







SVM的本质:
对数据进行分类。
如图1场景,在这个二维空间中,怎么样才算是比较好的数据分类情况呢?
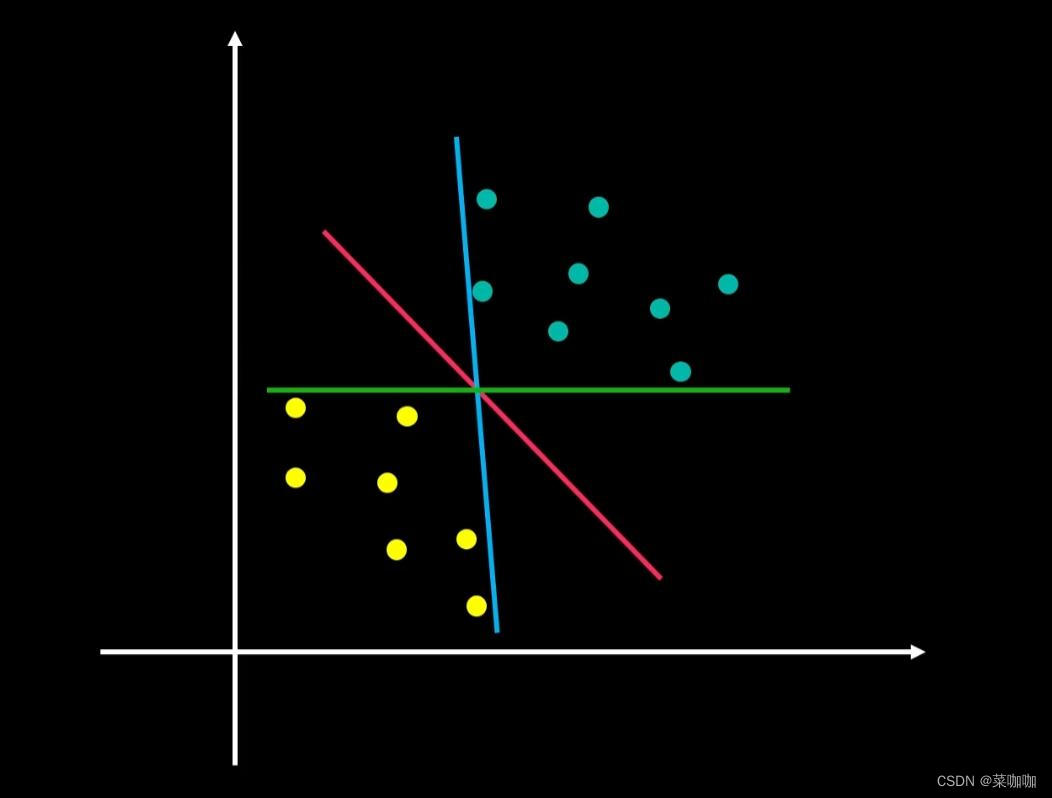
图1
毫无疑问,应该是红色实线是较为理想的分类方式。试想在蓝色和绿色分类的情况下,如果现在新进来一个数据,靠近边界线,那么这个数据被错误分类的可能性会非常大,但是如果是红线分类的情况下,就会有一个相对较大的缓冲区(也被称为margin),也可以理解为容错区域。如图2所示。
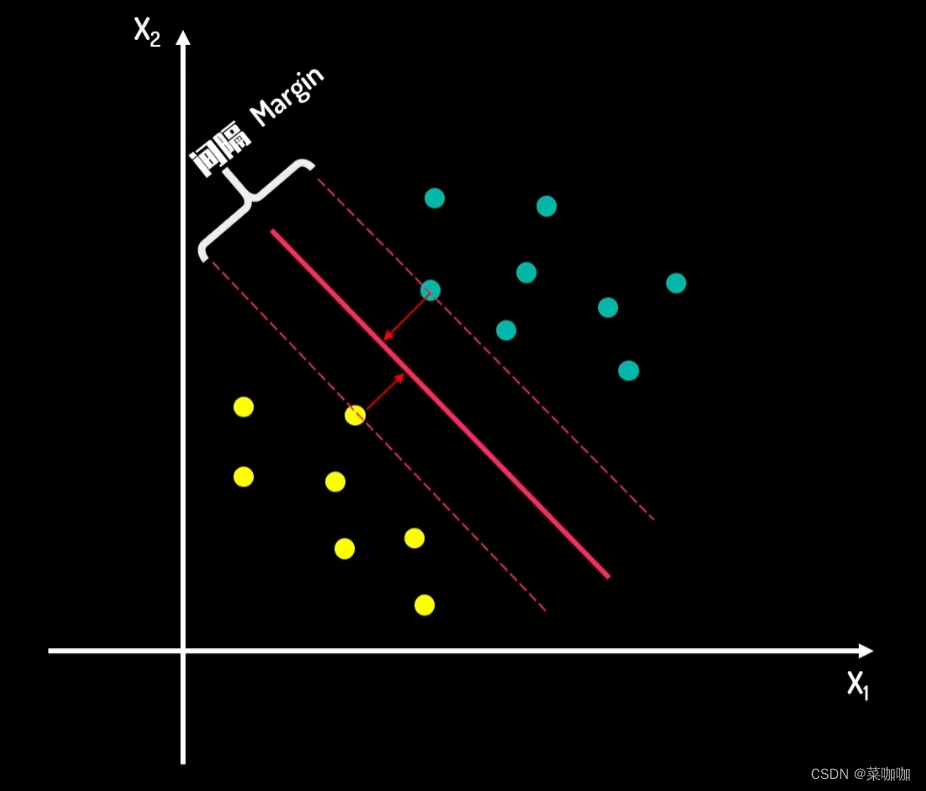
这个间隔会将两类数据所处的空间分隔开,这个间隔可以体现两类数据的差异大小。因此寻找最佳决策边界的问题可以转化为寻找最大间隔的问题,而间隔的正中就是决策边界。假设决策边界的超平面方程式如下所示,那么将他上下分别移动c来到间隔上下边界,由于上下边界一定会经过一些样本数据点,这些点距离决策边界最近,所以决定了间隔距离,则称这些数据点为支持向量(support vector)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1207
1207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









