度移动到了通道维度。
而SD 3使用下采样卷积来实现Latent特征Patch化,但这种方式会通过卷积减少空间分辨率从而损失一定的特征信息。
例子来解释SD 3和FLUX.1的Patch化方法的不同:
- SD 3(下采样卷积):想象我们有一个大蛋糕,SD 3的方法就像用一个方形模具,从蛋糕上切出一个2×2的小方块。在这个过程中,我们提取了蛋糕的部分信息,但是由于进行了压缩,Patch块的大小变小了,信息会有所丢失。
- FLUX.1(通道堆叠):FLUX.1 的方法更像是直接把【整个】蛋糕的2×2块堆叠起来,不进行任何压缩或者切割【,全部的蛋糕块,叠起来】。我们仍然保留了蛋糕的所有部分,但是它们不再分布在平面上,而是被一层层堆叠起来,像是三明治的层次。这样一来,蛋糕块的大小没有改变,只是它们的空间位置被重新组织了。
总的来说,相比SD 3,FLUX.1将 2×2 特征Patch化操作应用于扩散模型【DiT】之前。这也表明FLUX.1系列模型认可了SD 3做出的贡献,并进行了继承与优化。
【
- FLUX.1 直接将每个 2×2 的像素块堆叠到通道维度。空间分辨率保持不变,原始像素信息完整保留。
- SD 3 会使用设置步长为 2×2 的卷积核下采样将特征图的。空间分辨率 减半,同时在通道维度对信息进行整合。
】
目前发布的FLUX.1-dev和FLUX.1-schnell两个版本的VAE结构是完全一致的。同时与SD 3相比,FLUX.1 VAE并不是直接沿用SD 3的VAE,而是基于相同结构进行了重新训练,两者的参数权重是不一样的。并且SD 3和FLUX.1的VAE会对编码后的Latent特征做平移和缩放,而之前的SD系列中VAE仅做缩放:
def encode(self, x: Tensor) -> Tensor:
z = self.reg(self.encoder(x))
z = self.scale_factor * (z - self.shift_factor)
return z平移和缩放操作能将Latent特征分布的均值和方差归一化到0和1,和扩散过程加的高斯噪声在同一范围内,更加严谨和合理。
| 特性 | SD 3 和 FLUX.1 的 VAE | 之前 SD 系列的 VAE |
|---|---|---|
| 处理方式 | 平移 + 缩放(Shift & Scale) | 仅缩放(Scale) |
| 特征分布 | 分布中心可以动态调整 | 分布中心固定在零 |
| 灵活性 | 更高,允许特征空间的非对称性 | 较低,特征空间受限 |
| 高分辨率生成 | 对细节捕捉能力更强 | 细节捕捉能力有限 |
| 潜在特征表达能力 | 丰富、灵活 | 单一、受限 |
FLUX.1-dev/schnell系列模型的VAE完整结构图如下:
【结构上与SD和SDXL并未有差别,更详细信息参考:Stable Diffusion核心网络结构——VAE_stable diffusion网络架构-CSDN博客】
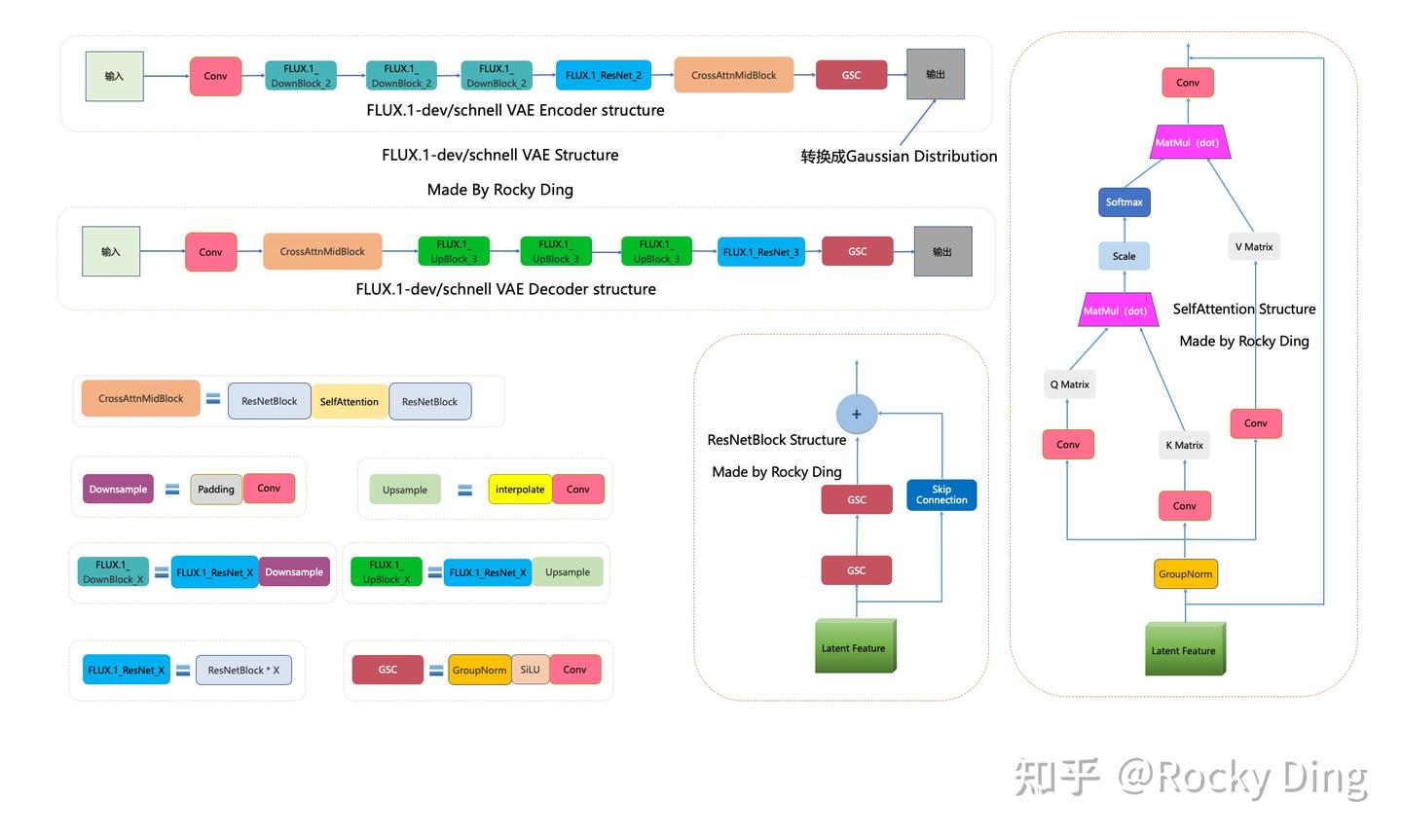
FLUX.1 VAE架构和SD 3 VAE架构一致。
可以看到,SD 3 VAE模型中有三个基础组件:
- GSC组件:GroupNorm+SiLU+Conv
- Downsample组件:Padding+Conv
- Upsample组件:Interpolate+Conv
同时SD 3 VAE模型还有两个核心组件:ResNetBlock模块和SelfAttention模块,两个模块的结构都已在上图中展示。
SD 3 VAE Encoder部分包含了三个DownBlock模块、一个ResNetBlock模块以及一个MidBlock模块,将输入图像压缩到Latent空间,转换成为Gaussian Distribution。
而VAE Decoder部分正好相反,其输入Latent特征,并重建成为像素级图像作为输出。其包含了三个UpBlock模块、一个ResNetBlock模块以及一个MidBlock模块。
SDXL VAE在压缩和重建过程中出现图像内容和文本的畸变,而SD 3 VAE和FLUX.1 VAE基本看不到明显的重建畸变。
MM-DiT和Single-DiT结构
FLUX.1的Transformer模型中和SD 3一样有MM-DiT模块(双流DiT),同时也包含Single-DiT模块(单流DiT)。在单流DiT Block模块中,文本信息和图像信息融合在一起,再送入Attention机制中【早期融合】。
FLUX.1-dev/schnell系列模型MM-Single-DiT的完整结构图如下:
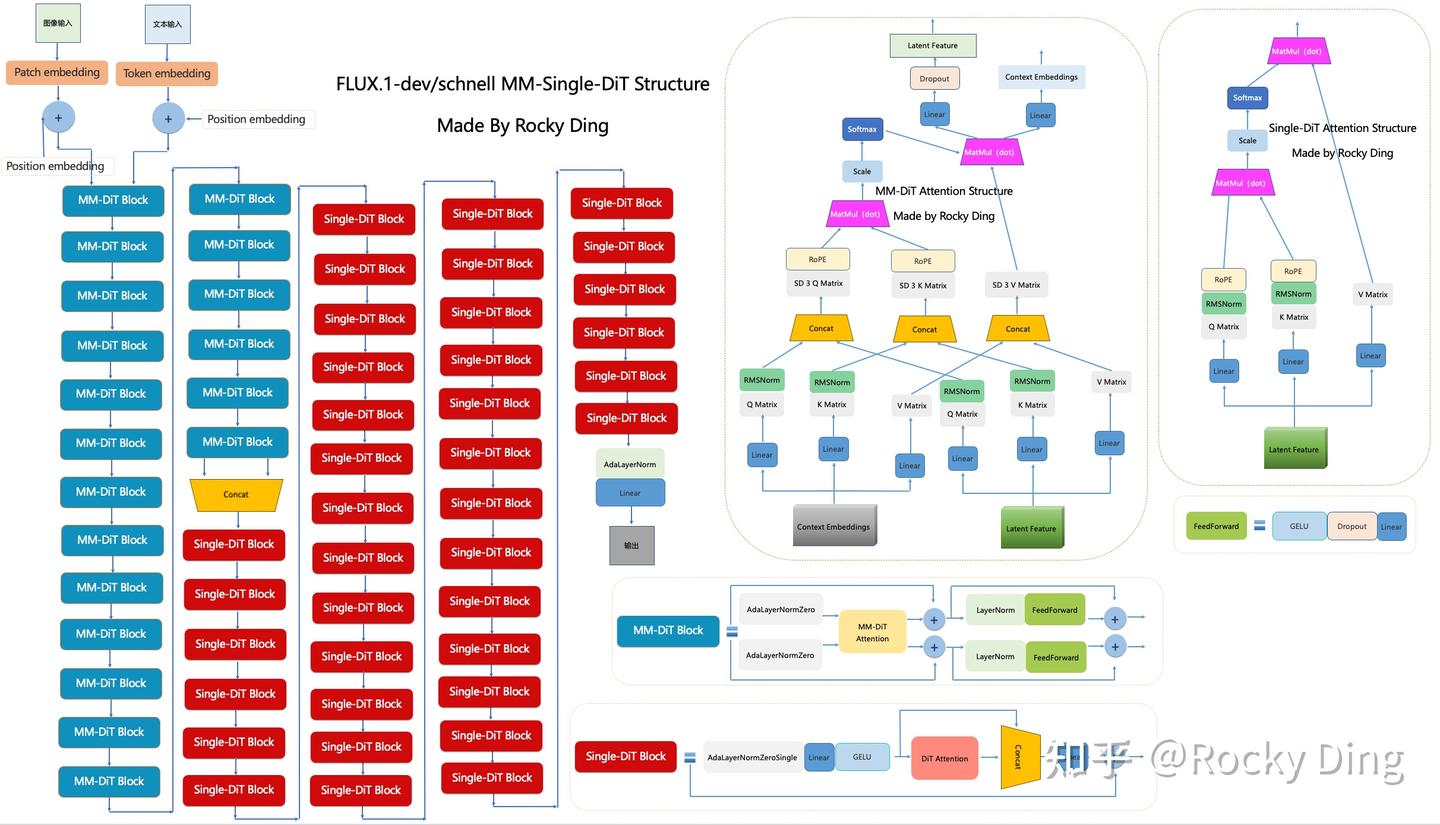
可以看到,FLUX.1系列中MM-Single-DiT架构包含了19层MM-DiT Block结构【SD 3🈶️24层MM-DiT】和38层Single-DiT Block结构。
除此之外,FLUX.1的Transformer模型中还在Single-DiT(单流DiT)部分用到了并行注意力机制(parallel Attention-MLP Blocks),具体的优化方式如下所示:
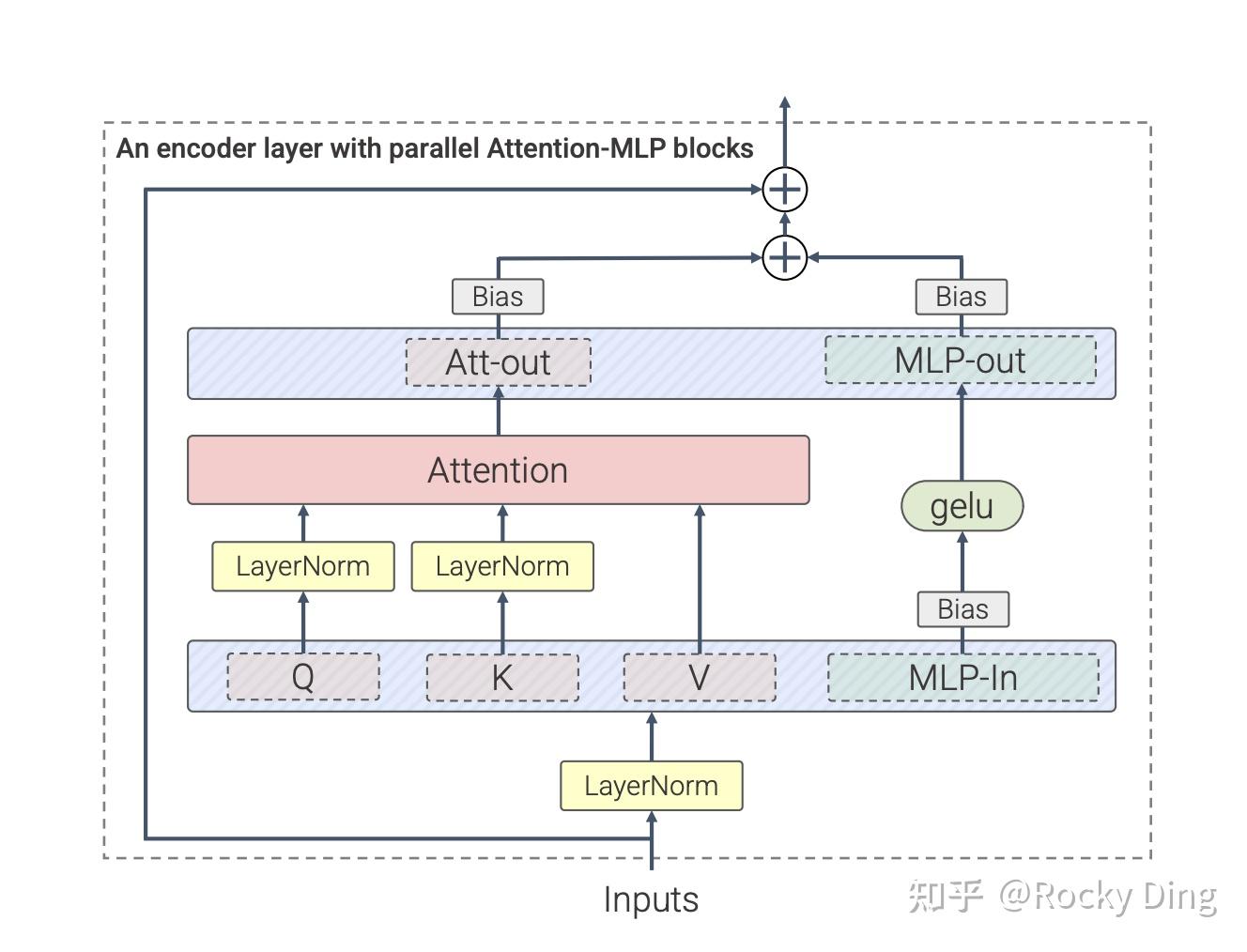
可以看到,并行注意力机制把注意力和线性层之间的串联结构转变成并联结构。常规注意力机制需要在计算注意力的前后各经过一次线性层的特征提取,在转换成并联结构后,注意力在计算完成后与MLP进行了add操作,将特征融合。这样一来,整体的计算并行度更高,AI绘画模型的运行效率也随之提升了。
Text Encoder结构
Stable Diffusion 3的Text Encoder部分,一共使用了CLIP ViT-L、OpenCLIP ViT-bigG、T5-XXL Encoder三个Text Encoder模型。
FLUX.1只使用了CLIP ViT-L和T5-XXL Encoder两个Text Encoder模型。【SDXL只使用了CLIP ViT-L、OpenCLIP ViT-bigG】
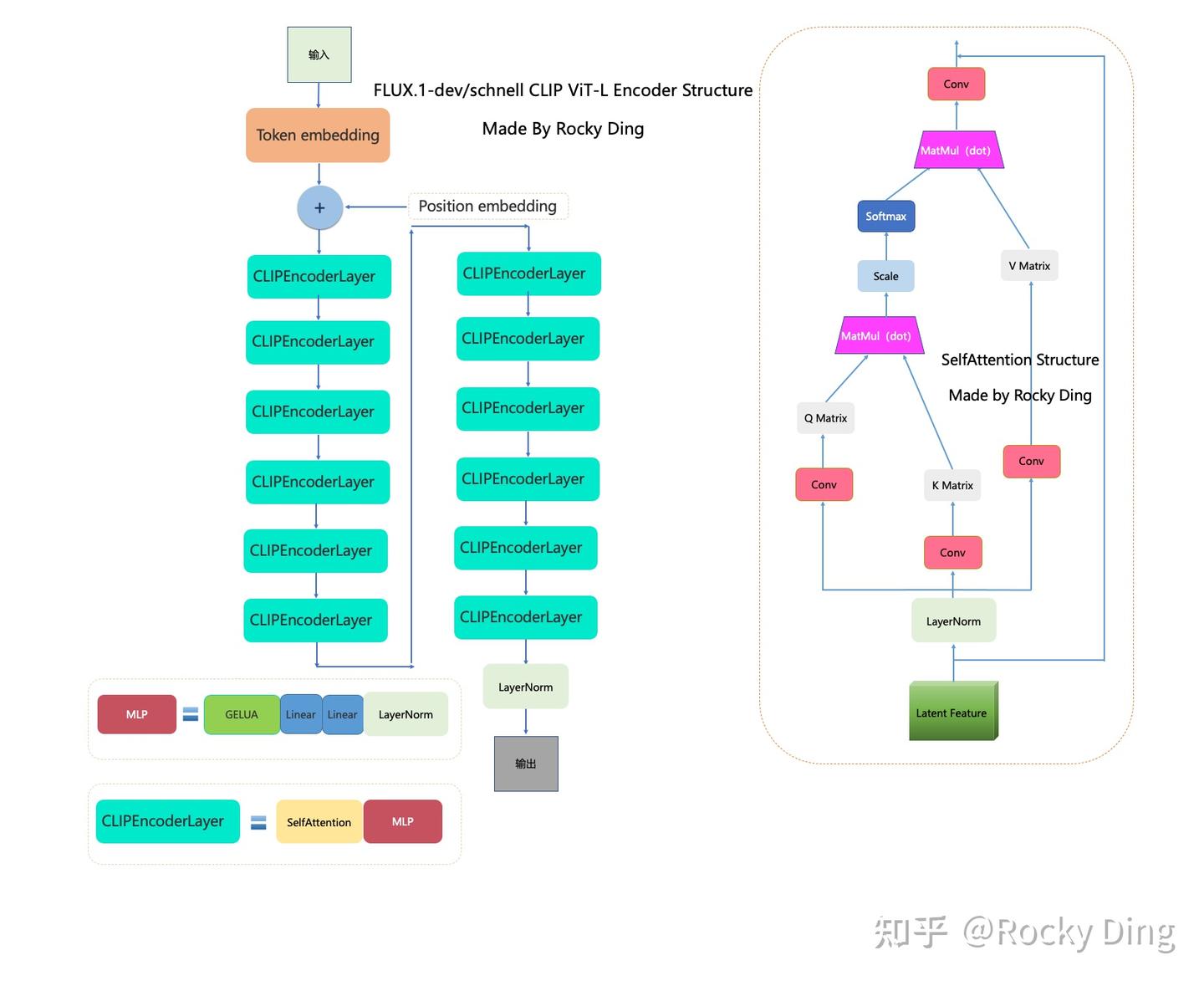
CLIP ViT-L Text Encoder的完整结构图如下:
【同SD3和SD1.5】
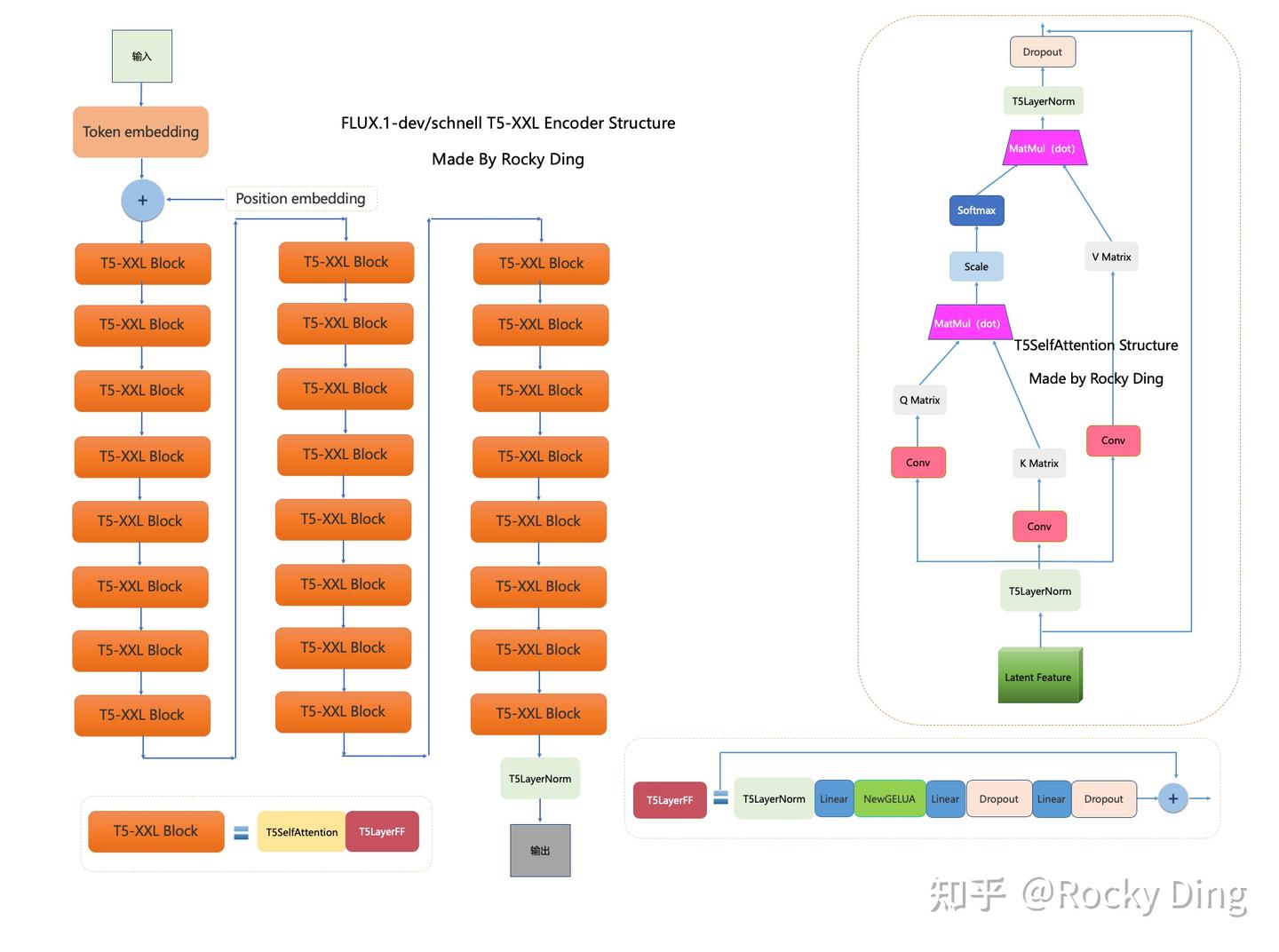
T5-XXL Encoder的完整结构图如下:
【同SD3】
FLUX.1中将文本的位置编号设为(0, 0, 0),图像的位置编号设为(0, i, j),之后用标准的旋转式位置编码对三个维度的编号编码,再把三组编码拼接。第一个是维度是为视频生成的time维度预留,后续Black Forest Labs很有可能发布AI视频大模型【官网显示next步骤是视频大模型,且在招募视频生成相关研究员,如下图:】。
【旋转式位置编码RoPE请参考:深度学习——3种常见的Transformer位置编码】



















 2595
2595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









